1、select * from v$lock;
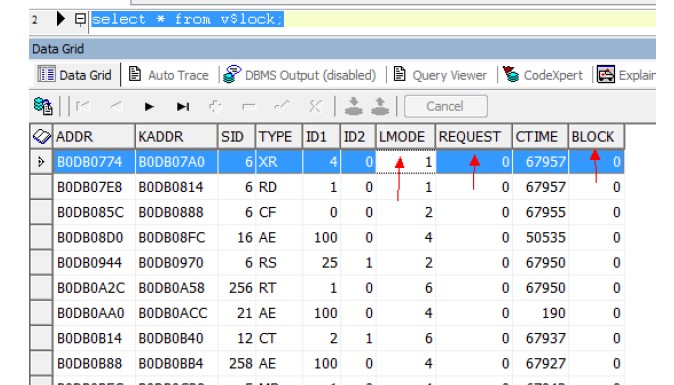
我们关注比较多的是request和block字段,如果某个request列是个非0值,那么他就是在等待一个锁。如果block列值是1,那这个SID就持有了一个锁,并且阻塞别人活得这个锁,这个锁的类型由type字段定义。锁的模式有lmode字段定义,ID1,ID2字段定义了这个锁的相关信息,id1相同,就代表执行同一个资源。这样就有可能有加锁者和等待者。
2、表数据块
如果出现热快,并且表不太大,一个方法——可以考虑将表分布在更多的数据块上,减少数据块被多数会话同时访问的频率。
可以通过如下命令将每个数据块存放记录的数量减少到最少:
alter table minimize record_per_block;
这样大大降低了热块出现的可能性,但是缺点也是显而易见的。。增加了数据块,很明显的问题就是访问需要读取的数据块多了,io也就多了,性能自然会降低。。
3、反向索引
反向索引使用场合之所以如此受限制,是因为它丢弃了 B-Tree 索引的一个 索引的一个 最重要的功能:
INDEX RANGE SCAN
索引访问方式中,这个方式最常见,但是反向索引却不能使用这个功能,因为反向索引已经把键值的排序打乱,当按照键值顺序产找一个范文时,在方向索引中,由于键值被反向存储,这些值已经不是连续存放的了。所以,index range scan的方式在反向索引中没有任何意义。
在反向索引中只能通过全表扫描或者全索引扫描的方式来实现。这就是反向索引的一个非常严重的缺陷。。
4、等待事件
下面将介绍33个常见的等待事件:
1、buffer busy wait:从本质上讲,这个等待事件的产生仅说明了一个会话在等待一个buffer(数据块),但是导致这种现象的原因却又很多种,常见的两种是:
当一个会话试图修改一个数据块,但是这个数据块正在被别的会话修改。
当一个会话试图读取一个数据块 ,但是这个数据块正在被另一个会话读取到内存中时。
当会话修改一个数据块时,是按照以下步骤来完成的:
以排他凡是获得块(用latch)——修改这个块——释放latch。
buffer busy waits等待事件常见于数据库中存在热块的时候,当多个用户频繁地读取或者修改同样的数据块时,这个等待就会产生。。如果等待的时间很长,我们再awr或者statspack报告中就可以看到。。
这个等待事件有三个参数,我们可以用如下sql语句来查看:
SQL>select name,parameter1,parameter2,parameter3 from v$event_name where name='buffer busy' watis';
NAME PARAMETER1 PARAMETER2 PARAMETER3
----------- ------------------ ------------------- -------------------
buffer busy waits file# block# class#
在下面的示例中,查询方法和这个一样,所以,其他事件对参数的查询将不做过多说明。
file# : 等待访问数据块所在的文件id号。
blocks:等待访问的数据块号。
id:在10g之前,这个值标识一个等待时间的原因,10g之后则表示等待事件的类别。
注意该等待事件与free buffer wait 等待事件的区别,free buffer wait事件是因为把数据块从磁盘读入到内存中,内存中没有可用的空闲块,所以产生了这个等待,而buffer busy wait 等待是因为内存块忙,被多个进程访问,或者数据块正在被读入内存。
2、buffer latch:内存数据块的bh存在cache buffer chains中。这个buffer latch就是用来保护这个链表的。产生这个buffer latch等待的原因是:
buffer chains太长,导致会话搜索到这个列表话费的时间太长,使其他会话处于等待状态。还有一种就是某些数据块被频繁访问。也就是我们常说的热快问题。如果buffer chains太长,我们可以使用 多个buffer pool的方式来创建更多的buffer chains,或者使用参数DB_BLOCK_LRU_LATCHES来增加latch的数量,以便跟多的会话可以获得latch,这两种方法可以同时使用。
这个等待事件还有两个参数。。不错。。我之前确实不知道等待事件还有参数。。。
1.latch addr : 会话申请的latch在SGA中的虚拟地址,通过以下的sql语句可以根据这个地址找到他对应的latch名称:
select * from v$latch a , v$latch_name b where addr = latch addr ——这个latch addr是你从等待事件中看到的值
