|
如何恢复 Linux 上删除的文件
不容错过的IBM集群技术资源汇总
 要想恢复误删除的文件,必须清楚数据在磁盘上究竟是如何存储的,以及如何定位并恢复数据。本文从数据恢复的角度,着重介绍了 ext2 文件系统中使用的一些基本概念和重要数据结构,并通过几个实例介绍了如何手工恢复已经删除的文件。最后针对 ext2 现有实现存在的大文件无法正常恢复的问题,通过修改内核中的实现,给出了一种解决方案。 在本系列文章的第一部分中,我们介绍了 ext2 文件系统中的一些基本概念和重要数据结构,并通过几个实例学习了如何恢复已经删除的文件,最后通过修改 2.6 版本内核中 ext2 文件系统的实现,解决了大文件无法正常恢复的问题。 通过第一部分的介绍,我们已经知道如何恢复系统中删除的普通文件了,但是系统中还存在一些特殊的文件,比如我们熟悉的符号链接等。回想一下在本系列文章的第一部分中,目录项是使用一个名为 ext2_dir_entry_2 的结构来表示的,该结构定义如下: 清单1. ext2_dir_entry_2 结构定义
其中 file_type 域就标识了每个文件的类型。ext2 文件系统中支持的文件类型定义如下表所示: 表 1. ext2 文件系统中支持的文件类型
对应的宏定义在 include/linux/ext2_fs.h 文件中。其中,命名管道和 socket 是进程间通信时所使用的两种特殊文件,它们都是在程序运行时创建和使用的;一旦程序退出,就会自动删除。另外,字符设备、块设备、命名管道和 socket 这 4 种类型的文件并不占用数据块,所有的信息全部保存在对应的目录项中。因此,对于数据恢复的目的来说,我们只需要重点关注普通文件、符号链接和目录这三种类型的文件即可。 文件洞 在数据库之类的应用程序中,可能会提前分配一个固定大小的文件,但是并不立即往其中写入数据;数据只有在真正需要的时候才会写入到文件中。如果为这些根本不包含数据的文件立即分配数据块,那就势必会造成磁盘空间的浪费。为了解决这个问题,传统的 Unix 系统中引入了文件洞的概念,文件洞就是普通文件中包含空字符的那部分内容,在磁盘上并不会使用任何数据块来保存这部分数据。也就是说,包含文件洞的普通文件被划分成两部分,一部分是真正包含数据的部分,这部分数据保存在磁盘上的数据块中;另外一部分就是这些文件洞。(在 Windows 操作系统上也存在类似的概念,不过并没有使用文件洞这个概念,而是称之为稀疏文件。) ext2 文件系统也对文件洞有着很好的支持,其实现是建立在动态数据块分配原则之上的,也就是说,在 ext2 文件系统中,只有当进程需要向文件中写入数据时,才会真正为这个文件分配数据块。 细心的读者可能会发现,在本系列文章第一部分中介绍的 ext2_inode 结构中,有两个与文件大小有关的域:i_size 和 i_blocks,二者分别表示文件的实际大小和存储该文件时真正在磁盘上占用的数据块的个数,其单位分别是字节和块大小(512字节,磁盘每个数据块包含8个块)。通常来说,i_blocks 与块大小的乘积可能会大于或等于 i_size 的值,这是因为文件大小并不都是数据块大小的整数倍,因此分配给该文件的部分数据块可能并没有存满数据。但是在存在文件洞的文件中,i_blocks 与块大小的乘积反而可能会小于 i_size 的值。 下面我们通过几个例子来了解一下包含文件洞的文件在磁盘上究竟是如何存储的,以及这种文件应该如何恢复。 执行下面的命令就可以生成一个带有文件洞的文件: 清单2. 创建带有文件洞的文件
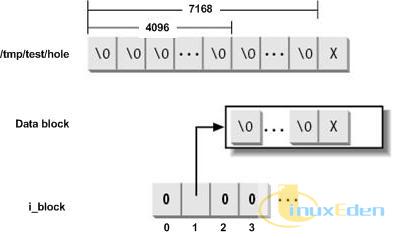
第一个命令生成的 /tmp/test/hole 文件大小是 7169 字节,其前 7168 字节都为空,第 7169 字节的内容是字母 X。正常来讲,7169 字节的文件需要占用两个数据块来存储,第一个数据块全部为空,第二个数据块的第 3073 字节为字母 X,其余字节都为空。显然,第一个数据块就是一个文件洞,在这个数据块真正被写入数据之前,ext2 并不为其实际分配数据块,而是将 i_block 域的对应位(或间接寻址使用的索引数据块中的对应位)设置为0,表示这是一个文件洞。该文件的内容如下图所示:
图1. /tmp/test/hole 文件的存储方法 file_hole.jpg 现在我们可以使用 debugfs 来查看一下这个文件的详细信息: 清单3. 带有文件洞的文件的 inode 信息
