数字计算机的世界就是0和1,所以一切要通过计算机进行计算和表达的信息都必须编码成0、1串。那么计算机中如何表示阿拉伯数字,英文字母、希腊字母、拉丁字母、中文字符、数学符号等呢。下面讲解计算机中如何对这些进行编码,以及现实中编码出现的历史。
按照先后顺序,计算机字符编码先后出现的是 ASCII、Extended ASCII、MBCS编码、UNICODE编码。
一、Standard ASCII(标准ASCII)
ASCII (American Standard Code for Information Interchange),是美国标准信息交换码,由美国国家标准局(ANSI)制定的,它已被国际标准化组织(ISO)定为国际标准,称为ISO 646标准。ASCII码适用于所有拉丁文字,它用7位二进制数进行编码(其最高位(bit7)被用做奇偶校验位),范围是(0x00-0x7F),可以表示128种不同的符号。 其中包括了阿拉伯数字0-9、英文字母a-z和大些的A-Z、数学运算符号、括号、标点、控制字符等。 这些已经满足了最初的需求,下面是ASCII码表

注:这128个Code中(从0开始编号,0-127),有些是可视的【0x20(Space)-0x7E(~)】,有些是非可视的【0x00-0x1F和0x7F(DEL)】。非可视字符基本用于控制字符,例如0x07,如果你输出到标准输出,那么计算机会发出“嘀”的响声;0x0D表示回车,0x0A表示换行,0x09表示Tab,等等。
二、Extended ASCII(扩展ASCII)
一个字节(0x00-0xFF)可以表示256种含义,标准ASCII使用了低128种。 为了能表示更多字符,各厂商制定了很多种ASCII码的扩展规范,于是形成了Extended ASCII,这不是标准ASCII的一部分。例如IBM定义的扩展编码,里面定义了很多的线条,主要用于进行文字形式的格式化显示。里面还包括了希腊字母和数学符号,以及带重音号的拉丁字母。该编码在字符终端下被广泛使用。

该IBM扩展字元集被烧进无数显示卡和印表机的ROM中,并被许多应用程式用於修饰其文字模式的显示方式。不过,该字元集并没有为所有使用拉丁字母表的西欧语言提供足够多的带重音字元,而且也不适用於Windows。Windows不需要图形字元,因为它有一个完全图形化的系统。
在Windows 1.0(1985年11月发行)中,Microsoft没有完全放弃IBM扩展字元集,但它已退居第二重要位置。因为遵循了ANSI草案和ISO标准,纯Windows字元集被称作「ANSI字元集」。 ANSI草案和ISO标准最终成为ANSI/ISO 8859-1-1987,即「American National Standard for Information Processing-8-Bit Single-Byte Coded Graphic Character Sets-Part 1: Latin Alphabet No 1」,通常也简写为「Latin 1」。
这是在图形界面中最广泛使用的扩展,其中包含欧洲各国语言中最常用的非英文字母,但毕竟只有128个字符,某些语言中的某些字母没有包含。如下表所示(编号为128~159的是一些控制字符,表中没有列出):
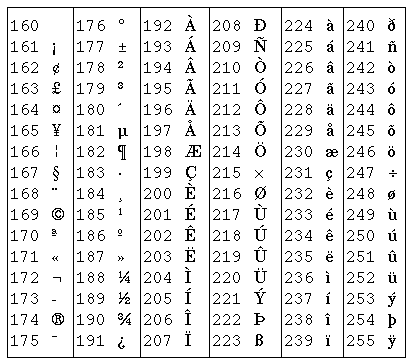
小结:
1、从上面的讲述看来,很明显0x00-0x7F的字节表示了一个确定的符号(根据ASCII码表),但是0x80-0xFF中某个数字对应的字节,在IBM的扩展ASCII码表和Latin-1中,就有不同的含义。 例如,0xD7在IBM扩展码中显示的是“两竖一横”的符号,但是在Latin-1(ISO 8859-1)中却是数学符号“×”。
Q:那么计算机怎样对待这样的重码情况呢,也就是将0xD7看成是“两竖一横”还是“×”?
A:答案是都可以。为了解决这个问题,需要引入码表(codepage)的概念。MS-DOS 3.3(1987年4月发行)向IBM PC用户引进了内码表(code page)的概念,Windows也使用此概念。内码表定义了字元的映射代码。最初的IBM字元集被称作内码表437,或者「MS-DOS Latin US)。「MS-DOS Latin 1」的是内码表850,它用附加的带重音字母代替了一些线形字元。其他内码表被其他语言定义。最低的128个代码总是相同的;较高的128个代码取决於定义内码表的语言。
2、乱码的原因
Q:为什么乱码
A:显示的乱码就是因为实际含义和显示的不一致。例如根据内码表437(IBM Extend ASCII)进行编码,但是显示的时候用内码表850(Latin-1)进行翻译,就出现问题了。
本文引用了网络上的一些概念,并进行了归结。如有不解,请搜索ASCII 扩展码,获取更多的资料。
未完待续。。。