作者:于淼
本文旨在说明 CUBRID 这一数据库引擎中的线程模型。将分别从客户端和服务器端两个视角描述一个请求是被 CUBRID 响应的过程。
下图描述了整体的线程结构:
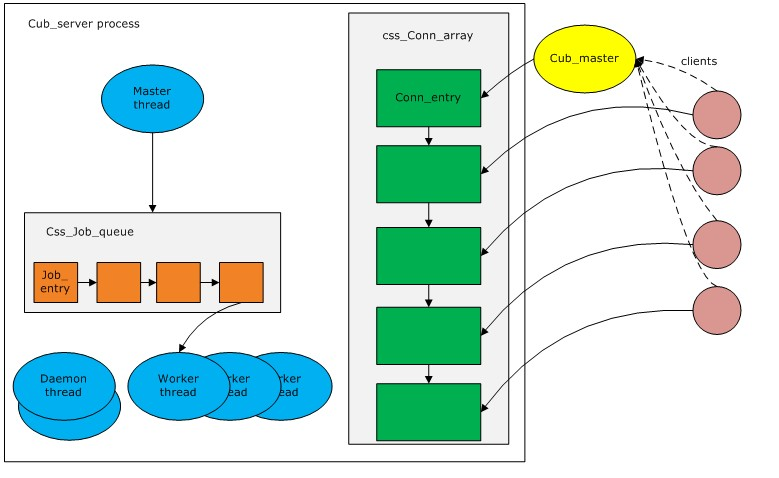
在描述请求处理过程之前有必要先说一下各个线程所扮演的角色(以下说明都是基于Linux平台,Windows下的表现会略有不同,文后将作以说明)。如图所示,CUBRID 服务器端共有2个进程:
1. Cub_master
对客户端来讲只有master是可见的。为了与cub_server 通信, 客户端首先与cub_mater建立连接。Cub_master将客户端socket传递给cub_server 并由其保存在css_Conn_array队列中。
2. Cub_server
Cub_server以多线程的形式进行分工。
a) Master thread
处理来自master进程的请求。主要负责以下三件事情:
(1) 检测cub_master进程的状态
(2) 处理新连接请求
(3) 处理shutdown请求
b) Worker thread
客户端请求的真正执行者。
c) Daemon thread
CUBRID 中共有6个守护线程, 分别负责以下工作:
(1) Dead lock detection
(2) Checkpoint
(3) Oob-handler
(4) Page flush
(5) Flush control
(6) Log flush
下面以请求如何被处理的流程来说明各个进程线程之间是如何协同工作的。
1. 当一个新的客户端试图与server建立连接时,它需要首先与cub_master建立连接。
2. Cub_master将与客户端进行通信的套接字传递给cub_server中的master thread。
3. master_thread在接到新连接请求之后,首先从css_Conn_array空取出一个空闲的conn_entry将此套接字放入其中,生成一个完整的conn_entry(除套接字以外,还包括client_id, transaction_id, request_id等信息),并将其设置为active状态。
4. master_thread利用步骤3中生成的conn_entry 生成一个新的job_entry 放入 css_Job_queue当中, 并设定其handle_function