dlmalloc是目前一个十分流行的内存分配器,其由Doug Lea(主页为http://gee.cs.oswego.edu/)从1987年开始编写,到目前为止,最新版本为2.8.3(可以从ftp://g.oswego.edu/pub/misc/malloc.c获取),由于其高效率等特点被广泛的使用(比如一些linux系统等用的就是dlmalloc或其变形,比如ptmalloc,主页为http://www.malloc.de/en/index.html)和研究(各位可以搜索关键字“GCspy”)。
dlmalloc的实现只有一个源文件(还有一个头文件),大概5000行,其内注释占了大量篇幅,由于有这么多注释存在的情况下,表面上看上去很容易懂,的确如此,在不追求细节的情况,对其大致思想的确很容易了解(没错,就只是了解而已),但是dlmalloc作为一个高品质的佳作,实现上使用了非常多的技巧,在实现细节上不花费一定的精力是没有办法深入理解其为什么这么做,这么做的好处在哪,只有当真正读懂后回味起来才发现它是如此美妙。
lenky0401个人博客将陆续推出对dlmalloc的解析(针对Doug Lea Malloc的最新版Version 2.8.3,未做说明的情况下以32位平台,8字节对齐作为假定平台环境设置考虑),由于个人水平有限,因此也不能完全保证对dlmalloc的所有理解都准备无误, 但是所有内容均出自个人的理解而并非存心妄自揣测来愚人耳目,所以如果读者发现其中有什么错误,请勿见怪,如果可以则请来信告之,并欢迎来信讨论(lenky0401@163.com)。
描述的内容不会包含dlmalloc全部代码,但会将这其中涉及到的一些技巧尽量讲出,我相信对dlmalloc源代码不感兴趣的朋友也可以学到这些独立的技巧而使用在自己的编程实践中。
===========================================================
Dlmalloc将内存分成很多块,并且采用所谓的边界标记法对内存进行管理,在Dlmalloc的实现源码中定义了两种结构体malloc_chunk和malloc_tree_chunk,从它们的定义中可以看到结构体malloc_tree_chunk除了比malloc_chunk多三个字段以外,前四个字段和malloc_chunk完全一样。这两种结构体主要用于对内存块按大小进行不同的管理。
struct malloc_chunk {
size_t prev_foot; /* Size of previous chunk (if free). */
size_t head; /* Size and inuse bits. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
};
typedef struct malloc_chunk mchunk;
typedef struct malloc_chunk* mchunkptr;
typedef struct malloc_chunk* sbinptr; /* The type of bins of chunks */
struct malloc_tree_chunk {
/* The first four fields must be compatible with malloc_chunk */
size_t prev_foot;
size_t head;
struct malloc_tree_chunk* fd;
struct malloc_tree_chunk* bk;
struct malloc_tree_chunk* child[2];
struct malloc_tree_chunk* parent;
bindex_t index;
};
我们先来看看只考虑使用结构体malloc_chunk管理内存的情况(内存都被分为小块,32位机器上即是256字节以下,而对于结构体malloc_tree_chunk,其管理的是大块,32位机器上即是256字节以上):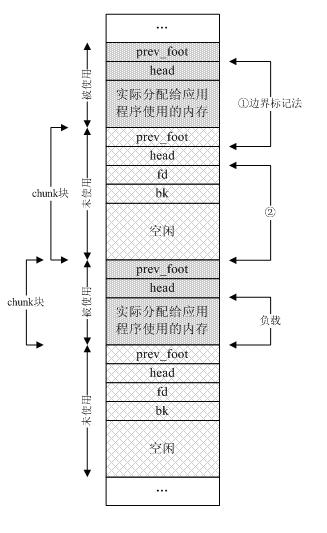
按照边界标记法,结构体malloc_chunk通过字段head和prev_foot将内存分割成很多块,从图中①所示,可以看到某结构体内的prev_foot是记录的前一个chunk块的信息(事实上是前一个chunk块的大小),因此我们可以利用如下宏:
#define prev_chunk(p) ((mchunkptr)( ((char*)(p)) - ((p)->prev_foot) ))
来获得前一个chunk块的malloc_chunk结构体指针。
指针fd、bk只有当该chunk块空闲时才存在,其作用时用于加入到空闲chunk块链中统一管理,而如果该chunk块被分配给应用程序使用,那么这两个指针也就没有用(该已经chunk块从空闲链中拆出)了,所以也当作应用程序的使用空间,而不至于浪费,图中②所示。
head字段记录与本chunk块的相关信息,这包括本chunk块大小,本块是否在使用中,前一chunk块是否在使用中。
head一个字段就能存储这么多信息是因为Dlmalloc在分割内存的时候总是以地址对齐(默认是8字节,可以自由设置,但是8字节是最小值并且设置的值必须是2为底的幂函数值,即是alignment = 2^n,n为整数且n>=3)的方式来进行的,所以用head来存储本chunk块大小字节数的话,其末3bit位总是0,因此这三位可以用来存储其它信息,比如:
