关于这个话题,博客园已经有多个版本了
这几个版本中,最具有实用性的应该是Pymining版,Pymining可以生成模型,便于复用,同时也讲解的较为清楚,感兴趣的可以去看下原文。
Pymining是基于python的,作为c#控,决定参考Pymining写一个c#版本的分类器,目前完成了朴素贝叶斯分类的移植工作。
下面是使用示例:
var loadModel = ClassiferSetting.LoadExistModel;
//loadModel = true;
Text2Matrix text2Matrix = new Text2Matrix(loadModel);
ChiSquareFilter chiSquareFilter = new ChiSquareFilter(loadModel);
NaiveBayes bayes = new NaiveBayes(loadModel);
if (!loadModel)
{
Console.WriteLine("开始模型训练...");
//var matrix = text2Matrix.CreateTrainMatrix(new SogouRawTextSource(@"E:\语料下载程序\新闻下载\BaiduCrawl\Code\HtmlTest\Jade.Util\Classifier\SogouC.reduced.20061127\SogouC.reduced\Reduced"));
var matrix = text2Matrix.CreateTrainMatrix(new TuangouTextSource());
Console.WriteLine("卡方检验中...");
chiSquareFilter.TrainFilter(matrix);
Console.WriteLine("训练模型中...");
bayes.Train(matrix);
}
var totalCount = 0;
var accurent = 0;
var tuangouTest = new TuangouTextSource(@"E:\语料下载程序\新闻下载\BaiduCrawl\Code\HtmlTest\Jade.Util\Classifier\test.txt");
while (!tuangouTest.IsEnd)
{
totalCount++;
var raw = tuangouTest.GetNextRawText();
Console.WriteLine("文本:" + raw.Text);
Console.WriteLine("标记结果:" + raw.Category);
var category = GetCategory(raw.Text, bayes, chiSquareFilter, text2Matrix);
Console.WriteLine("结果:" + category);
if (raw.Category == category)
{
accurent++;
}
}
Console.WriteLine("正确率:" + accurent * 100 / totalCount + "%");
Console.ReadLine();
结果:
![XMK3M@2KJO~)W4R~M}XHA]S](http://images.cnblogs.com/cnblogs_com/xiaoqi/201204/201204011540572786.jpg "XMK3M@2KJO~)W4R~M}XHA]S")
为了便于大家理解,下面将主要的模块和流程进行介绍。
流程图
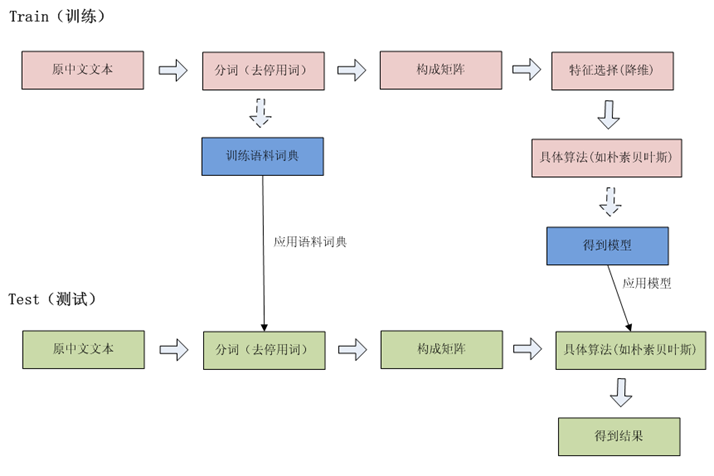
文本模式分类一般的过程就是对训练集提取特征,对于文本来说就是分词,分出来的结果通常比较多,不能全部用来做特征,需要对特征进行降维,然后在使用分类算法(如贝叶斯)生成模型,并以模型来对需要进行分类的文本进行预测。
程序结构
分类程序主要由配置模块,分词模块,特征选取模块,分类模块等几个部分组成,下面逐一介绍:
配置模块
python版本的程序用一个xml来存储配置信息,c#版本继续沿用这个配置信息
 View Code
View Code

<?xml version="1.0" encoding="utf-8" ?>
<config>
<__global__>
<term_to_id>model/term_to_id</term_to_id>
<id_to_term>model/id_to_term</id_to_term>
<id_to_doc_count>model/id_to_doc_count</id_to_doc_count>
<class_to_doc_count>model/class_to_doc_count</class_to_doc_count>
<id_to_idf>model/id_to_idf</id_to_idf>
<newid_to_id>model/newid_to_id</newid_to_id>
<class_to_id>model/class_to_id</class_to_id>
<id_to_class>model/id_to_class</id_to_class>
</__global__>
<__filter__>
<rate>0.3</rate>
<method>max</method>
<log_path>model/filter.log</log_path>
<model_path>model/filter.model</model_path>
</__filter__>
