内存池技术畅想
内容:
本文将介绍几种常用的内存池技术的实现,这是我最近学习各大开源的内存池技术遗留下来的笔记,其主要内容包括:
- STL内存池以及类STL内存池实现
- Memcached内存池实现
- 固定规格内存池实现
- Nginx内存池实现
一.类STL的内存池实现方式
SGI STL的内存池分为一级配置器和二级配置器,
一级配置器主要处理分配空间大小大于128Byte的需求,其内部实现就是直接使用malloc realloc 和free.
二级配置器则使用使用free_list的数组链表的方式来管理内存,SGI的Allocate最小的分辨单位为8Byte,其free_list数组存着8*n(n=1...16)大小内存的首地址,大小同样的内存块使用链表的形式相连
free_list[0] --------> 8 byte
free_list[1] --------> 16 byte
free_list[2] --------> 24 byte
free_list[3] --------> 32 byte
... ...
free_list[15] -------> 128 byte
因为其对内存的管理的最小分辨度为8Byte,所以当我们申请的内存空间不是8的倍数的时候,内存池会将其调整为8的倍数大小,这叫内存对齐。当然这也免不了带来内存浪费,例如我们只需要一个10Byte的大小,内存池经过内存对齐后,会给我们一个16Byte的大小,而剩余的6Byte,在这次使用中根本没有用到。(对于chunk_allocate的优化请见探究操作系统的内存分配(malloc)对齐策略一文的末尾处)
类STL的内存池一般都有如下API
void* refill(size_t n) //内部函数,用于allocate从free_list中未找到可使用的块时调用
这种内存池的工作流程大致如下:
- 外部调用 allocate向内存池申请内存
- allocate通过内存对齐的方式在free_list找到合适的内存块链表头
- 判断链表头是否为NULL,为NULL则表示没有此规格空闲的内存,如果不为NULL,则返那块内存地址,并将此块内存地址移除它对应的链表
- 如果为NULL,则调用refill在freelist上挂载20个此规格的内存空间(形成链表),也就是保证此规格的内存空间下次请求时够用
- refill的内部调用了chunk_alloc函数,chunk_alloc的职责就是负责内存池的所有内存的生产,在生产的时候他为了保证下次能有内存用,所以会将空间*2,所以这个申请流程总的内存消耗为:(对需求规格内存对齐后的大小)*20*2
- 当第一次调用chunk_alloc(32,10)的时候,表示我要申请10块__Obje(free_list), 每块大小32B,此时,内存池大小为0,从堆空间申请32*20的大小的内存,把其中32*10大小的分给free_list[3]。
- 我再次申请64*5大小的空间,此时free_list[7]为0, 它要从内存池提取内存,而此时内存池剩下320B,刚好填充给free_list[7],内存池此时大小为0。
- 第三次请求72*10大小的空间,此时free_list[8]为0,它要从内存池提取内存,此时内存池空间不足,再次从堆空间申请72*20大小的空间,分72*10给free_list用。
首次申请20Byte后的状态图:
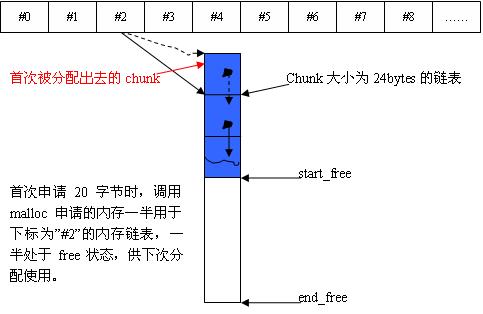
在未设置预分配的STL内存池中,某个中间状态的整体图

由于STL源码可阅读性不强,各种宏等等满目不堪,所以我这里就不贴SGI
的源码了,我在这里贴一个简单易懂的山寨版本, 基本的思路是一模一样的,这个实现没有了一级和二级配置器,而是在需要的时候直接malloc或者从free_list找。
 View
ViewCode
二.MemCached内存池实现
与类STL内存池不同的是, 用于缓存的内存池不是解决小对象的内存分配可能导致堆内存碎片多的问题,缓存内存池要为缓存系统的所有存储对象分配空间,无论大小。因为缓存系统通常对其占用的最大内存有限制,所以也就不能在没有空间用的时候随便malloc来实现了。 MemCached的内存池的基本想法是避免重复大量的初始化和清理操作。

