自适应滤波器
自适应滤波器是能够根据输入信号自动调整性能进行数字信号处理的数字滤波器。作为对比,非自适应滤波器有静态的滤波器系数,这些静态系数一起组成传递函数。
对于一些应用来说,由于事先并不知道所需要进行操作的参数,例如一些噪声信号的特性,所以要求使用自适应的系数进行处理。在这种情况下,通常使用自适应滤波器,自适应滤波器使用反馈来调整滤波器系数以及频率响应。
总的来说,自适应的过程涉及到将代价函数用于确定如何更改滤波器系数从而减小下一次迭代过程成本的算法。价值函数是滤波器最佳性能的判断准则,比如减小输入信号中的噪声成分的能力。
随着数字信号处理器性能的增强,自适应滤波器的应用越来越常见,时至今日它们已经广泛地用于手机以及其它通信设备、数码录像机和数码照相机以及医疗监测设备中。
[编辑]下面图示的框图是最小均方滤波器(LMS)和递归最小平方(en:Recursive
least squares filter,RLS)这些特殊自适应滤波器实现的基础。框图的理论基础是可变滤波器能够得到所要信号的估计。结构框图

在开始讨论结构框图之前,我们做以下假设:
- 输入信号是所要信号
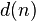 和干扰噪声
和干扰噪声  之和
之和
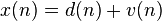
- 可变滤波器有有限脉冲响应结构,这样结构的脉冲响应等于滤波器系数。
 阶滤波器的系数定义为
阶滤波器的系数定义为
-
![\mathbf{w}_{n}=\left[w_{n}(0),\,w_{n}(1),\, ...,\,w_{n}(p)\right]^{T}](http://upload.wikimedia.org/math/0/7/4/074e16bf18eaa748719f59cd5b3152a0.png) .
.
- 误差信号或者叫作代价函数,是所要信号与估计信号之差
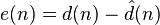
可变滤波器通过将输入信号与脉冲响应作卷积估计所要信号,用向量表示为
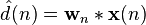
其中
![\mathbf{x}(n)=\left[x(n),\,x(n-1),\,...,\,x(n-p)\right]^{T}](http://upload.wikimedia.org/math/3/3/4/33419c642f6bbf163193ab84201a5a31.png)
是输入信号向量。另外,可变滤波器每次都会马上改变滤波器系数

其中  是滤波器系数的校正因子。自适应算法根据输入信号与误差信号生成这个校正因子,LMS
是滤波器系数的校正因子。自适应算法根据输入信号与误差信号生成这个校正因子,LMS
和 RLS 是两种不同的系数更新算法。
[编辑]例子
假设医院正在监测一个患者的心脏跳动,即心电图,这个信号受到
50 Hz (许多国家供电所用频率)噪声的干扰
剔除这个噪声的方法之一就是使用 50Hz 的陷波滤波器(en:notch
filter)对信号进行滤波。但是,由于医院的电力供应会有少许波动,所以我们假设真正的电力供应可能会在 47Hz 到 53Hz 之间波动。为了剔除 47 到 53Hz 之间的频率的静态滤波器将会大幅度地降低心电图的质量,这是因为在这个阻带之内很有可能就有心脏跳动的频率分量。
为了避免这种可能的信息丢失,可以使用自适应滤波器。自适应滤波器将患者的信号与电力供应信号直接作为输入信号,动态地跟踪噪声波动的频率。这样的自适应滤波器通常阻带宽度更小,这就意味着这种情况下用于医疗诊断的输出信号就更加准确。
[编辑]自适应滤波器的应用
- 通道均衡
- 通道辨识(en:Channel
identification) - 噪声消除(en:Noise
cancellation) - 信号预测
- 自适应反馈消除(en:Adaptive
Feedback Cancellation)
/*
* Copyright (c) 2008-2011 Zhang Ming (M. Zhang), zmjerry@163.com
*
* This program is free software; you can redistribute it and/or modify it
* under the terms of the GNU General Public License as published by the
* Free Software Foundation, either version 2 or any later version.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
*
* 1. Redistributions of source code must retain the above copyright notice,
* this list of conditions and the following disclaimer.
*
* 2. Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
*
* This program is distributed in the hope that it will be useful, but WITHOUT
* ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
* FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for
* more details. A copy of the GNU General Public License is available at:
* http://www.fsf.org/licensing/licenses
*/
/*****************************************************************************
* lms.h
*
* Least Mean Square Adaptive Filter.