<naive_bayes>
<model_path>model/naive_bayes.model</model_path>
<log_path>model/naive_bayes.log</log_path>
</naive_bayes>
<twc_naive_bayes>
<model_path>model/naive_bayes.model</model_path>
<log_path>model/naive_bayes.log</log_path>
</twc_naive_bayes>
</config>
配置信息主要是存储模型文件相关的文件路径
读取xml就简单了,当然为了方便使用,我们建立几个类
View Code
/// <summary>
/// 全局配置信息
/// </summary>
public class GlobalSetting
{
public string TermToId { get; set; }
public string IdToTerm { get; set; }
public string IdToDocCount { get; set; }
public string ClassToDocCount { get; set; }
public string IdToIdf { get; set; }
public string NewidToId { get; set; }
public string ClassToId { get; set; }
public string IdToClass { get; set; }
}
/// <summary>
/// 卡方设置
/// </summary>
public class FilterSetting : TrainModelSetting
{
/// <summary>
/// 特征选取比例
/// </summary>
public double Rate { get; set; }
/// <summary>
/// avg max
/// </summary>
public string Method { get; set; }
}
public class TrainModelSetting
{
/// <summary>
/// 日志路径
/// </summary>
public string LogPath { get; set; }
/// <summary>
/// 模型路径
/// </summary>
public string ModelPath { get; set; }
}
/// <summary>
/// 贝叶斯设置
/// </summary>
public class NaiveBayesSetting : TrainModelSetting
{
}
另外,提供一个供程序访问配置信息的工具类
View ClassiferSetting分词
要提取特征,首先要进行分词,对c#来说,直接采用盘古分词就可以了,当然,还需要对盘古做下简单的封装
View Code
public class PanguSegment : ISegment
{
static PanguSegment()
{
PanGu.Segment.Init();
}
public List<string> DoSegment(string text)
{
PanGu.Segment segment = new PanGu.Segment();
ICollection<WordInfo> words = segment.DoSegment(text);
return words.Where(w=>w.OriginalWordType != WordType.Numeric).Select(w => w.Word).ToList();
}
}
另外,可以添加一个停用词过滤StopWordsHandler
View Code
public class StopWordsHandler
{
private static string[] stopWordsList = { " ", "的", "我们", "要", "自己", "之", "将", "后", "应", "到", "某", "后", "个", "是", "位", "新", "一", "两", "在", "中", "或", "有", "更" };
public static bool IsStopWord(string word)
{
for (int i = 0; i < stopWordsList.Length; ++i)
{
if (word.IndexOf(stopWordsList[i]) != -1)
return true;
}
return false;
}
public static void RemoveStopWord(List words)
{
words.RemoveAll(word => word.Trim() == string.Empty || stopWordsList.Contains(word));
}
}
读取训练集
分类不是随意做到的,而是要基于以往的知识,也就是需要通过训练集计算概率
为了做到普适性,我们定义一个RawText类来代表原始语料
public class RawText
{
public string Text { get; set; }
public string Category { get; set; }
}
然后定义接口IRawTextSource来代表训练集,看到IsEnd属性就知道这个接口怎么使用了吧?
