题目取的挺有感,事情却很简单,即对于一组数据,可以用直线/平面拟合(逼近)它们,也可以用曲线/曲面拟合。不过,这件事情也很复杂,因为需要弄清楚拟合的结果是不是足够的好。
在言归正传之前,需要回答一个问题:为什么要对数据进行拟合?回答这个问题很简单,因为人类总是想用简单的模型去概括繁杂的事物。看,这个问题的答案本身就是答案。
下面图中所示的数据是本文的主角,你要问它来自何方,我指着大海的方向……
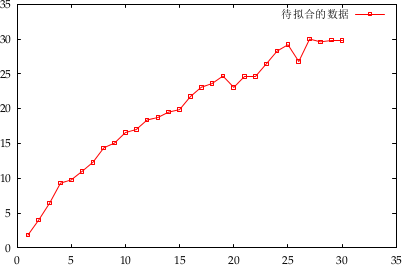
数据文件是 data.asc。
拟合方法与目标
大致有三种方法可以解决上面图中所示数据的直线与曲线的拟合问题。
第一种方法是非编程方法,即利用一些数据可视化工具读入数据,然后拟合,最后给出可视化的结果。本文使用的工具是 Gnuplot。
第二种方法是半编程方法,即调用现有的数值分析程序库中的黑箱函数完成数据拟合,然后给出拟合直线的参数、误差估计以及拟合优度。本文使用的程序库是 GSL。
第三种方法是全编程方法,即空手入白刃,在充分理解拟合原理的情况下,自己写出所有的代码来解决问题。这种做法,精神可嘉,但在一般情况下,特别是在第二种方法容易实现的情况下,不推荐这种做法。当然,理解拟合原理是非常有意义的。
感觉一篇文章中是很难将上述三种方法都讲述出来,况且此刻我对第三种方法还未有清晰的认识,所以暂时掘之为坑,只关注前两种方法。或许这样想会让我们轻松一下,不会炒菜,不意味不会品尝。
对于一组数据,无论是作直线/平面拟合,还是做曲线/曲面拟合,一个真正有用的拟合过程必须提供:(1) 拟合的参数;(2) 拟合所得参数的误差估计;(3) 拟合优度的统计度量。
如 果上述 (3) 中的结果表明了所拟合的模型与数据不一致,那么 (1) 与 (2) 中的结果通常没有多少意义。所以我们在使用既有的如 Gnuplot、GSL 这些工具或程序库进行数据拟合时,必须要对拟合优度有量化上的认识,而不能仅靠肉眼对拟合优度的定性观察。
Gnuplot 的直线与曲线的拟合
Gnuplot 对一组数据进行直线拟合的实现具体可围观下面的 Gnuplot 脚本:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#setset#set#f(x)#a#fit#plot |
设该脚本文件名为 test.gnu,使用以下命令输出 test.png 文件:
|
1
|
$test.gnu |
所得 test.png 文件即下图,红色的直线拟合了绿色的数据点集。
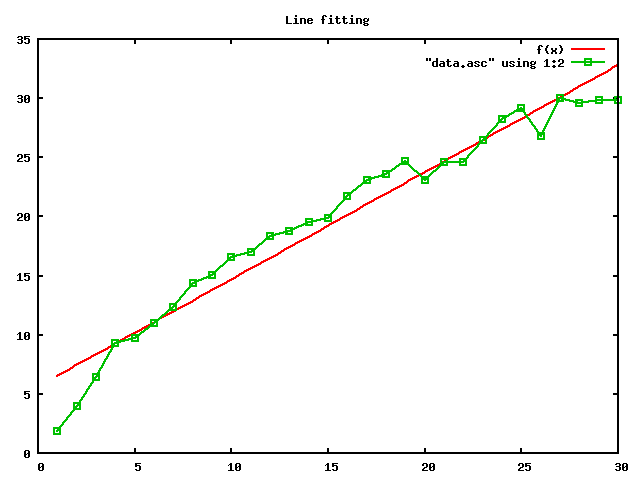
也许你的感觉一向不太敏锐,所以即使看到这条拟合的并不怎么好的直线也感觉不到它有什么不好。数据不说谎,所以我们需要对拟合直线的优度进行度量,而不能依靠我们经常犯错的双眼。下面,我们来看应该如何对这条直线的拟合优度进行度量。
当你在终端中在执行上述的 gnuplot 命令时,终端必定会输出类似以下的信息:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
$ Iteration WSSR delta(WSSR) lambda initiala b / Iteration WSSR delta(WSSR) lambda resultanta b / Iteration WSSR delta(WSSR) lambda resultanta b / Iteration WSSR delta(WSSR) lambda resultanta b / Iteration WSSR delta(WSSR) lambda resultanta b Afterfinalrel.degreesrmsvarianceFinal======================= a b correlation a a b |