特定大小的chunk的组。

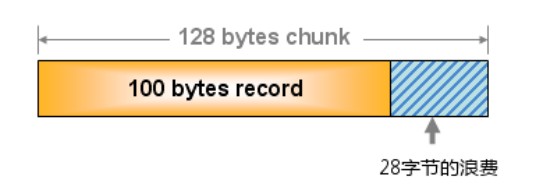
Memcached的内存分配以page为单位,默认情况下一个page是1M ,可以通过-I参数在启动时指定。如果需要申请内存 时,memcached会划分出一个新的page并分配给需要的slab区域。Memcached并不是将所有大小的数据都放在一起的,而是预先将数据空间划分为一系列slabs,每个slab只负责一定范围内的数据存储,其大小可以通过启动参数设置增长因子,默认为1.25,即下一个slab的大小是上一个的1.25倍。如
下图,每个slab只存储大于其上一个slab的size并小于或者等于自己最大size的数据。如下图所示,需要存储一个100Bytes的对象时,会选用112Bytes的Slab Classes

基于这种实现的内存池也会遇到STL内存池一样的问题,那就是资源的浪费,我只需要100Byte的空间,你却给了我128Bytes,剩余的28Bytes就浪费了
其主要API:
内的空间(被回收的空间),再检查 end_page_ptr 指针指向的的空闲空间,还是没有的空间的话,再试试分配新的内存。如果所有空间都用尽的时候,则返回NULL表示目前资源已经枯竭了。
关于MemCached还有个问题需要解释下,在预分配的场景下,有的同事认为MemCached不适合大量存储某个特定大小范围内的对象,他们认为预分配的条件下,每个SlabClasses的总大小是固定的(为一个Page),其实不是,MemCached预分配并不会消耗掉所有的内存,在请求空间的时候,如果发现这个型号的Chunks都被用完了,就会新增一个分页到这个Slab
Classes,所以是不会出现那位同事说的那个问题的...(可见代码slabs.c中do_slabs_alloc函数中do_slabs_newslab的调用)
三.固定大小内存池
上面两种内存池的实现,都会造成一定程度的内存浪费,如果我存的对象大小基本是固定的,尽管有很多不同的对象,有没有不会浪费内存的的简单方式呢?
既然需要存的对象大小是固定的,那么我们的内存池对于内存的管理可以这样实现:
};
char* chunk_alloc(size_t __size, int& __nobjs)//内部函数,用于分配一个大块
void* refill(size_t n) //内部函数,用于allocate从free_list中未找到可使用的块时调用
};
这样的实现对于这个特定的需求非常好用,不回浪费掉剩余空间,但是这样的实现局限性就高了,我们不能用这个内存池来存储大小不定的对象(如string),如果用了,此内存池形同虚设,并且还浪费内存,所以具体怎么选择还是要看需求来定...
http://blog.csdn.net/v_july_v/article/details/7040425http://bbs.chinaunix.net/thread-3626006-1-1.html;http://blog.csdn.net/livelylittlefish/article/details/6586946;http://blog.chinaunix.net/space.php?uid=7201775;淘宝数据共享平台博客:http://www.tbdata.org/archives/1390
晚了,睡觉!!!呵呵呵...