public interface IRawTextSource
{
bool IsEnd { get; }
RawText GetNextRawText();
}
对于搜狗的语料集(点击下载),可以采用下面的方法读取
View Code
同样的,对于python版本的训练集格式,可以使用下面的类来读取
View Code构建矩阵
在介绍矩阵之前,还需要介绍一个对象GlobalInfo,用来存储矩阵计算过程中需要记录的数据,比如词语和id的映射
与python版本不同的是,为了方便访问,c#版本的GlobalInfo使用单例模式。
View Code
从这里开始进入核心部分
这一部分会构造一个m*n的矩阵,表示数据的部分,每一行表示一篇文档,每一列表示一个feature(单词)。
矩阵中的categories是一个m * 1的矩阵,表示每篇文档对应的分类id。
和python不同的是,我为了省事,矩阵对象还包含了一文档文类(罪过),另外为了方便查看特征词,特意添加了一个FeatureWords属性
View Code
public class Matrix
{
/// <summary>
/// 行数目 代表样本个数
/// </summary>
public int RowsCount { get; private set; }
/// <summary>
/// 列数目 代表词(特征)数目
/// </summary>
public int ColsCount { get; private set; }
/// <summary>
/// 用于记录文件的词数目[0] = 0,[1] = [0]+ count(1),[2] = [1]+count(2)
/// </summary>
public List<int> Rows;
/// <summary>
/// 用于记录词id(termId) 与Rows一起可以将文档区分开来
/// </summary>
public List<int> Cols;
/// <summary>
/// 与cols一一对应,记录单篇文章中term的次数
/// </summary>
public List<int> Vals;
/// <summary>
/// 记录每篇文章的分类,与Row对应
/// </summary>
public List<int> Categories;
public Matrix(List<int> rows, List<int> cols, List<int> vals, List<int> categories)
{
this.Rows = rows;
this.Cols = cols;
this.Vals = vals;
this.Categories = categories;
if (rows != null && rows.Count > 0)
this.RowsCount = rows.Count - 1;
if (cols != null && cols.Count > 0)
this.ColsCount = cols.Max() + 1;
}
private List<string> featureWords;
public List<string> FeatureWords
{
get
{
if (Cols != null)
{
featureWords = new List<string>();
Cols.ForEach(col => featureWords.Add(GlobalInfo.Instance.IdToTerm[col]));
}
return featureWords;
}
}
}
Matrix一定要理解清楚Row和Col分别代表什么,下面来看怎么生成矩阵,代码较长,请展开查看
View Code
public Matrix CreateTrainMatrix(IRawTextSource textSource)
{
var rows = new List<int>();
rows.Add(0);
var cols = new List<int>();
var vals = new List<int>();
var categories = new List<int>();
// 盘古分词
var segment = new PanguSegment();
while (!textSource.IsEnd)
{
var rawText = textSource.GetNextRawText();
if (rawText != null)
{
int classId;
// 处理分类
if (GlobalInfo.Instance.ClassToId.ContainsKey(rawText.Category))
{
classId = GlobalInfo.Instance.ClassToId[rawText.Category];
GlobalInfo.Instance.ClassToDocCount[classId] += 1;
}
else
{
classId = GlobalInfo.Instance.ClassToId.Count;
GlobalInfo.Instance.ClassToId.Add(rawText.Category, classId);
GlobalInfo.Instance.IdToClass.Add(classId, rawText.Category);
GlobalInfo.Instance.ClassToDocCount.Add(classId, 1);
}
categories.Add(classId);
var text = rawText.Text;
//分词
var wordList = segment.DoSegment(text);
// 去停用词
StopWordsHandler.RemoveStopWord(wordList);
var partCols = new List<int>();
var termFres = new Dictionary<int, int>();
wordList.ForEach(word =>
{
int termId;
if (!GlobalInfo.Instance.TermToId.ContainsKey(word))
{
termId = GlobalInfo.Instance.IdToTerm.Count;
GlobalInfo.Instance.TermToId.Add(word, termId);
GlobalInfo.Instance.IdToTerm.Add(termId, word);
}
else
{
termId = GlobalInfo.Instance.TermToId[word];
}
// partCols 记录termId
if (!partCols.Contains(termId))
{
partCols.Add(termId);
}
//termFres 记录termid出现的次数
if (!termFres.ContainsKey(termId))
{
termFres[termId] = 1;
}
else
{
termFres[termId] += 1;
}
});
partCols.Sort();
partCols.ForEach(col =>
{
cols.Add(col);
vals.Add(termFres[col]);