and a.latch# = b.latch#;
2.chain# : buffer chains hash 列表中的索引值,这个参数的值等于s 0x fffffff 时,说明当前的会话正在等大爱一个LRU latch。。
3、control file parallel write (控制文件并行写) :当数据库中有多个控制文件的拷贝时,oracle需要保证信息同步的写到各个控制文件当中,这是一个并行的物理操作过程,因为称为控制文件并行写,当发生这样的操作时,就会产生control file parallel write等待事件。
控制文件频繁写入的云因很多。比如常见的日志切换过于频繁,导致控制文件信息相应地要频繁更新(可以适当的增大日志文件的大小来降低日志切换的频率)。还有系统IO出现瓶颈,导致所有的IO出现等待(可以适当减少控制文件的个数,或者可以把控制文件放到不同的磁盘上)。这个等待事件包含三个参数:
files: oracle要写入的控制文件个数。
blocks: 写入控制文件的数据块的数目。
requests: 写入控制请求的io次数。
4、contorl file sequential read(控制文件顺序读): 当数据库需要读取控制文件上的信息时,会出现这个等待事件,因为控制文件的信息时顺序写的,所以读取的时候也是顺序的,因此成为控制文件顺序读,它经常发生在一下情况:
1)备份控制文件
2)RAC环境下不同实例之间的控制文件的信息共享
3)读取控制文件的文件头信息
4)读取控制文件的其他信息
file# : 要读取信息的控制文件的文件号
block# :读取控制文件信息的起始数据块号。
blocks:需要读取的控制文件数据块的数目。
5、db file parallel read :这是一个很容易引起误导的等待事件。实际上这个等待事件和并行操作(比如并行查询,并行DML)没有关系。这个事件发生在数据库恢复的时候,当有一些数据块需要恢复的时候,Oracle会以并行的方式从数据文件中读入到内存中进行恢复操作。
这个等待事件包含三个参数:
files:操作需要读取的文件个数。
blocks: 操作需要读取的数据块个数。
requests:操作需要执行的io次数。
6、 db file parallel write: 这是一个后台等待事件,它同样和用户的并行操作没有关系,它是由后台进程的DBWR产生的,当后太进程DBWR向磁盘上写入脏数据的时候,会发生这个等待,
DBWR会批量地将脏数据并行写入到磁盘上相应的文件中,在这个次作业完成之前, DBWR 将出现这个等待事件。 如果仅是这一个等待事件, 对用户的操作并没有太大影响, 当伴随着出现 free buffer waits 等待事件时 ,说 明此时内存中可用的空间不足,这候会影响到户操作,比如将脏数据读入到内存中。
当出现db file parallel write等待事件时,可以通过启用操作系统的异步IO的方式来缓解这个等待。当使用异步IO时,dbwr不需要一直等到所有数据块全部写入磁盘上,它只需等到这个数据写入到一个百分比之后,就可以继续进行后续的操作。
这个等待事件有两个参数:
requests: 操作需要执行的io次数。
timeouts:等待的超时时间。
7、db file scattered read : 这个等待事件在实际生产库中经常可以看到,这是一个用户操作引起的等待事件,当用户发出每次IO需要读取多个数据块这样的sql操作时,会产生这个等待事件,最常见的联众情况是全表扫描(FTS:full table scan) 和索引快速扫描(IFFS: index fast full scan)
这个名称中的 scattered( 发散 ),可能会导致很多人认为它是以scattered 的方 式来读取数据块的, 其实恰相反,当发生这种等待事件时,SQL 的操作都是 顺序地读取数据块的,比如 FTS或者IFFS方式(如果忽略需要读取的数据块已 方式(如果忽略需要读取的数据块已 经存在内中的情况)。
这里的scattered指的是读取的数据块在内存中的存放方式,他们被读取到内存中后,是以分散的方式存在内存中,而不是连续的。
这个等待事件有三个参数:
file# : 要读取的数据块所在数据文件号,
block#: 要读取的其实数据块号。
blocks:需要读取的数据块数目。
8、db file sequential read : 这个等待事件在实际生产库也很常见,当 Oracle 需要每次 I/O 只读取单个数 据块这样的操作时,会产生个等待事件。 据块这样的操作时,会产生个等待事件。 最常见的情况有索引访问(除 IFFS外的方式),回滚操作,以 ROWID的方式访问表中数据,重建控制文件,对 文件头做 DUMP 等。
这里的 sequential 也并非指的是 Oracle 按顺序的方式来访问数据,和db file scattered read一样,它指的是读取数据块在内存中以连续方式存放的。
