dictmatch
基本数据结构及算法
dictmatch
其实是实现了最简单的
Trie
树的算法,而且并没有进行穿线改进,因此其是需要回朔的。但是其使用
2
个表来表示
Trie
树,并对其占用空间大的问题进行了很大的优化,特点是在建树的时候比较慢,但在查询的时候非常快。而且其使用的
hash
算法也值得一讲。
1.
字典数据结构:
typedef struct _DM_DICT
{
char* strbuf; // buffer for store word result;
u_int
sbsize;
u_int sbpos; // the next position in
word buf
dm_entry_t* dentry; //
the dict entry list
u_int
desize;
u_int depos; // the first unused pos
in de list
u_int* seinfo; // the suffix entry
list
u_int
seisize;
u_int
seipos;
dm_inlemma_t* lmlist;
// the lemma list
u_int
lmsize;
u_int lmpos; // the first unused pos
in lemma list
u_int
entrance;
}dm_dict_t;
//lemma structure for dict
typedef struct _DM_INLEMMA
{
u_int
len;
u_int
prop;
u_int
bpos;
}dm_inlemma_t;
typedef struct _DM_ENTRY
{
u_int
value;
u_int
lemma_pos;
u_int
suffix_pos;
}dm_entry_t;
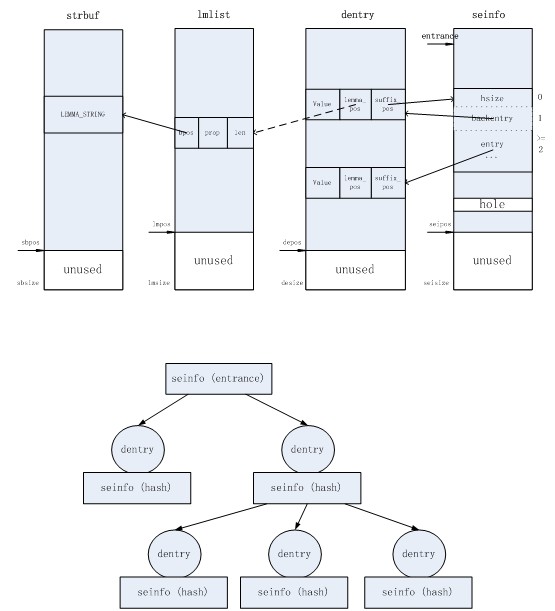
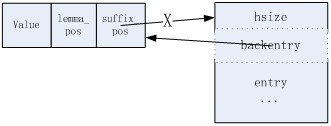
其中,
dentry
可以认为存放树的每个节点,
seinfo
可以认为存放每个节点的子树的指针列表(即后继块),
lmlist
存放完成匹配对应的某模式,而
strbuf
记录所有模式的字符串内容。
每个表的空间都预先开好,以
xxxsize
为大小。而
xxxpos
指针之前是已用空间,之后是未使用空间。
seinfo
中,每个后继块首字节放的是该后继块的
hash
表大小,第二个字节指向其属主
dentry
节点,第三个字节开始是存放子树指针的
hash
表。因此,每个后继块的大小为
hsize+2
。
entrance
指向了虚根节点所引出的每棵树的指针列表,也就是整个
Trie
树的入口。
图示:
此数据结构优点:
结构简单,利于存入和读取二进制文件,节约内存,内存分配次数较少,搜索的时候寻找子节点最快
此数据结构缺点:
不够直观,需要复杂的手动维护,建树时间较长
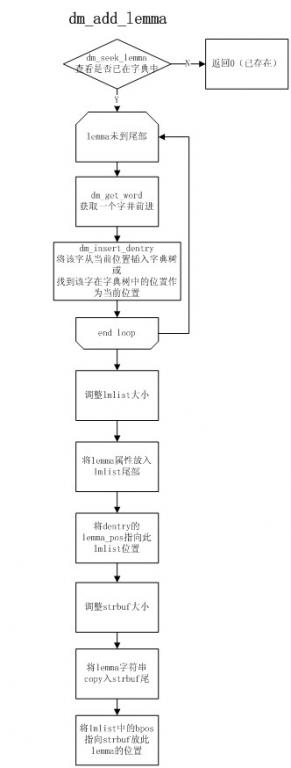
2.
建树算法:(
lemma
指得就是一个模式)
3.
搜索模式匹配
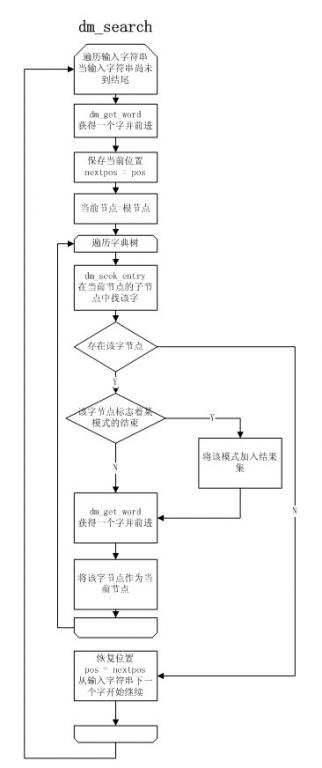
关键策略
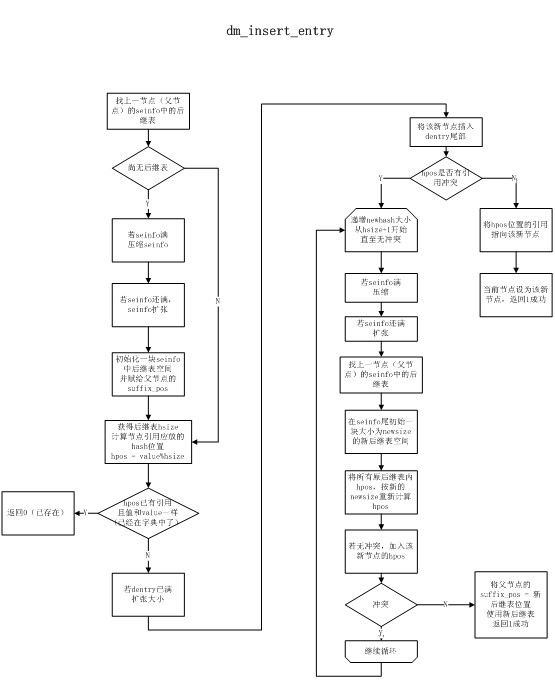
1.