if (!GlobalInfo.Instance.IdToDocCount.ContainsKey(col))
{
GlobalInfo.Instance.IdToDocCount.Add(col, 1);
}
else
{
GlobalInfo.Instance.IdToDocCount[col] += 1;
}
});
//fill rows rows记录前n个句子的词语数目之和
rows.Add(rows[rows.Count - 1] + partCols.Count);
}
}
//fill GlobalInfo's idToIdf 计算idf 某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到
foreach (var termId in GlobalInfo.Instance.TermToId.Values)
{
GlobalInfo.Instance.IdToIdf[termId] =
Math.Log(d: (rows.Count - 1) / (GlobalInfo.Instance.IdToDocCount[termId] + 1));
}
this.Save();
this.IsTrain = true;
return new Matrix(rows, cols, vals, categories);
}
特征降维
选取适合的特征对提高分类正确率有重要的帮助作用,c#版本选取chi-square,即卡方检验
卡方计算公式:
t: term
c: category
X^2(t, c) = N * (AD - CB)^2
____________________
(A+C)(B+D)(A+B)(C+D)
A,B,C,D is doc-count
A: belong to c, include t
B: Not belong to c, include t
C: belong to c, Not include t
D: Not belong to c, Not include t
B = t's doc-count - A
C = c's doc-count - A
D = N - A - B - C
得分计算:
and score of t can be calculated by n
X^2(t) = sigma p(ci)X^2(t,ci) (avg)
i
X^2(t) = max { X^2(t,c) } (max)
下面是对应的代码代码执行完成后,会将选取出来的特征词写到日志文件中:
View Code
/// <summary>
/// 训练
/// 卡方计算公式:
/// t: term
/// c: category
/// X^2(t, c) = N * (AD - CB)^2
/// ____________________
/// (A+C)(B+D)(A+B)(C+D)
/// A,B,C,D is doc-count
/// A: belong to c, include t
/// B: Not belong to c, include t
/// C: belong to c, Not include t
/// D: Not belong to c, Not include t
///
/// B = t's doc-count - A
/// C = c's doc-count - A
/// D = N - A - B - C
/// and score of t can be calculated by next 2 formulations:
/// X^2(t) = sigma p(ci)X^2(t,ci) (avg)
/// i
/// X^2(t) = max { X^2(t,c) } (max)
/// """
/// </summary>
/// <param name="matrix"></param>
public void TrainFilter(Matrix matrix)
{
if (matrix.RowsCount != matrix.Categories.Count)
{
throw new Exception("ERROR!,matrix.RowsCount shoud be equal to matrix.Categories.Count");
}
var distinctCategories = matrix.Categories.Distinct().ToList();
distinctCategories.Sort();
//#create a table stores X^2(t, c)
// #create a table stores A(belong to c, and include t 创建二维数组
ChiTable = new List<List<double>>();
var data = new List<double>();
for (var j = 0; j < matrix.ColsCount; j++)
{
data.Add(0);
}
for (var i = 0; i < distinctCategories.Count; i++)
{
ChiTable.Add(data.AsReadOnly().ToList());
}
// atable [category][term] - count
ATable = ChiTable.AsReadOnly().ToList();
for (var row = 0; row < matrix.RowsCount; row++)
{
for (var col = matrix.Rows[row]; col < matrix.Rows[row + 1]; col++)
{
var categoryId = matrix.Categories[row];
var termId = matrix.Cols[col];
ATable[categoryId][termId] += 1;
}
}
// 总文档数
var n = matrix.RowsCount;
// 计算卡方
for (var t = 0; t < matrix.ColsCount; t++)
{
for (var cc = 0; cc < distinctCategories.Count; cc++)
{
var a = ATable[distinctCategories[cc]][matrix.Cols[t]]; // 属于分类cc且包含词t的数目
var b = GlobalInfo.Instance.IdToDocCount[t] - a; // 包含t但是不属于分类的文档 = t的总数-属于cc的数目
var c = GlobalInfo.Instance.ClassToDocCount[distinctCategories[cc]] - a; // 属于分类cc但不包含t的数目 = c的数目 - 属于分类包含t
var d = n - a - b - c; // 既不属于c又不包含t的数目
//#get X^2(t, c)
var numberator = (n) * (a * d - c * b) * (a * d - c * b) + 1;
var denominator = (a + c) * (b + d) * (a + b) * (c + d) + 1;