这个等待事件有三参数:
File#: 要读取的数据块锁在文件号。
Block# : 要读取的起始数据块号。 要读取的起始数据块号。
BBlocks : 要读取的数据块目(这里应该等于 1)
9、db file single write : 这个等待事件通常只发生在一种情况下,就是oracle更新数据文件头信息时,比如发生checkpoint时。。当这个等待事件很明显时,需要考虑是不是数据库中的数据文件数量太大,导致oracle需要花费较长的时间来做所有文件头的更新操作(checkpoint)
这个等待事件有三个参数:
file#:需要更新的数据块所在的数据文件的文件号。
block#:需要更新的数据块号。
blocks:需要更新的数据块的数目(通常来说应该等于1)
10、direct path read : 这个 等待事件发生在会话将数据块直接读取到 PGA当中而不是 SGA 中的情 况,这些被读取的数据通常是个会话私有数据,所以不需要放到SGA作为共享数据,因为这样做没有意义。 这些数据 通常是来自与临时段上的这些数据,比 如一个会话中 SQL的排序数据,并行执过程中间产生的数据,以及 Hash Join, merge join 产生的 排序数据,因为这些数据只对当前会话SQL操作有意义,
所以不需要放到 SGA当中。
当发生 direct path read 等待事件时, 意味着磁盘上有大量的临数据产生,比如排序,并行执等操作。 或者意味着 PGA 中空间不足。
这个等待事件有三参数:
Descriptor address : 一个 指针,向当前会话正在等待的direct read I/O 。
First dba:descriptor address 中最旧的一个 I/O数据块地址。
Block cnt: descriptor address上下文中涉及的 有效上下文中涉及的 有效buffer 数量。
11 、 Direct path write: 这个等待事件和 direct path read 正好相反,是会话将一些数据从 PGA中直 接写入到磁盘文件上,而不经过 SGA 。
这种情况通常发生在:
(1)使用临时表空间排序(内存不足)
(2)数据的直接加载(使用 append方式加载数据)
(3)并行 DML操作。
这个等待事件有三 个参数:
Descriptor address :一个 指针,向当前会话正在等待的一个 指针,向当前会话正在等待的direct I/O
First dba: descriptor address 中最旧的一个 I/OI/O 数据块地址。
Block cnt: descriptor address 上下文中涉及的有效地 buffer 数量。
12、Enqueue:这个词其实是lock的另一种描述语。当我们在AWR报告中发现长时间的enquenue等待事件时,说明数据库中出现了阻塞和等待,可以关联AWR报告中的qnqueue activity部分来确定是哪一种锁定出现了长时间等待。
这个等待事件有两个参数:
name:enqueue的名称和类型。
mode: enqueue的模式。
可以使用如下SQL 查看当前会话等待的enqueue名称和类型:
/* Formatted on 2010/8/12 11:00:56 (QP5 v5.115.810.9015) */
SELECT CHR (TO_CHAR (BITAND (p1, -16777216)) / 16777215)
|| CHR (TO_CHAR (BITAND (p1, 16711680)) / 65535)
"Lock",
TO_CHAR (BITAND (p1, 65535)) "Mode"
FROM v$session_wait
WHERE event = 'enqueue'
Oracle 的enqueue 包含以下模式:
|
模式代码 |
解释 |
|
1 |
Null mode |
|
2 |
Sub-Share |
|
3 |
Sub-Exclusive |
|
4 |
Share |
|
5 |
Share/Sub-Exclusive |
|
6 |
Exclusive |
Oracle的enqueue 有如下类型:
|
Enqueue 缩写 |
缩写解释 |
|
BL |
Buffer Cache management |
|
BR |
Backup/Restore |
|
CF |
Controlfile transaction |
|
CI |
Cross-instance Call Invocation |
|
CU |
Bind Enqueue |
|
DF |
Datafile |
|
DL |
Direct Loader Index Creation |
|
DM |
Database Mount |
|
DR |
Distributed Recovery Process |
|
DX |