参考资料:http://www.cnblogs.com/sld666666/archive/2010/07/01/1769448.html
SGI STL 的内存管理
1. 好多废话
在分析完nginx的内存池之后,也想了解一下C++的内存管理,于是就很自然得想到STL。
STL是一个重量级的作品,据说当时的出现,完全可以说得上是一个划时代意义的作品。
泛型、数据结构和算法的分离、底耦合、高复用… 啊,废话不多说了,再说下去让人感觉像
王婆卖瓜了。
啊,还忘了得加上两位STL大师的名字来聊表我的敬意了。泛型大牛Alexander Stepanov
和 Meng Lee(李梦--让人浮想的名字啊)。
2. SLT 内存的分配
以一个简单的例子开始。
我们想知道的时候, 当vec声明的时候和push_back的时候,是怎么分配的。
其实对于一个标准的STL 容器,当Vetor<int> vec 的真实语句应该是 vetor<int, allocator<int>>vec,
allocator是一个标准的配置器,其作用就是为各个容器管理内存。这里需要注意的是在SGI STL中,有两个
配置器:allocator(标准的)和alloc(自己实现的,非常经典,这篇文章的主要目的就是为了分析它)。
3. 一个标准的配置器
要写一个配置器并不是很难,最重要的问题是如何分配和回收内存。下面看下一个标准(也许只能称为典型)
的配置器的实现:
#include <new>// for new #include <cstddef> // size_t #include <climits> // for unit_max #include <iostream> // for cerr using namespace std; namespace SLD { template <class T> class allocator { public: typedef T value_type; typedef T* pointer; typedef const T* const_pointer; typedef T& reference; typedef const T& const_reference; typedef size_t size_type; typedef ptrdiff_t difference_type; template <class U> struct rebind { typedef allocator<U> other; }; //申请内存 pointer allocate(size_type n, const void* hint = 0) { T* tmp = (T*)(::operator new((size_t)(n * sizeof(T)))); //operator new 和new operator是不同的 if (!tmp) cerr << "out of memory"<<endl; return tmp; } //释放内存 void deallocate(pointer p) { ::operator delete(p); } //构造 void construct(pointer p, const T& value) { new(p) T1(value); } //析构 void destroy(pointer p) { p->~T(); } //取地址 pointer address(reference x) { return (pointer)&x; } const_pointer const_address(const_reference x) { return (const_pointer)&x; } size_type max_size() const { return size_type(UINT_MAX/sizeof(T)); } }; }
注:代码有比较大的改动,因为主要是为了理解。
在使用的时候, 只需这样vector<int, SLD::allocator<int>>vec; 即可。
vetor便会自动调用我们的配置器分配内存了。
要自己写个配置器完全可以以这个类为模板。 而需要做的工作便是写下自己的 allocate和deallocate即可。
其实SGI的allocator 就是这样直接调用operator new 和::operator delete实现的,不过这样做的话效率就很
差了。
4. SGI STL中的alloc
4.1 SGI 中的内存管理
SGI STL默认的适配器是alloc,所以我们在声明一个vector的时候实际上是这样的
vetor<int, alloc<int>>vec. 这个配置器写得非常经典,下面就来慢慢分析它。
在我们敲下如下代码:
CSld* sld = new CSld;
的时候其实干了两件事情:(1) 调用::operator new 申请一块内存(就是malloc了)
(2) 调用了CSld::CSld();
而在SGI中, 其内存分配把这两步独立出了两个函数:allocate 申请内存, construct 调用构造函数。
他们分别在<stl_alloc.h>, <stl_construct.h> 中。
SGI的内存管理比上面所说的更复杂一些, 首先看一些SGI内存管理的几个主要文件,如下图所示:

<图1. SGI 内存管理>
在stl_construct.h中定义了两个全局函数construct()和destroy()来管理构造和析构。
在stl_allo.h中定义了5个配置器, 我们现在关心的是malloc_alloc_template(一级)
和default_alloc_template(二级)。在SGI中,如果用了一级配置器,便是直接使用了
malloc()和free()函数,而如果使用了二级适配器,则如果所申请的内存区域大于128b,
直接使用一级适配器,否则,使用二级适配器。
而stl_uninitialized.h中,则定义了一下全局函数来进行大块内存的申请和复制。
是不是和nginx中的内存池很相似啊,不过复杂多了。
4.2一级配置器:__malloc_alloc_template
上面说过, SGI STL中, 如果申请的内存区域大于128B的时候,就会调用一级适配器,
而一级适配器的调用也是非常简单的, 直接用malloc申请内存,用free释放内存。
可也看下如下的代码:
好了, 很简单把,只是对malloc,free, realloc简单的封装。
4.3 二级配置器:__default_alloc_template
按上文所说的,SGI的 __default_alloc_template 就是一个内存池了。
我们首先来看一下它的代码:
我们最关心的有三点:1. 内存池的创建。2.内存的分配。 3. 内存的释放。
4.3.1 SGI内存池的结构
在分析内存池的创建之前我们首先需要看下SGI内存池的结构。
在__default_alloc_template 内部,维护着这样一个结构体:
static _Obj* _S_free_list[]; //我就是这样用的
其实一个free_list 就是一个链表,如下图所示:

<图2. free_list的链表表示>
这里需要注意的有两点:
一:SGI 内部其实维护着16个free-list,对应管理的大小为8,16,32……128.
二:_Obj是一个union而不是sturct, 我们知道,union中的所有成员的引用在内存中的位置都是
相同的。这里我们用union就可以把每一个节点需要的额外的指针的负担消除掉。
4.3.2 二级配置器的内存分配:allocate
比如现在我要申请一块30B的空间,我要怎么申请呢?
首先会呼叫二级配置器, 调用 allocate,在allocate函数之内, 从对应的32B的链表中拿出空间。
如果对应的链表空间不足,就会先用填充至32B,然后用refill()冲洗填充该链表。
相应的代码如下:
下面画了一张图来帮助理解:

<图3. GetMemory>
4.3.3 二级配置器的内存释放:allocate
有内存的分配,当然得要释放了,下面就来看看是如何释放的:
4.3.4 二级配置器的内存池:chunk_alloc
前面说过,在分配内存时候如果空间不足会调用_S_refill函数,重新填充空间(ps:如果这是第一个的话,
就是创建了)。而_S_refill最终调用的又是chunk_alloc函数从内存池中提取内存空间。
首先我们看一下它的源代码:
区间[_S_start_free, _S_end_free)便是内存池的总空间(参考类:__default_alloc_template的定义)。
当申请一块内存时候,如果内存池总内存量充足,直接分配,不然就各有各的处理方法了。
下面举一个例子来简单得说明一下:
1. 当第一次调用chunk_alloc(32,10)的时候,表示我要申请10块__Obje(free_list), 每块大小32B,
此时,内存池大小为0,从堆空间申请32*20的大小的内存,把其中32*10大小的分给free_list[3](参考图3)。
2. 我再次申请64*5大小的空间,此时free_list[7]为0, 它要从内存池提取内存,而此时内存池剩下320B,
刚好填充给free_list[7],内存池此时大小为0。
3. 我第三次神奇一耳光72*10大小的空间,此时free_list[8]为0,它要从内存池提取内存,此时内存池空间
不足,再次从堆空间申请72*20大小的空间,分72*10给free_list用。
整一个SGI内存分配的大体流程就是这样了。
5. 小结
SIG的内存池比nginx中的复杂多了。简单得分析一下+写这篇文章花了我整整3个晚上的时间。
啊,我的青春啊。
nginx源码剖析(3)----nginx中的内存池
1.为什么需要内存池
为什么需要内存池?
a. 在大量的小块内存的申请和释放的时候,能更快地进行内存分配(对比malloc和free)
b.减少内存碎片,防止内存泄露。
2.内存池的原理
内存池的原理非常简单,用申请一块较大的内存来代替N多的小内存块,当有需要malloc一块
比较小的内存是,直接拿这块大的内存中的地址来用即可。
当然,这样处理的缺点也是很明显的,申请一块大的内存必然会导致内存空间的浪费,但是
比起频繁地malloc和free,这样做的代价是非常小的,这是典型的以空间换时间。
一个典型的内存池如下图所示:

图一:一个典型的内存池。
首先定义这样一个结构体:
一个内存池就是这样一连串的内存块组成。当需要用到内存的时候,调用此内存池定义好的接口
GetMemory(),而需要删除的时候FreeMemory()。
而GetMemory和FreeMemory干了什么呢?GetMemory只是简单返回内存池中可用空间的地址。
而FreeMemory干了两件事情:一: 改变UsedSize 的值,二:重新初始化这一内存区域。
3.nginx中的内存池
3.1 nginx内存池的结构表示
首先我们看一下nginx内存池的定义:


struct ngx_pool_s {
ngx_pool_data_t d;//表示数据区域
size_t max;//内存池能容纳数据的大小
ngx_pool_t * current;//当前内存池块(nginx中的内存池是又一连串的内存池链表组成的)
ngx_chain_t* chain;//主要为了将内存池连接起来
ngx_pool_large_t* large;//大块的数据
ngx_pool_cleanup_t* cleanup;//清理函数
ngx_log_t* log;//写log
};
nginx中的内存池和普通的有比较大的不同。nginx中的内存池是由N个内存池链表
组成的,当一个内存池满了以后,就会从下一个内存池中提取空间来使用。
对于ngx_pool_data_t的定义非常简单:
typedef struct {
u_char *last;
u_char *end;
ngx_pool_t *next;
ngx_uint_t failed;
} ngx_pool_data_t;
其中last表示当前数据区域的已经使用的数据的结尾。
end表示当前内存池的结尾。
next表示下一个内存池,前面已经说过,再nignx中,当一个内存池空间
不足的时候,它不会扩大其空间,而是再新建一个内存池,组成一个内存池链表。
failed标志申请内存的时候失败的次数。
在理解了这个结构体后面的就非常简单了。
current 表示当前的内存池。
chain表示内存池链表。
large表示大块的数据。
对于ngx_pool_large_t定义如下:
struct ngx_pool_large_s {
ngx_pool_large_t* next;
void* alloc;
};
此结构体的定义也是非常简单的。一个内存地址的指针已经指向下一个地址的指针。
这里再解释下为什么需要有large数据块。当一个申请的内存空间大小比内存池的大小还要大的时候,
malloc一块大的空间,再内存池用保留这个地址的指针。
Cleanup保持存着内存池被销毁的时候的清理函数。
typedef void (*ngx_pool_cleanup_pt)(void *data);struct ngx_pool_cleanup_s {
ngx_pool_cleanup_pt handler;
void* data;
ngx_pool_cleanup_t* next;
};
ngx_pool_cleanup_pt 是一个函数指针的典型用法,
在这个结果中保存这需要清理的数据指针以及相应的清理函数, 让内存池销毁
或其他需要清理内存池的时候,可以调用此结构体中的handler。
下面是我画的一张nginx的内存池的结构图。

<图1. ngx_pool 结构体>
3.2 nginx内存池源代码分析
要大体了解一个内存池,只需要了解其池子的创建,内存的分配以及池子的销毁即可。下面就分析下
ngx_pool_t的这个3个方面。注:其中有些代码可能与ngx_pool中的源代码有所差异,但是整体意思
绝对是一样的,本人的修改,只是为了更好的分析,比如 我就把所有写log的过程都去掉了。
3.2.1 ngx_create_pool
创建一个内存池
nginx内存池的创建非常简单,申请一开size大小的内存,把它分配给 ngx_poo_t。
3.2.2 ngx_palloc
从内存池中分配内存.
这个函数从内存池用拿出内存,如果当前内存池已满,到下一个内存池,如果所有的内存池已满,
增加一个新的内存池,如果申请的内存超过了内存池的最大值,从*large中分配
3.3.3 ngx_destroy_pool
内存池的销毁
销毁一个内存池其实就是干了三件事, 调用清理韩式, 释放大块的内存,释放内存池,需要注意的
一点是在nginx中, 小块内存除了在内存池被销毁的时候都是不能被释放的。
3.3.4 ngx_palloc_block
前面说过,在nginx中,当内存池满了以后,会增加一个新的内存池。这个动作就是靠ngx_palloc_block
函数实现的。
这个函数就是申请了一块内存区域,变为一个内存池,然后把它连接到原来内存池的末尾。
3.3.5 ngx_palloc_large 和ngx_pfree
在nginx中,小块内存除了在内存池销毁之外是不能释放的,但是大块内存却可以,这两个
函数就是用来控制大块内存的申请和释放, 代码也非常简单,调用malloc申请内存,连接到
ngx_pool_large_t中 和 调用free释放内存。这里就不贴上代码了。
4. 小结
不知不觉,写了快一个下午的时间了,真快啊。
nginx的内存池的代码也先介绍到这里,其实nginx内存池功能强大,所以代码也比较复杂,
这里只是列出了内存池的大体流程,还有很到一部分代码未列出来。