ChiTable[distinctCategories[cc]][t] = numberator / denominator;
}
}
// chiScore[t][2] : chiScore[t][0] = score,chiScore[t][1] = colIndex
var chiScore = new List<List<double>>();
for (var i = 0; i < matrix.ColsCount; i++)
{
var c = new List<double>();
for (var j = 0; j < 2; j++)
{
c.Add(0);
}
chiScore.Add(c);
}
// avg 函数时 最终得分 X^2(t) = sigma p(ci)X^2(t,ci) p(ci)为类别的先验概率
if (this.Method == "avg")
{
// 构造类别先验概率pc [category] - categoyCount/n
var priorC = new double[distinctCategories.Count + 1];
for (var i = 0; i < distinctCategories.Count; i++)
{
priorC[distinctCategories[i]] = (double)GlobalInfo.Instance.ClassToDocCount[distinctCategories[i]] / n;
}
// 计算得分
for (var t = 0; t < matrix.ColsCount; t++)
{
chiScore[t][1] = t;
for (var c = 0; c < distinctCategories.Count; c++)
{
chiScore[t][0] += priorC[distinctCategories[c]] * ChiTable[distinctCategories[c]][t];
}
}
}
else
{
//method == "max"
// calculate score of each t
for (var t = 0; t < matrix.ColsCount; t++)
{
chiScore[t][1] = t;
// 取最大值
for (var c = 0; c < distinctCategories.Count; c++)
{
if (chiScore[t][0] < ChiTable[distinctCategories[c]][t])
chiScore[t][0] = ChiTable[distinctCategories[c]][t];
}
}
}
// 比较得分
chiScore.Sort(new ScoreCompare());
chiScore.Reverse();
#region
var idMap = new int[matrix.ColsCount];
// add un-selected feature-id to idmap
for (var i = (int)(ClassiferSetting.FilterSetting.Rate * chiScore.Count); i < chiScore.Count; i++)
{
// 将未选中的标记为-1
var termId = chiScore[i][1];
idMap[(int)termId] = -1;
}
var offset = 0;
for (var t = 0; t < matrix.ColsCount; t++)
{
if (idMap[t] < 0)
{
offset += 1;
}
else
{
idMap[t] = t - offset;
GlobalInfo.Instance.NewIdToId[t - offset] = t;
}
}
this.IdMap = new List<int>(idMap);
#endregion
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.AppendLine("chiSquare info:");
stringBuilder.AppendLine("=======selected========");
for (var i = 0; i < chiScore.Count; i++)
{
if (i == (int)(ClassiferSetting.FilterSetting.Rate * chiScore.Count))
{
stringBuilder.AppendLine("========unselected=======");
}
var term = GlobalInfo.Instance.IdToTerm[(int)chiScore[i][1]];
var score = chiScore[i][0];
stringBuilder.AppendLine(string.Format("{0} {1}", term, score));
}
File.WriteAllText(ClassiferSetting.FilterSetting.LogPath, stringBuilder.ToString());
GlobalInfo.Instance.Save();
this.Save();
this.IsTrain = true;
}
贝叶斯算法
具体可以参见开头推荐的几篇文章,知道P(C|X) = P(X|C)P(C)/P(X)就可以了
下面是具体的实现代码
View Code
public List<List<double>> vTable { get; set; }public List<double> Prior { get; set; }
public void Train(Matrix matrix)
{
if (matrix.RowsCount != matrix.Categories.Count)
{
throw new Exception("ERROR!,matrix.RowsCount shoud be equal to matrix.Categories.Count");
}// #calculate prior of each class
// #1. init cPrior:
var distinctCategories = matrix.Categories.Distinct().ToList();
distinctCategories.Sort();
var cPrior = new double[distinctCategories.Count + 1];// 2. fill cPrior
matrix.Categories.ForEach(classid => cPrior[classid] += 1);//#calculate likehood of each term
// #1. init vTable: vTable[termId][Category]
vTable = new List<List<double>>();
for (var i = 0; i < matrix.ColsCount; i++)
{
var data = cPrior.Select(t => 0d).ToList();
vTable.Add(data);
}