Dirstributed Transaction |
|
FP |
File Object |
|
FS |
File Set |
|
HW |
High-water Lock |
|
IN |
Instance Number |
|
IR |
Instance Recovery |
|
IS |
Instance State |
|
IV |
Library Cache Invalidation |
|
JI |
Enqueue used during AJV snapshot refresh |
|
JQ |
Job Queue |
|
KK |
Redo Log “Kick” |
|
KO |
Multiple Object Checkpoint |
|
L[A-p] |
Library Cache Lock |
|
LS |
Log start or switch |
|
MM |
Mount Definition |
|
MR |
Media recovery |
|
N[A-Z] |
Library Cache bin |
|
PE |
Alter system set parameter =value |
|
PF |
Password file |
|
PI |
Parallel slaves |
|
PR |
Process startup |
|
PS |
Parallel slave synchronization |
|
Q[A-Z] |
Row Cache |
|
RO |
Object Reuse |
|
RT |
Redo Thread |
|
RW |
Row Wait |
|
SC |
System Commit Number |
|
SM |
SMON |
|
SN |
Sequence Number |
|
SQ |
Sequence Number Enqueue |
|
SR |
Synchronized replication |
|
SS |
Sort segment |
|
ST |
Space management transaction |
|
SV |
Sequence number Value |
|
TA |
Transaction recovery |
|
TC |
Thread Checkpoint |
|
TE |
Extend Table |
|
TM |
DML enqueue |
|
TO |
Temporary Table Object Enqueue |
|
TS |
Temporary Segement(also TableSpace) |
|
TT |
Temporary Table |
|
TX |
Transaction |
|
UL |
User-defined Locks |
|
UN |
User name |
|
US |
Undo segment, Serialization |
|
WL |
Being Written Redo Log |
|
XA |
Instance Attribute Log |
|
XI |
Instance Registration Lock |
关于enqueue 可以参考如下的连接:
Wait Events - Enqueue Waits
http://www.toadworld.com/KNOWLEDGE/KnowledgeXpertforOracle/tabid/648/TopicID/WE1/Default.aspx
13、Free buffer waits
当一个会话将数据块从磁盘读到内存中时,它需要到内存中找到空闲的内存空间来存放这些数据块,当内存中没有空闲的空间时,就会产生这个等待;除此之外,还有一种情况就是会话在做一致性读时,需要构造数据块在某个时刻的前映像(image),此时需要申请内存来存放这些新构造的数据块,如果内存中无法找到这样的内存块,也会发生这个等待事件。
当数据库中出现比较严重的free buffer waits等待事件时,可能的原因是:
(1) data buffer 太小,导致空闲空间不够
(2) 内存中的脏数据太多,DBWR无法及时将这些脏数据写到磁盘中以释放空间
这个等待事件包含2个参数:
File#: 需要读取的数据块所在的数据文件的文件号。
Block#: 需要读取的数据块块号。
14、 Latch free
在10g之前的版本里,latch free 等待事件代表了所有的latch等待,在10g以后,一些常用的latch事件已经被独立了出来:
SQL> select name from v$event_name where name like 'latch%' order by 1;
NAME
----------------------------------------------------------------
latch activity
