概念:
Hadoop有一个叫DataJoin的包为Data Join提供相应的框架。它的Jar包存在于contrib/datajoin/hadoop-*-datajoin。
为区别于其他的data join技术,我们称其为reduce-side join。(因为我们在reducer上作大多数的工作)
reduce-side join引入了一些术语及概念:
1.Data Source:基本与关系数据库中的表相似,形式为:(例子中为CSV格式)
Customers Orders
1,Stephanie Leung,555-555-5555 3,A,12.95,02-Jun-2008
2,Edward Kim,123-456-7890 1,B,88.25,20-May-2008
3,Jose Madriz,281-330-8004 2,C,32.00,30-Nov-2007
4,David Stork,408-555-0000 3,D,25.02,22-Jan-2009
2.Tag:由于记录类型(Customers或Orders)与记录本身分离,标记一个Record会确保特殊元数据会一致存在于记录中。在这个目的下,我们将使用每个record自身的Data source名称标记每个record。
3.Group Key:Group Key类似于关系数据库中的链接键(join key),在我们的例子中,group key就是Customer ID(第一列的3)。由于datajoin包允许用户自定义group key,所以其较之关系数据库中的join key更一般、平常。
流程:(详见《Hadoop in Action》Chapter 5.2)
Advanced MapReduce:
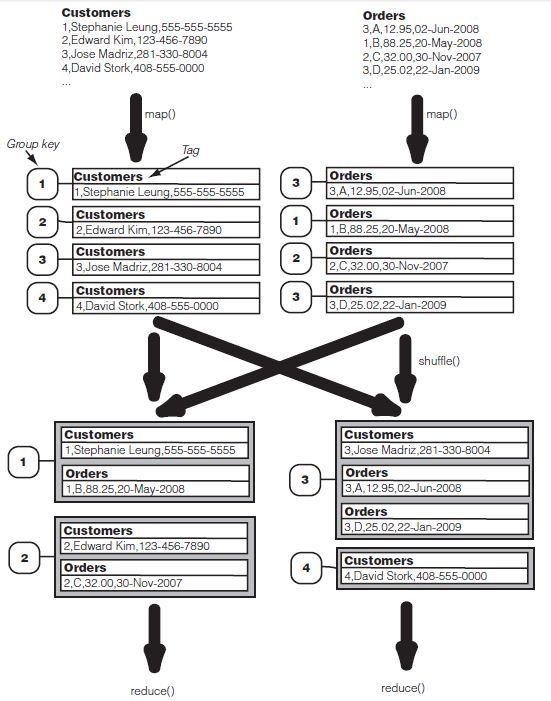
Joining Data from different sources:
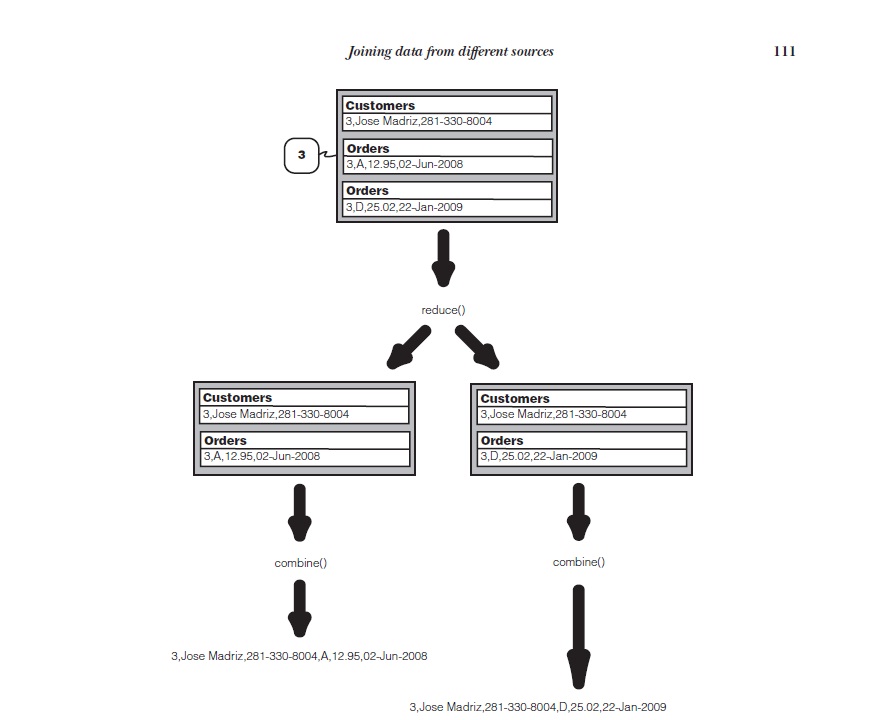
利用datajoin包来实现join:
Hadoop的datajoin包中有三个需要我们继承的类:DataJoinMapperBase,DataJoinReducerBase,TaggedMapOutput。正如其名字一样,我们的MapClass将会扩展DataJoinMapperBase,Reduce类会扩展DataJoinReducerBase。这个datajoin包已经实现了map()和reduce()方法,因此我们的子类只需要实现一些新方法来设置一些细节。
在用DataJoinMapperBase和DataJoinReducerBase之前,我们需要弄清楚我们贯穿整个程序使用的新的虚数据类TaggedMapOutput。
根据之前我们在图Advance MapReduce的数据流中所展示的那样,mapper输出一个包(由一个key和一个value(tagged record)组成)。datajoin包将key设置为Text类型,将value设置为TaggedMapOutput类型(TaggedMapOutput是一个将我们的记录使用一个Text类型的tag包装起来的数据类型)。它实现了getTag()和setTag(Text tag)方法。它还定义了一个getData()方法,我们的子类将实现这个方法来处理record记录。我们并没有明确地要求子类实现setData()方法,但我们最好还是实现这个方法以实现程序的对称性(或者在构造函数中实现)。作为Mapper的输出,TaggedMapOutput需要是Writable类型,因此的子类还需要实现readFields()和write()方法。
DataJoinMapperBase:
回忆join数据流图,mapper的主要功能就是打包一个record使其能够和其他拥有相同group key的记录去向一个Reducer。DataJoinMapperBase完成所有的打包工作,这个类定义了三个虚类让我们的子类实现:
protected abstract Text generateInputTag(String inputFile);
protected abstract TaggedMapOutput generateTaggedMapOutut(Object value);
protected abstract Text generateGroupKey(TaggedMapOutput aRecored);
在一个map任务开始之前为所有这个map任务会处理的记录定义一个tag(Text),结果将保存到DataJoinMapperBase的inputTag变量中,我们也可以保存filename至inputFile变量中以待后用。
在map任务初始化之后,DataJoinMapperBase的map()方法会对每一个记录执行。它调用了两个我们还没有实现的虚方法:generateTaggedMapOutput()以及generateGroupKey(aRecord);(详见代码)
DataJoinReducerBase:
DataJoinMapperBase将我们所需要做的工作以一个full outer join的方式简化。我们的Reducer子类只需要实现combine()方法来滤除掉我们不需要的组合来得到我们需要的(inner join, left outer join等)。同时我们也在combiner()中将我们的组合格式化为输出格式。
代码:
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.contrib.utils.join.DataJoinMapperBase;
import org.apache.hadoop.contrib.utils.join.DataJoinReducerBase;
import org.apache.hadoop.contrib.utils.join.TaggedMapOutput;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.ReflectionUtils;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class generate_Graph extends Configured implements Tool {
/**
* the reduce class