上述信息,从第 3 行至第 55 行显示的是直线拟合的迭代过程,这个迭代过程从我们初始给定的 a 与 b 的值开始,每一次迭代的目标是缩小 a 和 b 所确定的直线与数据点集的距离的统计量,即信息中的 WSSR 的值。可以看到,一共历经了 4 次迭代,WSSR 的值从大到小递减,第 3 次与第 4 次迭代所得的 WSSR 值相等,这意味着迭代过程收敛,直线拟合过程结束。
我们真正要关注的是第 57 行至第 76 行的信息。其中,第 68、69 行分别显示了计算出来的参数 a 与 b 的值以及它们的误差估计。前面我们说过,如果直线的拟合优度很差,那么所得 a 与 b 的值及其误差估计都没有太多的意义。
但是不幸的是 Gnuplot 并未进一步提供直线拟合优度的计算,它的 `help statistical_overview` 信息中如此说到(有所白话):为了估计所得参数的可信度,你需要使用拟合所得目标函数的最小值并结合卡方统计来确定用于量化拟合优度的卡方值,当然这需要更进一步的计算。
也就是说,Gnuplot 的开发者太懒了,将拟合过程进展到第 (2) 步便停止前进。那么,我们该肿么办?特别是我们还不是非常清楚拟合的原理,更对统计学中的这个分布那个分布一头雾水的时候,我们该肿么办?
其实这个问题很简单,只要我们怀着一颗勇敢又不求甚解的心。我们先不理睬鬼的卡方统计是什么,除非你的概率与统计学基础很不错。要计算直线的拟合优度,我们可以将 Gnuplot 所得的 WSSR 值与自由度的值代入下面的公式即可。
其中 WSSR 是迭代收敛后所得的最小的那个 WSSR 值,这个值在上面的 Gnuplot 输出信息的第 58 行给出了,那么
30,待定的参数是 2 个,所以自由度
28。实际上在上面的 Gnuplot 输出信息中的第 61 行已经给出了这个值。
0.1,那么可以确信拟合的直线是足够好的;如果这个值大于 0.001,勉强可以接受;如果这个值小于 0.001,那么直线可能并不适合所给的数据点集,可以考虑更换为某种曲线模型。
现在,我不打算写出
库中提供了这个函数的程序实现,即 gsl_cdf_chisq_Q 函数,它接受的两个参数与上面我们给出的
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#include#includeintmainvoid){ float scanf"%f, printf"%lf\n", return} |
当然,要编译和运行这个程序,你需要安装 GSL 库。编译和运行这个程序的命令如下:
|
1
2
3
4
|
$xargs$/chisq-Q28Q |
我们将自由度 28 与 WSSR 值 90.95996 提交给 chisq-Q 程序后,它给出的直线拟合优度为 0.000034,这个值显然小于 0.001,所以我们可以确定这条直线并不适于拟合所给的数据点集。
当 然,我们说这条直线不适合所给的数据点集,主要指的是直线与点集的偏差太大,违背了我们进行数据拟合的初衷。但是有的时候,我们的目标就是要得到一条最能 逼近所给点集的直线,例如点集的 PCA 分析,在这样的情况中,我们只需要确定直线的参数,任务便可结束,无需确定拟合优度。也就是说,所得的拟合结果是否适合所给的数据点集,这主要取决于我们 的目的或需求。本文的目标显然指的是前者。
既然确定直线模型不适于拟合本文的数据点集,那么我们试试曲线模型可不可以。认真观察了一番数据,感觉它很像
test.gnu 脚本中的第 9 行修改为:
|
1
|
f(x) |
其中,** 是 Gnuplot 的求幂运算符。
然后再次运行 Gnuplot 命令,得到下面所示的数据与拟合曲线图:
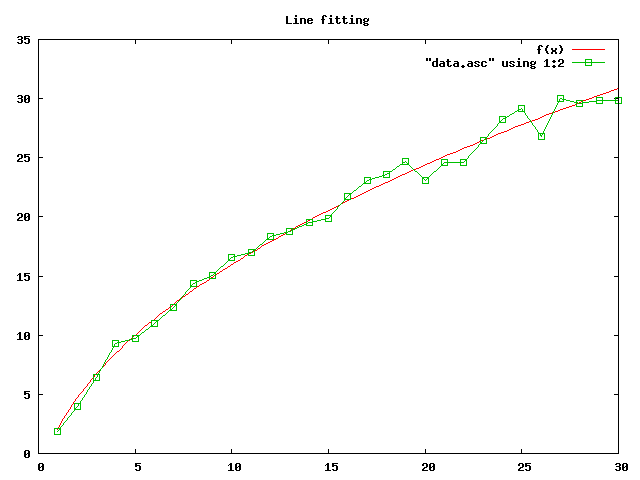
现在拟合的这条曲线对数据点集的贴近程度,即使不计算拟合优度,我们也可以确定的说它要比前面的直线拟合更好,但是本着客观科学的精神,我们还是让数据来说话。
先来看 Gnuplot 对这条曲线的迭代拟合过程终止后输出的信息:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