latch free
latch: Change Notification Hash table latch
latch: In memory undo latch
latch: MQL Tracking Latch
latch: PX hash array latch
latch: Undo Hint Latch
latch: WCR: processes HT
latch: WCR: sync
latch: cache buffer handles
latch: cache buffers chains
latch: cache buffers lru chain
latch: call allocation
latch: change notification client cache latch
latch: checkpoint queue latch
latch: enqueue hash chains
latch: gc element
latch: gcs resource hash
latch: ges resource hash list
latch: lob segment dispenser latch
latch: lob segment hash table latch
latch: lob segment query latch
latch: messages
latch: object queue header operation
latch: parallel query alloc buffer
latch: redo allocation
latch: redo copy
latch: redo writing
latch: row cache objects
latch: session allocation
latch: shared pool
latch: undo global data
latch: virtual circuit queues
已选择33行。
所以latch free 等待事件在10g以后的版本中并不常见,而是以具体的Latch 等待事件出现。
这个等待事件有三个参数:
Address: 会话等待的latch 地址。
Number: latch号,通过这个号,可以从v$latchname 视图中找到这个latch 的相关的信息。
SQL> select * from v$latchname where latch#=number;
Tries: 会话尝试获取Latch 的次数。
15、 Library cache lock
这个等待事件发生在不同用户在共享池中由于并发操作同一个数据库对象导致的资源争用的时候,比如当一个用户正在对一个表做DDL 操作时,其他的用户如果要访问这张表,就会发生library cache lock等待事件,它要一直等到DDL操作完成后,才能继续操作。
这个事件包含四个参数:
Handle address: 被加载的对象的地址。
Lock address: 锁的地址。
Mode: 被加载对象的数据片段。
Namespace: 被加载对象在v$db_object_cache 视图中namespace名称。
16、 Library cache pin
这个等待事件和library cache lock 一样是发生在共享池中并发操作引起的事件。通常来讲,如果Oracle 要对一些PL/SQL 或者视图这样的对象做重新编译,需要将这些对象pin到共享池中。 如果此时这个对象被其他的用户特有,就会产生一个library cache pin的等待。
这个等待事件也包含四个参数:
Handle address: 被加载的对象的地址。
Lock address: 锁的地址。
Mode: 被加载对象的数据片段。
Namespace: 被加载对象在v$db_object_cache 视图中namespace名称。
17、 Log file parallel write
后台进程LGWR 负责将log buffer当中的数据写到REDO 文件中,以重用log buffer的数据。 如果每个REDO LOG组里面有2个以上的成员,那么LGWR进程会并行地将REDO 信息写入这些文件中。
如果数据库中出现这个等待事件的瓶颈,主要的原因可能是磁盘I/O性能不够或者REDO 文件的分布导致了I/O争用,比如同一个组的REDO 成员文件放在相同的磁盘上。
这个等待事件有三个参数:
Files: 操作需要写入的文件个数。
Blocks: 操作需要写入的数据块个数。
Requests:操作需要执行的I/O次数。
18、Log buffer space
当log buffer 中没有可用空间来存放新产生的redo log数据时,就会发生log buffer space等待事件。 如果数据库中新产生的redo log的数量大于LGWR 写入到磁盘中的redo log 数量,必须等待LGWR 完成写入磁盘的操作,LGWR必须确保redo log写到磁盘成功之后,才能在redo buffer当中重用这部分信息。
