|
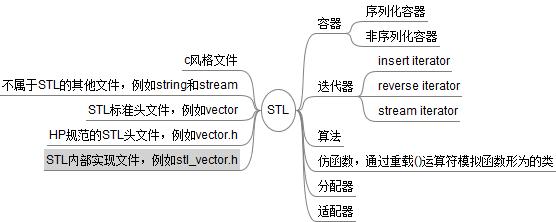
1、容器(Containers):各种数据结构,如Vector,List,Deque,Set,Map,用来存放数据,STL容器是一种Class Template,就体积而言,这一部分很像冰山载海面的比率。
2、算法(Algorithms):各种常用算法如Sort,Search,Copy,Erase,从实现的角度来看,STL算法是一种Function Templates。 3、迭代器(Iterators):扮演容器与算法之间的胶合剂,是所谓的“泛型指针”,共有五种类型,以及其它衍生变化,从实现的角度来看,迭代器是一种将:Operators*,Operator->,Operator++,Operator--等相关操作予以重载的Class Template。所有STL容器都附带有自己专属的迭代器——是的,只有容器设计者才知道如何遍历自己的元素,原生指针(Native pointer)也是一种迭代器。 4、仿函数(Functors): 行为类似函数,可作为算法的某种策略(Policy),从实现的角度来看,仿函数是一种重载了Operator()的Class 或 Class Template。一般函数指针可视为狭义的仿函数。 5、配接器(Adapters):一种用来修饰容器(Containers)或仿函数(Functors)或迭代器(Iterators)接口的东西,例如:STL提供的Queue和Stack,虽然看似容器,其实只能算是一种容器配接器,因为 它们的底部完全借助Deque,所有操作有底层的Deque供应。改变Functor接口者,称为Function Adapter;改变Container接口者,称为Container Adapter;改变Iterator接口者,称为Iterator Adapter。配接器的实现技术很难一言蔽之,必须逐一分析。 6、配接器(Allocators):负责空间配置与管理,从实现的角度来看,配置器是一个实现了动态空间配置、空间管理、空间释放的Class Template。 |

“函数指针”与“返回函数指针的函数”
static void (* __set_malloc_handler(void (*__f)()))()
到底是一个函数呢,还是一个函数指针呢。
这个应该这么理解:
1. 首先看__f,很快可以确定__f是一个函数指针,因为有个最小的括号集(*__f),该指针指向的函数类型为 void func()。
2. 再看__set_malloc_handler,这里由于括号的优先级别比* 高,因此__set_malloc_handler优先和(void (*__f)())结合,解释为一个函数。
3.再向左看到*,返回值为一个指针。
4.紧接是一个括号修饰*,返回的指针指向的是一个函数。
稍微做一下修改,则可以得到该函数的指针类型:
static void (* (*__set_malloc_handler)(void (*__f)()))()
例子如下:
16 #include <iostream>
17
18 static void void_func()
19 {
20 std::cout << "void function called" << std::endl;
21 }
22 static void (* __set_malloc_handler(void (*__f)()))()
23 {
24 std::cout << "function which contain function point parament called" << std::endl;
25 return __f;
26 }
27
28 int main()
29 {
30
31 static void (*(* func)(void (*__f)()))() = NULL;
32 func = __set_malloc_handler;
33 (*func)(void_func);
34 return 0;
35 }
仿函数VS回调函数
仿函数(functor)的优点
我的建议是,如果可以用仿函数实现,那么你应该用仿函数,而不要用回调。原因在于:
仿函数可以不带痕迹地传递上下文参数。而回调技术通常使用一个额外的void*参数传递。这也是多数人
认为回调技术丑陋的原因。
更好的性能。
仿函数技术可以获得更好的性能,这点直观来讲比较难以理解。你可能说,回调函数申明为inline了,怎
么会性能比仿函数差?我们这里来分析下。我们假设某个函数func(例如上面的std::sort)调用中传递
了一个回调函数(如上面的compare),那么可以分为两种情况:
func是内联函数,并且比较简单,func调用最终被展开了,那么其中对回调函数的调用也成为一普通函数
调用(而不是通过函数指针的间接调用),并且如果这个回调函数如果简单,那么也可能同时被展开。在
这种情形下,回调函数与仿函数性能相同。
func是非内联函数,或者比较复杂而无法展开(例如上面的std::sort,我们知道它是快速排序,函数因
为存在递归而无法展开)。此时回调函数作为一个函数指针传入,其代码亦无法展开。而仿函数则不同。
虽然func本身复杂不能展开,但是func函数中对仿函数的调用是编译器编译期间就可以确定并进行inline
展开的。因此在这种情形下,仿函数比之于回调函数,有着更好的性能。并且,这种性能优势有时是一种
无可比拟的优势(对于std::sort就是如此,因为元素比较的次数非常巨大,是否可以进行内联展开导致
了一种雪崩效应)。
仿函数(functor)不能做的?
话又说回来了,仿函数并不能完全取代回调函数所有的应用场合。例如,我在std::AutoFreeAlloc中使用
了回调函数,而不是仿函数,这是因为AutoFreeAlloc要容纳异质的析构函数,而不是只支持某一种类的
析构。这和模板(template)不能处理在同一个容器中支持异质类型,是一个道理。
内联函数是代码被插入到调用者代码串处的函数。如同 #define 宏,内联函数通过避免被调用的开销来
提高执行效率,尤其是它能够通过调用(“过程化集成”)被编译器优化。
inline 是一种“用于实现的关键字”,而不是一种“用于声明的关键字”。
一般地,用户可以阅读函数的声明,但是看不到函数的定义。尽管在大多数教科书中内
联函数的声明、定义体前面都加了inline 关键字,但我认为inline 不应该出现在函数
的声明中。这个细节虽然不会影响函数的功能,但是体现了高质量C++/C 程序设计风格
的一个基本原则:声明与定义不可混为一谈,用户没有必要、也不应该知道函数是否需
要内联。
为什么我应该用内联函数?而不是原来清晰的 #define 宏?
因为#define宏是在四处是有害的
和 #define 宏不同的是,内联函数总是对参数只精确地进行一次求值,从而避免了声名狼藉的宏错误。
换句话说,调用内联函数和调用正规函数是等价的,差别仅仅是更快:
// 返回 i 的绝对值的宏
#define unsafe(i) /
( (i) >= 0 ? (i) : -(i) )
// 返回 i 的绝对值的内联函数
inline
int safe(int i)
{
return i >= 0 ? i : -i;
}
int f();
void userCode(int x)
{
int ans;
ans = unsafe(x++); // 错误!x 被增加两次 相当于ans=((x++)>=0?(x++):-(x++));
ans = unsafe(f()); // 危险!f()被调用两次 相当于ans=((f())>=0?(f()):-(f()));
//内联函数调用参数需进行类型检查并进行一次精确求值后再被编译器代码展开,而宏定义则没有类型检查和求值就展开。
ans = safe(x++); // 正确! x 被增加一次 相当于调用是int param=x++;ans=safe(param);
ans = safe(f()); // 正确! f() 被调用一次 相当于调用是int param=f();ans=safe(param);
}
和宏不同的,还有内联函数的参数类型被检查,并且被正确地进行必要的转换。
宏是有害的;非万不得已不要用。