Afterfinalrel.degreesrmsvarianceFinal======================= a b correlation a a b |
嗯,迭代次数依然是 4 次,收敛速度依然挺快。现在,将所得的自由度与 WSSR 最小值代入
|
1
2
3
|
$28Q |
这次所得的拟合优度是 0.861690,显然远大于 0.1,这说明我们选择的这一曲线模型是可靠的。既然如此,那么所得到的参数 a 与 b 的值也是可靠的,它们的误差值也便有了意义。
如果你真的看了前面给出的 Gnuplot 两次的输出信息,也许会注意到输出信息的最后会有一个对角矩阵,例如:
|
1
2
3
4
5
|
correlation a a b |
这个矩阵是待定参数 a 与 b 的相关矩阵,非对角线上的数值表示 a 与 b 的相关度。这个值的符号为正,表示相关的两个参数值同号,本例即 a 与 b 同号,否则表示 a 与 b 异号。这个值的绝对值越大,即越接近 1,那么所得参数的误差估计也就越接近于真实误差。
不要问我为什么是这样,这些都是 Gnuplot 的帮助文档中说的。如果真要深究,其中的水很深。现在就可以唬你一下,Gnuplot 所采用的拟合算法是非线性最小二乘法中作为事实标准的 Levenberg-Marquardt 方法。也许以后我会慢慢的关注其中的道理,现在还是只关心直线或曲线的拟合所得参数值及拟合优度吧,而参数值的误差,也许只能作为不计算拟合优度时对拟合 质量的定性的判据。
GSL 直线拟合成功,曲线拟合未遂
在上一节中,我们已经用过一次 GSL 了。虽然还没有探索它的数据拟合功能,但是它的
Gnuplot 要好。
来,我们围观一下 GSL 中的直线拟合函数 gsl_fit_linear,其类型为:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
/*intgsl_fit_linearconst/* const/* const/* const/* size_t/* double/* double/* double/* double/* double/* double/* ); |
由 gsl_fit_linear 函数的参数可知它只适用于直线模型
下面为 gsl_fit_linear 函数准备好每个参数。
前 5 个参数中,xstride 与 ystride 的值设为 1,表示数据点集
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
<定义读取点集文件的函数staticinput_pointsconst{ GList GIOChannel"r", GIOStatus gchar gsl_vector guint do status &str, NULL, NULL, NULL); if continue; strq data";,\t, for if continue; v for v->data[i] } data_set g_free g_strfreev count }while g_io_channel_unref return} |
原谅我为了提高 input_points 函数对点集数据文件解析的健壮性,在上述代码中使用了 GLib 库中的列表、IO 通道以及字符串处理函数。如果你对 GLib 不熟悉并且讨厌熟悉它,那么你只需要知道input_points 函数的功能是:根据文件名读取相应的数据点集文件内容并逐行进行解析,将解析出来的点的坐标值保存至 GSL 向量并将后者存储于
GLib 列表中,最后返回该列表。
基于 input_points 函数返回的列表便可产生 gsl_fit_linear 函数的第 1、3、5 个参数,剩下的参数皆为待定值,将它们定义为局部变量然后直接取址传于 gsl_fit_linear 即可。下面便是 gsl_fit_linear 函数全部参数的准备、函数调用以及结果显示代码,请围观:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