如果数据库中出现大量的log buffer space等待事件,可以考虑如下方法:
(1) 增加redo buffer的大小。
(2) 提升磁盘的I/O性能
19、 Log file sequential read
这个等待事件通常发生在对redo log信息进行读取时,比如在线redo 的归档操作,ARCH进程需要读取redo log的信息,由于redo log的信息是顺序写入的,所以在读取时也是按照顺序的方式来读取的。
这个等待事件包含三个参数:
Log#: 发生等待时读取的redo log的sequence号。
Block#: 读取的数据块号。
Blocks: 读取的数据块个数。
20、Log file single write
这个等待事件发生在更新redo log文件的文件头时,当为日志组增加新的日志成员时或者redo log的sequence号改变时,LGWR 都会更新redo log文件头信息。
这个等待事件包含三个参数:
Log#: 写入的redo log组的编号。
Block#:写入的数据块号。
Blocks:写入的数据块个数。
21、Log file switch(archiving needed)
在归档模式下,这个等待事件发生在在线日志切换(log file switch)时,需要切换的在线日志还没有被归档进程(ARCH)归档完毕的时候。 当在线日志文件切换到下一个日志时,需要确保下一个日志文件已经被归档进程归档完毕,否则不允许覆盖那个在线日志信息(否则会导致归档日志信息不完整)。
出现这样的等待事件通常是由于某种原因导致ARCH 进程死掉,比如ARCH进程尝试向目的地写入一个归档文件,但是没有成功(介质失效或者其他原因),这时ARCH进程就会死掉。如果发生这种情况,在数据库的alert log文件中可以找到相关的错误信息。
这个等待事件没有参数。
22、Log file switch(checkpoint incomplete)
当一个在线日志切换到下一个在线日志时,必须保证要切换到的在线日志上的记录的信息(比如一些脏数据块产生的redo log)被写到磁盘上(checkpoint),这样做的原因是,如果一个在线日志文件的信息被覆盖,而依赖这些redo 信息做恢复的数据块尚未被写到磁盘上(checkpoint),此时系统down掉的话,Oracle将没有办法进行实例恢复。
在v$log 视图里记录了在线日志的状态。 通常来说,在线日志有三种状态。
Active: 这个日志上面保护的信息还没有完成checkpoint。
Inactive: 这个日志上面保护的信息已完成checkpoint。
Current: 当前的日志。
Oracle 在做实例恢复时,会使用状态为current和Active的日志进行实例恢复。
如果系统中出现大量的log file switch(checkpoint incomplete)等待事件,原因可能是日志文件太小或者日志组太少,所以解决的方法是,增加日志文件的大小或者增加日志组的数量。
这个等待事件没有参数。
23、Log file sync
这是一个用户会话行为导致的等待事件,当一个会话发出一个commit命令时,LGWR进程会将这个事务产生的redo log从log buffer里面写到磁盘上,以确保用户提交的信息被安全地记录到数据库中。
会话发出的commit指令后,需要等待LGWR将这个事务产生的redo 成功写入到磁盘之后,才可以继续进行后续的操作,这个等待事件就叫作log file sync。
当系统中出现大量的log file sync等待事件时,应该检查数据库中是否有用户在做频繁的提交操作。
这种等待事件通常发生在OLTP系统上。 OLTP 系统中存在很多小的事务,如果这些事务频繁被提交,可能引起大量的log file sync的等待事件。
这个等待事件包含一个参数:
Buffer#: redo buffer 中需要被写入到磁盘中的buffer。
24、SQL*Net break/reset to client
当出现这个等待事件时,说明服务器端在给客户端发送一个断开连接或者重置连接的请求,正在等待客户的响应,通常的原因是服务器到客户端的网络不稳定导致的。
这个等待事件包含两个参数:
Driver id: 服务器和客户端连接使用的协议信息。
Break?:零表示服务端向客户端发送一个重置(reset)信息,非零表示服务器端向客户端发送一个断开(break)消息。
25、SQL*Net break/reset to dblink
这个等待事件和SQL*Net break/reset to client 相同。 不过它表示的是数据库通过dblink访问另一台数据库时,他们之间建立起一个会话,这个等待事件发生在这个会话之间的通信过程中,同样如果出现这个等待事件,需要检查两台数据库之间的通信问题。