*
* Least mean squares (LMS) algorithms are a class of adaptive filter used
* to mimic a desired filter by finding the filter coefficients that relate
* to producing the least mean squares of the error signal (difference
* between the desired and the actual signal). It is a stochastic gradient
* descent method in that the filter is only adapted based on the error at
* the current time.
*
* This file implement three types of the LMS algorithm: conventional LMS,
* algorithm, LMS-Newton algorhm and normalized LMS algorithm.
*
* Zhang Ming, 2010-10, Xi'an Jiaotong University.
*****************************************************************************/
#ifndef LMS_H
#define LMS_H
#include <vector.h>
#include <matrix.h>
namespace splab
{
template<typename Type>
Type lms( const Type&, const Type&, Vector<Type>&, const Type& );
template<typename Type>
Type lmsNewton( const Type&, const Type&, Vector<Type>&,
const Type&, const Type&, const Type& );
template<typename Type>
Type lmsNormalize( const Type&, const Type&, Vector<Type>&,
const Type&, const Type& );
#include <lms-impl.h>
}
// namespace splab
#endif
// LMS_H
实现文件:
/*
* Copyright (c) 2008-2011 Zhang Ming (M. Zhang), zmjerry@163.com
*
* This program is free software; you can redistribute it and/or modify it
* under the terms of the GNU General Public License as published by the
* Free Software Foundation, either version 2 or any later version.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
*
* 1. Redistributions of source code must retain the above copyright notice,
* this list of conditions and the following disclaimer.
*
* 2. Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
*
* This program is distributed in the hope that it will be useful, but WITHOUT
* ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
* FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for
* more details. A copy of the GNU General Public License is available at:
* http://www.fsf.org/licensing/licenses
*/
/*****************************************************************************
* lms-impl.h
*
* Implementation for LMS Adaptive Filter.
*
* Zhang Ming, 2010-10, Xi'an Jiaotong University.
*****************************************************************************/
/**
* The conventional LMS algorithm, which is sensitive to the scaling of its
* input "xn". The filter order p = wn.size(), where "wn" is the Weight
* Vector, and "mu" is the iterative setp size, for stability "mu" should
* belong to (0, Rr[Rxx]).
*/
template <typename Type>
Type lms( const Type &xk, const Type &dk, Vector<Type> &wn, const Type &mu )
{
int filterLen = wn.size();
static Vector<Type> xn(filterLen);
// update input signal
for( int i=filterLen; i>1; --i )
xn(i) = xn(i-1);
xn(1) = xk;
// get the output
Type yk = dotProd( wn, xn );
// update the Weight Vector
wn += 2*mu*(dk-yk) * xn;
return yk;
}
/**
* The LMS-Newton is a variant of the LMS algorithm which incorporate
* estimates of the second-order statistics of the environment signals is
* introduced. The objective of the algorithm is to avoid the slowconvergence
* of the LMS algorithm when the input signal is highly correlated. The
* improvement is achieved at the expense of an increased computational
* complexity.
*/
template <typename Type>
Type lmsNewton( const Type &xk, const Type &dk, Vector<Type> &wn,
const Type &mu, const Type &alpha, const Type &delta )
{
assert( 0 < alpha );
assert( alpha <= Type(0.1) );
int filterLen = wn.size();
Type beta = 1-alpha;
Vector<Type> vP(filterLen);
Vector<Type> vQ(filterLen);
static Vector<Type> xn(filterLen);
// initialize the Correlation Matrix's inverse
static Matrix<Type> invR = eye( filterLen, Type(1.0/delta) );
// update input signal
for( int i=filterLen; i>1; --i )
xn(i) = xn(i-1);
xn(1) = xk;
Type yk = dotProd(wn,xn);
// update the Correlation Matrix's inverse
vQ = invR * xn;
vP = vQ / (beta/alpha+dotProd(vQ,xn));
invR = (invR - multTr(vQ,vP)) / beta;
// update the Weight Vector
wn += 2*mu * (dk-yk) * (invR*xn);
return yk;
}
/**
* The conventional LMS is very hard to choose a learning rate "mu" that
* guarantees stability of the algorithm. The Normalised LMS is a variant
* of the LMS that solves this problem by normalising with the power of
* the input. For stability, the parameter "rho" should beong to (0,2),
* and "gamma" is a small number to prevent <Xn,Xn> == 0.