#include#include#include#include<定义读取点集文件的函数staticdestroy_data{ gsl_vector_free}intmainintchar{ GList guint gdoublesizeof(gdouble)); gdoublesizeof(gdouble)); /* guint for it it gsl_vector x[i] y[i] i++; } /* gdouble /* gsl_fit_linear &c0, /* g_print"f(x), g_print"c0, g_print"c1, g_print"correlation, g_print"Q, (n /* g_slice_free1sizeof(gdouble), g_slice_free1sizeof(gdouble), g_list_free_full return } |
将上述代码与更上面的 input_points 函数定义部分的代码合并为 fitting-line.c 程序源文件,编译这个文件的命令如下:
|
1
2
|
$xargs gcc |
运行编译生成的程序 fitting-line:
|
1
2
3
4
5
6
|
$/fitting-linef(x)c0c1correlationQ |
输出了 5 行信息。第 1 行信息是确定了参数
Gnuplot 拟合的直线相同。第 2、3 行信息分别是参数
4 行是参数的相关度,这些结果与 Gnuplot 的结果不同,这主要是因为 GSL 的直线拟合算法采用的是线性最小二乘法,Gnuplot 采用的是非线性最小二乘法,而本文所涉及的数据拟合皆为线性最小二乘问题,所以 Gnuplot 的拟合参数的误差估计及相关性度量并不准确。第 5 行是直线的拟合优度,显然它与 Gnuplot 所得的直线拟合优度相等。
GSL 与 Gnuplot 的直线拟合除了拟合参数的误差估计及相关度不相同之外,所拟合的直线解析式及拟合优度是相同的。这样看起来,GSL 除了提供
Gnuplot 在拟合直线时,需要用户对拟合参数设定初值,而 gsl_fit_linear 则不需要。这依然是因为 Gnuplot 的拟合算法是非线性最小二乘法导致的,因为非线性最小二乘问题必须进行迭代求解,既然是迭代,那必须要给出起点,而线性最小二乘问题通常只需求解一个线性方程组,这不需要迭代。
一定要注意,本文所说的线性与非线性,指的是待拟合的各个参数是线性组合还是非线性组合,而不是函数解析式中自变量的线性/非线性组合。
既然我们已经使用 GSL 一帆风顺的完成了直线的拟合,宜将剩勇追穷寇,一举攻克曲线
GSL 为直线的拟合单独提供了函数,然后又为一般的线性最小二乘问题提供了一个通用的函数gsl_multifit_linear,不知这是为何,不过也没有必要深究。相比之下,Gnuplot 非常懒惰,它将线性最小二乘问题视为非线性最小二乘问题的特殊形式,所以它选择了一种更通用的拟合算法——用这种算法去拟合直线,宛若宰牛刀杀鸡。
围观一下 gsl_multifit_linear 函数的类型:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
intgsl_multifit_linear /* const /* const /* gsl_vector /* gsl_matrix /* double /* gsl_multifit_linear_workspace ); |
这个函数所接受的参数与 gsl_multifit_linear 函数相迥异。我们需要耐心的逐个考察,以求获取直观认识。但是现在必须要对线性最小二乘问题进行一些形式化的定义,否则用语言很难表达清楚。
线性最小二乘问题及求解方法
假设有一个函数
以本文所拟合的曲线
上式的一般形式是
总而言之,无论参数集
0,即:
两个未知数,两个线性方程,后事如何,你懂的……按照这一思路,即使是 M 个参数构成的参数集
M 个线性方程的问题。
