Schema-Free MySQL vs NoSQL
By Ilya Grigorik on March 01, 2010
 Amidst
Amidst
the cambrian explosion of alternative database engines (aka, NoSQL) it is almost too easy to lose sight of the fact that the more established solutions, such as relational databases, still have a lot to offer: stable and proven code base, drivers and tools
for every conceivable language, and more features than any DBA cares to learn about. Not to mention that relational or not, they often times perform just as well as any other single instance key-value store when faced with large datasets - hence the reason
why Riak, Voldemort and others use InnoDB as their
data stores.
Granted, the “feature bloat” is also the reason why a rewrite can be a good idea, but it also feels like this gray zone is too often overlooked in the NoSQL community - just because you are “NoSQL” does not mean you have to throw away years of work put into
relational databases.
Setting aside the fact that we are yet to define what “NoSQL” actually is, some of the attributes that we commonly glob under this label are: document based, schema-free, distributed and “scalable”. The fact that being distributed and being scalable are not
one and the same is a subject for another post, instead let’s take a closer look at what schema-free and document-based actually means. In fact, let me jump ahead: I am genuinely surprised that we are yet to see a schema-free engine built on top of MySQL.
I know, I know, but suspend you disbelief for a second, because it is not as outrageous as it sounds.
Document Based: a Double Edged Sword
The original reason for and the benefit of the relational model is that by constraining the data schema
(read, eliminating structural complexity of the data, or decomposing it into relations), you actually gain power and flexibility in the types of queries you can execute against your database. Said another way, normalized data design allows us to have a general-purpose
query language, which allows for queries whose parameters we do not even know at design time, whereas denormalized designs do not. What we loose in flexibility of our data structures, we gain in our ability to interact with the data. Hence, in theory,
if you have no way to anticipate the types of queries in the future, a relation model is your best bet. Lose some, win some, chose your poison.
 At the
At the
same time, we all know that “no join is faster than no join”. The inherent disadvantage of decomposing your data is the required assembly. If you are looking for “speed” or “scalability”, then denormalizing your data is usually the first step. The disadvantage?
Now you have introduced a number of potential anomalies into your data: updates, inserts, and deletes can cause data inconsistencies unless you keep careful accounting of all duplication. One-to-One, and One-to-Many relations are usually easy to manage, but
Many-to-Many in denormalized schemas are nothing but a recipe for disaster. That is, if you care aboutconsistency.
Finally, since you lose the power of a general purpose query language (SQL), you are now at a mercy of the DSL provided by your new database. Mongo, Couch and many others had to introduce their own query language constructs alongside "map-reduce" functionality
to address the problem of querying arbitrarily deep records. Now, I am a fan of both, but frankly, none I have worked with so far are as clean, or as easy to understand as SQL (case
in point) - with the downside of making me learn yet another query language.
Schema-free != Document Based
Document based and schema-free are often used interchangeably, but there is an important difference: schema-free does not necessarily imply nested data structures. Likewise, just because MySQL is “relational” does not mean that it must be fixed to a predefined
schema - at create time, maybe, but not at runtime. Intersect the two statements, and it means that there is absolutely no reason why we cannot have a schema-free engine in MySQL:
mysql> use noschema;
mysql> create table widgets; /* look ma, no schema! */
mysql> insert into widgets (id, name) VALUES("a", "apple");
mysql> insert into widgets (id, name, type) VALUES("b", "blackberry", "phone");
mysql> select * from widgets where id = "a";
+---------+---------------+
| id | name |
+---------+---------------+
| a | apple |
+---------+---------------+
mysql> select * from widgets;
+---------+---------------+--------+
| id | name | type |
+---------+---------------+--------+
| a | apple | NULL |
| b | blackberry | phone |
+---------+---------------+--------+
As long as we avoid nested data structures, then there is no reason why we should be limited by the columns defined in our tables because we can compose and decompose any relation at runtime. Not only would this mean no migrations or need to store null values,
but you could also keep all the tools, drivers, and the SQL query language while adding the full flexibility of being schema-free.
Schema-free DB on top of MySQL
Not able to find any project that would give me this behavior, I ended up prototyping it myself over the weekend, and believe it or not, it works just fine. In fact, the output above is from a real console session with MySQL. All it took is an em-proxy
server with a little low-level protocol and query rewriting, and all of the sudden, my MySQL forgot that it requires a schema. Take it for a test-drive yourself (you will need Ruby 1.9):
$ git clone git://github.com/igrigorik/em-proxy.git && cd em-proxy
$ ruby examples/schemaless-mysql/mysql_interceptor.rb
$ mysql -h localhost -P 3307 --protocol=tcp
# snip ...
# build the select statements, hide the tables behind each attribute
join = "select #{table}.id as id "
tables.each do |column|
join += " , #{table}_#{column}.value as #{column} "
end
# add the joins to stich it all together
join += " FROM #{table} "
tables.each do |column|
join += " LEFT OUTER JOIN #{table}_#{column} ON #{table}_#{column}.id = #{table}.id "
end
join += " WHERE #{table}.id = '#{key}' " if key
Of course, this is nothing but a cute code example nor does it even cover all the different use cases, but let us look at the feature set: driver support for every language (you can point Rails + ActiveRecord, JDBC, etc. at it out the box, no problem), tool
support (GUI and command line), replication that works, basically impossible to corrupt, transactions, and so on. Not bad for half a day of hacking with a simple data model in the background:
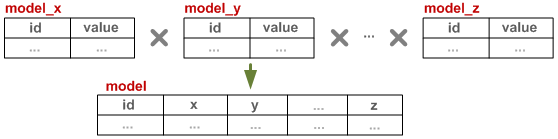
Instead of defining columns on a table, each attribute has its own table (new tables are created on the fly), which means that we can add and remove attributes at will. In turn, performing a select simply means joining all of the tables on that individual key.
To the client this is completely transparent, and while the proxy server does the actual work, this functionality could be easily extracted into a proper MySQL engine - I’m just surprised that no one has done so already. For a closer look, check
out the proxy code itself, there are plenty of comments, which explain how it is all pieced together.
The gray zone of SQL vs NoSQL
So what is the point of all this? Well, I hope someone actually writes such an engine, because I believe there is a market for it. There is a lot to be said for a drop in, SQL compatible, schema-free engine, and unlike what the NoSQL propaganda may say, there
is absolutely no reason why we can’t have many of the benefits of “NoSQL” within MySQL itself. There is no one clear winner for a database engine or model, so put some thought into your decision up front.
Just because Mongo, TC, or Couch are 'document-oriented' or 'schema-free' does not mean they are necessarily better for your application. In the meantime, don't get me wrong, I am still rooting for all the NoSQL projects, as well as have high expectations for
Drizzle - they are all doing fantastic work.