* @author zj
*
*/
public static class ReduceClass extends DataJoinReducerBase{
@Override
protected TaggedMapOutput combine(Object[] tags, Object[] values) {
if(tags.length < 2){
return null;
}
String joinedStr = "";
for(int i=0; i<values.length; i++){
if(i > 0){
joinedStr +=",";
}
TaggedWritable tw = (TaggedWritable)values[i];
String line = ((Text) tw.getData()).toString();
String[] tokens = line.split("," ,2);
joinedStr += tokens[1];
}
TaggedWritable retv = new TaggedWritable(new Text(joinedStr));
retv.setTag((Text) tags[0]);
return retv;
}
}
public static class MapClass extends DataJoinMapperBase {
@Override
protected Text generateGroupKey(TaggedMapOutput aRecord) {
String line = ((Text) aRecord.getData()).toString();
String[] tokens = line.split(",");
String groupKey = tokens[0];
return new Text(groupKey);
}
@Override
protected Text generateInputTag(String inputFile) {
return new Text(inputFile);
}
@Override
protected TaggedMapOutput generateTaggedMapOutput(Object value) {
TaggedWritable retv = new TaggedWritable((Text) value);
retv.setTag(this.inputTag);
return retv;
}
}
public static class TaggedWritable extends TaggedMapOutput {
private Writable data;
//默认构造器必须有
public TaggedWritable() {
this.tag = new Text("");
}
public TaggedWritable(Writable data) {
this.tag = new Text("");
this.data = data;
}
@Override
public Writable getData() {
return data;
}
@Override
public void write(DataOutput out) throws IOException {
this.tag.write(out);
out.writeUTF(this.data.getClass().getName());//没有则出问题
this.data.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
this.tag.readFields(in);
//没有则出问题
String dataClz = in.readUTF();
if (this.data == null
|| !this.data.getClass().getName().equals(dataClz)) {
try {
this.data = (Writable) ReflectionUtils.newInstance(Class.forName(dataClz), null);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
this.data.readFields(in);
}
}
/**
* wori
*/
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
JobConf job = new JobConf(conf, generate_Graph.class);
String outDir = "/joindata_output";
// 如果输出目录已经存在,那么先将其删除
/*FileSystem fstm = FileSystem.get(conf);
Path outDirP = new Path(outDir);
fstm.delete(outDirP, true);*/
FileInputFormat.setInputPaths(job, new Path(
args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setJobName("join_data_test");
job.setMapperClass(MapClass.class);
job.setReducerClass(ReduceClass.class);
job.setInputFormat(TextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(TaggedWritable.class);
job.set("mapred.textoutputformat.separator", ",");
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) {
int res = 0;
try {
res = ToolRunner.run(new Configuration(), new generate_Graph(), args);
} catch (Exception e) {
e.printStackTrace();
}
System.exit(res);
}
}