从输出结果中我们可以看出,这个文件的大小是 7169 字节(Size 值,即 ext2_inode 结构中 i_size 域的值),占用块数是 16(Blockcount 值,ext2_inode 结构中 i_blocks 域的值,每个块的大小是 512 字节,而每个数据块占据8个块,因此16个块的大小16×512字节相当于 2 个 512字节×8即4096字节的数据块),但是它的数据在磁盘上只是第一个数据块的内容保存在 20480 这个数据块中。使用下面的方法,我们就可以手工恢复整个文件: 清单4. 使用 dd 命令手工恢复带有文件洞的文件
注意第一个 dd 命令就是用来填充这个大小为 4096 字节的文件洞的,这是文件的第一部分;第二个 dd 命令从磁盘上读取出 20480 数据块的内容,其中包含了文件的第二部分。从合并之后的文件中提取出前 7169 字节的数据,就是最终恢复出来的文件。 接下来让我们看一个稍微大一些的带有文件洞的例子,使用下面的命令创建一个大小为57KB 的文件: 清单5. 创建 57K 大小的带有文件洞的文件
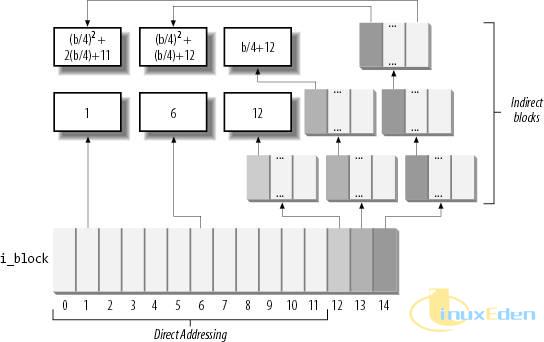
与上一个文件类似,这个文件的数据也只有一个字符,是 0x000e400(即第58369字节)为字符“Y”。我们真正关心的是这个文件的数据存储情况: 清单6. 使用间接寻址方式的带有文件洞的文件的 inode 信息
从结果中可以看出,该文件占用了两个数据块来存储数据,一个是间接寻址使用的索引块 24576,一个是真正存放数据的数据块24577。下面让我们来查看一下 24576 这个数据块中的内容: 清单7. 索引数据块中存储的数据
正如预期的一样,其中只有第3个 32 位(每个数据块的地址占用32位)表示了真正存储数据的数据块的地址:0x6001,即十进制的 24577。现在恢复这个文件也就便得非常简单了: 清单8. 手工恢复带有文件洞的大文件
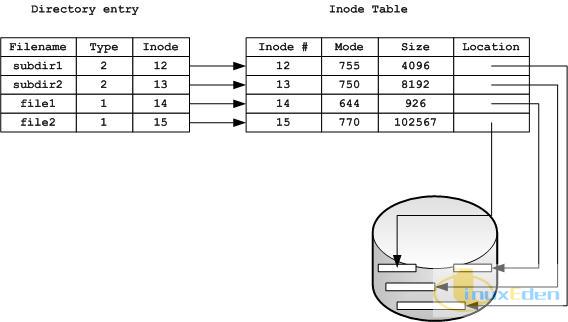
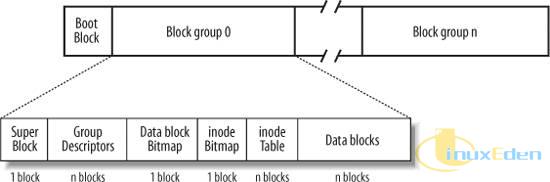
幸运的是,debugfs 的 dump 命令可以很好地理解文件洞机制,所以可以与普通文件一样完美地恢复整个文件,详细介绍请参看本系列文章的第一部分。 目录 在 ext2 文件系统中,目录是一种特殊的文件,其索引节点的结构与普通文件没什么两样,唯一的区别是目录中的数据都是按照 ext2_dir_entry_2 结构存储在数据块中的(按照 4 字节对齐)。在开始尝试恢复目录之前,首先让我们详细了解一下目录数据块中的数据究竟是如何存储的。现在我们使用 debugfs 来查看一个已经准备好的目录的信息: 清单9. 用来测试的文件系统的信息
从输出结果中可以看出,每个目录结构中至少要包含两项:当前目录(.)和父目录(..)的信息。在一个文件系统中,会有一些特殊的索引节点是保留的,用户创建的文件无法使用这些索引节点。2 就是这样一个特殊的索引节点,表示根目录。结合上面的输出结果,当前目录(.)和父目录(..)对应的索引节点号都是2,表示这是该分区的根目录。特别地,在使用 mke2fs 命令创建一个 ext2 类型的文件系统时,会自动创建一个名为 lost+found 的目录,并为其预留 4 个数据块的大小(16KB),其用途稍后就会介绍。 我们在根目录下面创建了几个文件和一个名为 dir1(索引节点号为 32577)的目录,并在 dir1 中又创建了两个子目录(subdir1 和 subdir2)和几个文件。 要想完美地恢复目录,必须了解清楚在删除目录时究竟对系统进行了哪些操作,其中哪些是可以恢复的,哪些是无法恢复的,这样才能寻找适当的方式去尝试恢复数据。现在先让我们记录下这个文件系统目前的一些状态: 清单10. 根目录(索引节点 <2>)子目录 dir1的 inode 信息
以及根目录和 dir1 目录的数据块: 清单11. 备份根目录和子目录 dir1 的数据块
为了方便阅读目录数据块中的数据,我们编写了一个小程序,源代码如下所示: 清单12. read_dir_entry.c 源代码
|
原贴:http://www.linuxeden.com/html/sysadmin/20080311/50582.html