解决
hash
冲突
解决后缀表中的
hash
冲突是非常重要的,因为在策略中通过
hpos = value%hsize
直接找到存放指向
dentry
的引用的位置,而没有考虑冲突的情况,因此必须在加入该
hash
表时解决。
方法也很简单,当出现冲突则不断增长
hash size
的大小,重新计算所有该后缀表中的
hash
值,直至无冲突。由于
size
变大因此原位置必然无法容纳新后缀表,需要在
seinfo
的尾部添加新表,而原表废弃不用,就造成了一个空洞。这也是需要压缩的原因。
2.
seinfo
压缩算法
从前到后遍历所有的后缀表块,检查是否是有效的
无效:其
backentry
所指向的节点的
suffix_pos
不是自己,或
backentry
指向
DM_DENTRY_FIRST
(代表是根后缀表块)但
entrance
指向的不是自己。
当发现一块有效的后缀表块,而其前面有若干块无效的后缀表块时,将这块有效后缀表块
copy
到前面覆盖原来无效的位置,并更新
backentry
指向的
dentry
的
suffix_pos
。这样就可以填充掉所有的空洞,将所有的可用空间都留在
sepos
之后。
3.
编码
由于采用
GB18030
编码格式,因此一个字可能是
1
字节、
2
字节、
4
字节
1
字节:
0x00~0x7F
ASCII
2
字节:
0x81~0xFE
0x40~0x7E/0x80~0xFE
GBK
传统
4
字节:
0x81~0xFE
0x30~0x39 0x81~0xFE 0x30~0x39
GB
新增(日韩文)
dm_get_word
通过遍历字符决定下一个字是多少字节之后,并将当前字拼成
u_int
。
4.
各表初始大小
strsize: 20*lemma_num [char]
desize: 2*lemma_num [struct]
sesize: 8*lemma_num [uint]
lmsize: lemma_num
[struct]
每次扩张都×
2
每新建一个
seinfo
中的后继块,默认大小为
3
个
u_int
,一个放
hsize
,一个放
backentry
,一个放
1
个后继节点。
5.
search
|
参数 |
DM_OUT_FMM |
DM_OUT_ALL |
|
dm_search |
正向最大匹配的所有模式 |
匹配(含重叠和包含)的所有模式 |
|
dm_search_prop |
正向最大匹配的所有模式的 |
匹配(含重叠和包含)的所有模式的 |
|
dm_has_word |
正向最大匹配含有特定属性的子串,如果是多个属性值或在一起,任意一个属性符合条件即返回 |
匹配(含重叠和包含)的所有模式含有特定属性的子串,如果是多个属性值或在一起,任意一个属性符合条件即返回 |
6.
为了使
32
位的字典在
64
位机器内使用,因此为了,将词典内部词条的结构和切词结构独立开了(以前是一个结构),分别是
dm_inlemma_t
和
dm_lemma_t
。区别在于,
dm_inlemma_t
结构中只有
int
,而
dm_lemma_t
中有
int
和
char*
。当写入文件时,是整个结构一起写入,而其中
char*
是一个指针在
32
位和
64
位所占用的空间不同,最终在读取的时候会出现兼容性问题。所以不要将指针直接写入文件数据中。
可能的改进
1.
进行穿线,引入跳转路径。基本的想法就是,在
dentry
中新加入一个域
failjump
,指向另一个跳转的
dentry
节点,当
Trie
树匹配在某节点失败时,转向
failjump
域指向的新节点再进行一次或若干次匹配。这样可以做到对目标字符串无回朔,而不是现在的匹配失败后必须进行回朔。同时,由于穿线是建完树再穿,可以兼容老的字典。
failjump
的建立算法:在完成建立树之后:
1)
根节点的孩子节点
failjump =
根节点
DM_DENTRY_FIRST
2)
广度遍历树,对当前节点
current
的一个子节点
child
:
a)
fail = current;
b)
while(fail !=
根节点
DM_DENTRY_FIRST
)
{
fail=fail.failjump;
entry = fail
节点的孩子中
value
等于
child.value
的节点
;
if(entry
存在
) break;
}
c)
if(entry
存在
) child.failjump = entry;
d)
else child.failjump =
根节点
DM_DENTRY_FIRST;
2.
转换成
UNICODE
之类的定长编码,(实际上
dm_get_word
已经做过类似的这一遍),然后使用
WM
算法进行计算。因为对
GB
编码采用
WM
算法可能会有误匹配,例如:
0xD7 0xD6 0xB7 0xFB
字符
0xD6 0xB7
址
因此需要转换成
UNICODE
或
UTF8,
他们没有错字的问题。转换需要遍历一遍待匹配串,复杂度为
O(n)
。因为
WM
算法一般来说快于
Trie
树,因此总体来说一般不会比
Trie
树慢。
另一种可能是,如果在大部分情况下,都不会匹配到任何模式的话,则可以使用
GB
编码直接使用
WM
算法进行匹配,如果出现
WM
匹配成功,再次进行确认匹配(逐字分析),这样可以剔除掉误匹配的情况。