*/
template <typename Type>
Type lmsNormalize( const Type &xk, const Type &dk, Vector<Type> &wn,
const Type &rho, const Type &gamma )
{
assert( 0 < rho );
assert( rho < 2 );
int filterLen = wn.size();
static Vector<Type> sn(filterLen);
// update input signal
for( int i=filterLen; i>1; --i )
sn(i) = sn(i-1);
sn(1) = xk;
// get the output
Type yk = dotProd( wn, sn );
// update the Weight Vector
wn += rho*(dk-yk)/(gamma+dotProd(sn,sn)) * sn;
return yk;
}
测试代码:
/*****************************************************************************
* lms_test.cpp
*
* LMS adaptive filter testing.
*
* Zhang Ming, 2010-10, Xi'an Jiaotong University.
*****************************************************************************/
#define BOUNDS_CHECK
#include <iostream>
#include <iomanip>
#include <lms.h>
using namespace std;
using namespace splab;
typedef double Type;
const int N = 50;
const int order = 1;
const int dispNumber = 10;
int main()
{
Vector<Type> dn(N), xn(N), yn(N), wn(order+1);
for( int k=0; k<N; ++k )
{
xn[k] = Type(cos(TWOPI*k/7));
dn[k] = Type(sin(TWOPI*k/7));
}
int start = max(0,N-dispNumber);
Type xnPow = dotProd(xn,xn)/N;
Type mu = Type( 0.1 / ((order+1)*xnPow) );
Type rho = Type(1.0), gamma = Type(1.0e-9), alpha = Type(0.08);
cout << "The last " << dispNumber << " iterations of Conventional-LMS:" << endl;
cout << "observed" << "\t" << "desired" << "\t\t" << "output" << "\t\t"
<< "adaptive filter" << endl << endl;
wn = 0;
for( int k=0; k<start; ++k )
yn[k] = lms( xn[k], dn[k], wn, mu );
for( int k=start; k<N; ++k )
{
yn[k] = lms( xn[k], dn[k], wn, mu );
cout << setiosflags(ios::fixed) << setprecision(4)
<< xn[k] << "\t\t" << dn[k] << "\t\t" << yn[k] << "\t\t";
for( int i=0; i<=order; ++i )
cout << wn[i] << "\t";
cout << endl;
}
cout << endl << endl;
cout << "The last " << dispNumber << " iterations of LMS-Newton:" << endl;
cout << "observed" << "\t" << "desired" << "\t\t" << "output" << "\t\t"
<< "adaptive filter" << endl << endl;
wn = 0;
for( int k=0; k<start; ++k )
yn[k] = lmsNewton( xn[k], dn[k], wn, mu, alpha, xnPow );
for( int k=start; k<N; ++k )
{
yn[k] = lmsNewton( xn[k], dn[k], wn, mu, alpha, xnPow );
cout << setiosflags(ios::fixed) << setprecision(4)
<< xn[k] << "\t\t" << dn[k] << "\t\t" << yn[k] << "\t\t";
for( int i=0; i<=order; ++i )
cout << wn[i] << "\t";
cout << endl;
}
cout << endl << endl;
cout << "The last " << dispNumber << " iterations of Normalized-LMS:" << endl;
cout << "observed" << "\t" << "desired" << "\t\t" << "output" << "\t\t"
<< "adaptive filter" << endl << endl;
wn = 0;
for( int k=0; k<start; ++k )
yn[k] = lmsNormalize( xn[k], dn[k], wn, rho, gamma );
for( int k=start; k<N; ++k )
{
yn[k] = lmsNormalize( xn[k], dn[k], wn, rho, gamma );
cout << setiosflags(ios::fixed) << setprecision(4)
<< xn[k] << "\t\t" << dn[k] << "\t\t" << yn[k] << "\t\t";
for( int i=0; i<=order; ++i )
cout << wn[i] << "\t";
cout << endl;
}
cout << endl << endl;
cout << "The theoretical optimal filter is:\t\t" << "-0.7972\t1.2788"
<< endl << endl;
return 0;
}
http://www.360doc.com/content/11/0808/16/825929_138929663.shtml