解线性方程组的方法有很多,但是能同时适应于非奇异与奇异线性方程组的求解方法是 SVD(奇异值分解)法。所谓非奇异线性方程组指的是其中任何一个方程不是其他方程的线性组合或近似线性组合,否则就是奇异线性方程组。求解非奇异线性方 程组的方法主要有高斯消去法或 LU 分解法。这两种方法对于奇异线性方程组的求解会出现机器舍入误差积累从而导致求解结果往往与真实解相差甚远,这种情况下,SVD 法便散发出耀眼的光芒。
所 谓 SVD,就是将任意一个
对一个矩阵搞此等分解,其意何为?且看下式:
其中,
之所以可以写成这样,是因为
有关奇异值分解与线性方程组求解的问题,水也是非常的深,我们暂时浮光掠影的围观一下即可。因为即使未能彻悟其中的道理,也可以无障碍的使用 GSL 所提供的奇异值分解函数的。
gsl_multifit_linear 函数正是使用 SVD 方法求解线性最小二乘拟合问题的。
现在可以揭晓上一节中 gsl_multifit_linear 函数的各项参数的含义了。它的前三项参数 X, y, c 即是构成线性方程组的矩阵与两个列向量,即:
其中,
第 4、5 项参数的含义与 gsl_fit_linear 函数中对应的参数相同,而第 6 项参数主要是用于在函数中保存矩阵
与 GSL 曲线拟合最后的搏斗
现在既知 gsl_multifit_linear 函数各项参数的含义,那么我们利用 GSL 直线拟合时所写的数据输入及 GSL 提供的工作空间准备函数,便可为 gsl_multifit_linear 函数准备好它需要的参数值。
首先围观如何产生矩阵
M=2,而输入的点集包含 N 个点,那么矩阵
NxM 的,向量
M,三个参数值的构造过程如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
<输入点集并确定问题规模 GList guint size_t<准备 gsl_matrix gsl_vector GList for gsl_vector gsl_matrix_set gsl_matrix_setpow gsl_vector_set it } gsl_vector |
gsl_multifit_linear 函数的第 4、5 个参数值的构造如下:
|
1
2
3
|
<准备 gsl_matrix gdouble |
gsl_multifit_linear 函数第 6 个参数值是该函数的工作空间,为了防止疏忽而导致内存泄漏,通常是伴随曲线拟合临时分配,用完即销毁:
|
1
2
3
4
|
<工作空间构造、曲线拟合及工作空间销毁> gsl_multifit_linear_workspace gsl_multifit_linear gsl_multifit_linear_free |
将上述步骤组合起来,并上结果的显示及内存回收的代码,全部过程如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
#include#include#include#include#include<定义读取点集文件的函数staticdestroy_data{ gsl_vector_free}intmainintchar{ <输入点集并确定问题规模 <准备 <准备 <工作空间构造、曲线拟合及工作空间销毁> /* g_print"f(x), g_print"Q, (N /* gsl_matrix_free gsl_vector_free gsl_vector_free gsl_matrix_free g_list_free_full return} |
编译并运行这个程序:
|
1
2
3
4
5
6
|
$xargs gcc$/fitting-curvef(x)Q |
所得结果与 Gnuplot 的非线性拟合结果一致!
结语
我们赢了,欢呼……空虚……寂寞……发现前面还有更多的恶魔——最小二乘问题的数学模型、非线性拟合问题的求解方法、SVD 与线性方程组求解的关系等等——它们在等待着吞噬我们……继续前进,还是回家吃饭,这始终是个问题。