以第0位作为标志位,标记前一chunk块是否在使用中,为1表示使用,为0表示空闲。
以第1位作为标志位,标记本chunk块是否在使用中,为1表示使用,为0表示空闲。
我们来看看它们的各自相关判断代码:
#define SIZE_T_ONE ((size_t)1)
#define SIZE_T_TWO ((size_t)2)
#define PINUSE_BIT (SIZE_T_ONE)
#define CINUSE_BIT (SIZE_T_TWO)
#define cinuse(p) ((p)->head & CINUSE_BIT)
#define pinuse(p) ((p)->head & PINUSE_BIT)
对于前面说的prev_foot字段,也利用了其一个空闲位用于标记该chunk块是否右mmap分配,于此类似,所以就不多说了,感兴趣的可以查看源码。
对于结构体malloc_tree_chunk,其实在内存分割上合结构体malloc_chunk完全一致,因为它们的前四个字段完全一样(事实上只有两个字段prev_foot和head起边界标记作用),其它的字段都是用于空闲链管理的。
本篇简单的把Dlmalloc如果按照边界标记法分割内存描述了一下,下篇继续两种空闲链的各自管理分析。
前面连载提到过对于大小在256字节以下的chunk块是通过malloc_chunk组织管理的,256字节以下的chunk块一共有256/8=32类,即字节为8字节、16字节、24字节、32字节,……,256字节,因此dlmalloc维护32个双向环形链表(而且具有链表头节点,加头节点的最大作用就是便于对链表内节点的统一处理,即简化编程),每一个链表里的各空闲chunk块的大小一致,因此当应用程序需要某个字节大小(这里的字节大小是考虑了chunk块头和对齐等所占空间了的,即如果应用如果程序调用函数malloc(
8 ),那么到dlmalloc这应该比8大,这种更细节的疑问下面还有,并非我故意不表达,只是转述太多了,倒说不清我自己真正想说的了,阅读时请读者自己注意就好)的内存空间时直接在对应的链表内取就可以了(具体稍有不同,即如果对应链表内没有空闲可用chunk块,则还会查看下一个链表,举个例子:当应用程序申请32个字节,如果32字节大小的链表为空,那么dlmalloc还会在大小为40字节的链表内查找空闲chunk块。),这样既可以很好的满足应用程序的内存空间申请请求而又不会出现太多的内存碎片。我们可以用如下图来表示dlmalloc对256字节以下的空闲chunk块组织方式。

dlmalloc程序使用smallbins数组来记录这32个双向环形链表表头,该字段定义在结构体malloc_state内,在这里我们先不管malloc_state结构体而只关注smallbins这个字段,它的定义如下:
struct malloc_chunk {
size_t
prev_foot;
/* Size of previous chunk (if free).
*/
size_t
head;
/* Size and inuse bits. */
struct malloc_chunk* fd;
/* double links -- used only if free. */
struct malloc_chunk* bk;
};
mchunkptr
smallbins[(NSMALLBINS+1)*2];
其中,mchunkptr在上一篇已经提过,为“typedef
struct malloc_chunk* mchunkptr;”,而空NSMALLBINS为32,即是“#define
NSMALLBINS (32U)”。因此smallbins为一个具有66个malloc_chunk结构体指针元素的数组,为什么是66个呢?不是32就可以了么?这里Doug
Lea使用了一个技巧,如果按照我们的常规想法,也许会申请32个malloc_chunk结构体指针元素的数组,然后再给链表申请一个头节点(即32个),再让每个指针元素正确指向而形成32个具有头节点的链表。事实上,对于malloc_chunk类型的链表“头节点”,其内的prev_foot和head字段是没有任何实际作用的,因此这两个字节如果不合理使用的话那就是白白的浪费。我们再来看一看66个malloc_chunk结构体指针元素的数组占了多少内存空间呢?结果为66*4=264字节。而32个malloc_chunk类型的链表“头节点”需要多少内存呢?32*10=320,真的是320么?不是,刚才不是说了,prev_foot和head这两个字段是没有任何实际作用的,因此完全可以被重用(覆盖),因此实际需要内存为32*8=256。264大于256,那么这66个malloc_chunk结构体指针元素数组所占内存空间就可以存储这32个头节点了,事实上Doug
Lea也是这么做的。我们来看下于此相关的这一句代码:
#define smallbin_at(M, i)
((sbinptr)((char*)&((M)->smallbins[(i)<<1])))
其中的sbinptr也是个malloc_chunk结构体指针类型(typedef
struct malloc_chunk* sbinptr;),M表示前面提到的结构体malloc_state,各位仔细体会一下这句代码中的强制转换就会理解这种技巧了。下面给个更直观的图便于理解: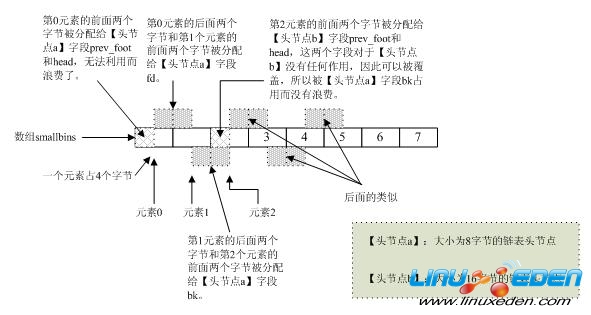
最后,至于为什么是66个数组元素而不是64或65,这个仔细想想也好理解,好了,就到这,下篇继续吧。