这个等待事件有两个参数:
Driver id: 服务器和客户端连接使用的协议信息。
Break?:零表示服务端向客户端发送一个重置(reset)信息,非零表示服务器端向客户端发送一个断开(break)消息。
26、SQL*Net message from client
这个等待事件基本上是最常见的一个等待事件。 当一个会话建立成功后,客户端会向服务器端发送请求,服务器端处理完客户端请求后,将结果返回给客户端,并继续等待客户端的请求,这时候会产生SQL*Net message from client 等待事件。
很显然,这是一个空闲等待,如果客户端不再向服务器端发送请求,服务器端将一直处于这个等待事件状态。
这个等待事件包含两个参数:
Driver id: 服务器端和客户端连接使用的协议信息。
#bytes: 服务器端接收到的来自客户端消息的字节数。
27. SQL*Net message from dblink
这个等待事件和SQL*Net message from client相同,不过它表示的是数据库通过dblink 访问另一个数据库时,他们之间会建立一个会话,这个等待事件发生在这个会话之间的通信过程中。
这个等待事件也是一个空闲等待事件。
这个事件包含两个参数:
Driver id: 服务器端和客户端连接使用的协议信息。
#bytes: 服务器端通过dblink 收到的来自另一个服务器端消息的字节数。
28. SQL*Net message to client
这个等待事件发生在服务器端向客户端发送消息的时候。 当服务器端向客户端发送消息产生等待时,可能的原因是用户端太繁忙,无法及时接收服务器端送来的消息,也可能是网络问题导致消息无法从服务器端发送到客户端。
这个等待事件有两个参数:
Driver id: 服务器端和客户端连接使用的协议信息。
#bytes: 服务器端向客户端发送消息的字节数。
29.SQL*Net message to dblink
这个等待事件和SQL*Net message to client 相同,不过是发生在数据库服务器和服务器之间的等待事件,产生这个等待的原因可能是远程服务器繁忙,而无法及时接收发送过来的消息,也可能是服务器之间网络问题导致消息无法发送过来。
这个等待时间包含两个参数:
Driver id: 服务器端和客户端连接使用的协议信息。
#bytes: 服务器端通过dblink发送给另一个服务器消息的字节数。
30. SQL*Net more data from client
服务器端等待用户发出更多的数据以便完成操作,比如一个大的SQL文本,导致一个SQL*Net 数据包无法完成传输,这样服务器端会等待客户端把整个SQL 文本发过来在做处理,这时候就会产生一个SQL*Net more data from client 等待事件。
这个等待时间包含两个参数:
Driver id: 服务器端和客户端连接使用的协议信息。
#bytes: 服务器端从客户端接收到消息的字节数。
31. SQL*Net more data from dblink
在一个分布式事务中,SQL 分布在不同的数据库中执行,远程数据库执行完毕后将结果通过dblink返给发出SQL的数据库,在等待数据从其他数据库中通过dblink传回的过程中,如果数据在远程数据库上处理时间很久,或者有大量的结果集需要返回,或者网络性能问题都会产生SQL*Net more data from dblink 等待事件,它的意思是本地数据库需要等到所有的数据从远程处理完毕通过dblink传回后,才可以在本机继续执行操作。
这个等待时间包含两个参数:
Driver id: 服务器端和客户端连接使用的协议信息。
#bytes: 服务器端通过dblink发送给另一个服务器消息的字节数。
32.SQL*Net more data to client
当服务器端有太多的数据需要发给客户端时,可能会产生SQL*Net more data to client等待事件,也可能由于网络问题导致服务器无法及时地将信息或者处理结果发送给客户端,同样会产生这个等待。
这个等待时间包含两个参数:
Driver id: 服务器端和客户端连接使用的协议信息。
#bytes: 服务器端向客户端发送消息的字节数。
33. SQL*Net more data to dblink
这个等待事件和SQL*Net more data to client 等待时间基本相同,只不过等待发生在分布式事务中,即本地数据库需要将更多的数据通过dblink发送给远程数据库。由于发送的数据太多或者网络性能问题,就会出现SQL*Net more data to dblink等待事件。
这个等待时间包含两个参数:
Driver id: 服务器端和客户端连接使用的协议信息。
#bytes: 服务器端通过dblink发送给另一个服务器消息的字节数。