http://bubblexc.com/y2011/148/
很多时候,我们希望对一个二值分类器的性能进行评价,AUC正是这样一种用来度量分类模型好坏的一个标准。现实中样本在不同类别上的不均衡分布(class distribution imbalance problem),使得accuracy这样的传统的度量标准不能恰当的反应分类器的性能。举个例子:测试样本中有A类样本90个,B 类样本10个。若某个分类器简单的将所有样本都划分成A类,那么在这个测试样本中,它的准确率仍为90%,这显示是不合理的。为了解决上述问题,人们从医疗分析领域引入了一种新的分类模型performance评判方法——ROC分析。在介绍ROC之前,首先讨论一下混淆矩阵(Confusion
matrix)。
混淆矩阵是监督学习中的一种可视化工具,主要用于比较分类结果和实例的真实信息(outcom vs. ground truth)。矩阵中的每一行代表实例的预测类别,每一列代表实例的真实类别。在混淆矩阵中,每一个实例可以划分为四种类型之一,True Positive\False Positive\False Negative\True Negetive(TP\FP\FN\TN),如图1所示。其中,Positive代表预测实例来自正类,Negetive代表预测实例来自负类;True代表预测正确,False代表预测错误。

由混淆矩阵可以计算一系列的评价指标,如accurancy、precision、recall等等。
回到ROC上来,ROC的全名叫做Receiver Operating Characteristic。ROC关注两个指标true positive rate(TPR= TP / [TP + FN] ) 和 false positive rate (FPR= FP / [FP + TN] ),直观上,TPR代表能将正例分对的概率,FPR代表将负例错分为正例的概率。在ROC
空间中,每个点的横坐标是FPR,纵坐标是TPR,这也就描绘了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。我们知道,对于二值分类问题,实例的值往往是连续值,我们通过设定一个阈值,将实例分类到正类或者负类(比如大于阈值划分为正类)。因此我们可以变化阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0)(1,1),实际上(0, 0)和(1,
1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。如图2所示。

图2 ROC Curve
用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的performance。
如果分类器只对实例产生p或者n的标签,那么所有的测试集也只能对应图中的一个点。
需要一个threshold,如果得分大于threshold则是p,否则是n
显然随着threshold的不断下降,tpr也随着变大,就是预测正例占实际正例的比率,而fpr也随之变大,就是有越来越多的负例被错误的标注为正例
这样就能形成一条折线,计算这条折线下面的面积就是auc

折线上点傍边的值就是threshold
http://blog.csdn.net/chjjunking/article/details/5933105
让我们从头说起,首先AUC是一种用来度量分类模型好坏的一个标准。这样的标准其实有很多,例如:大约10年前在machine learning文献中一统天下的标准:分类精度;在信息检索(IR)领域中常用的recall和precision,等等。其实,度量反应了人们对” 好”的分类结果的追求,同一时期的不同的度量反映了人们对什么是”好”这个最根本问题的不同认识,而不同时期流行的度量则反映了人们认识事物的深度的变 化。近年来,随着machine learning的相关技术从实验室走向实际应用,一些实际的问题对度量标准提出了新的需求。特别的,现实中样本在不同类别上的不均衡分布(class
distribution imbalance problem)。使得accuracy这样的传统的度量标准不能恰当的反应分类器的performance。举个例子:测试样本中有A类样本90个,B 类样本10个。分类器C1把所有的测试样本都分成了A类,分类器C2把A类的90个样本分对了70个,B类的10个样本分对了5个。则C1的分类精度为 90%,C2的分类精度为75%。但是,显然C2更有用些。另外,在一些分类问题中犯不同的错误代价是不同的(cost sensitive learning)。这样,默认0.5为分类阈值的传统做法也显得不恰当了。
为了解决上述问题,人们从医疗分析领域引入了一种新的分类模型performance评判方法——ROC分析。ROC分析本身就是一个很丰富的内容,有兴趣的读者可以自行Google。由于我自己对ROC分析的内容了解还不深刻,所以这里只做些简单的概念性的介绍。
ROC的全名叫做Receiver Operating Characteristic,其主要分析工具是一个画在二维平面上的曲线——ROC curve。平面的横坐标是false positive rate(FPR),纵坐标是true positive rate(TPR)。对某个分类器而言,我们可以根据其在测试样本上的表现得到一个TPR和FPR点对。这样,此分类器就可以映射成ROC平面上的一个点。调整这个分类器分类时候使用的阈值,我们就可以得到一个经过(0,
0),(1, 1)的曲线,这就是此分类器的ROC曲线。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。因为(0, 0)和(1, 1)连线形成的ROC曲线实际上代表的是一个随机分类器。如果很不幸,你得到一个位于此直线下方的分类器的话,一个直观的补救办法就是把所有的预测结果反向,即:分类器输出结果为正类,则最终分类的结果为负类,反之,则为正类。虽然,用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。于是Area Under
roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的performance。好了,到此为止,所有的 前续介绍部分结束,下面进入本篇帖子的主题:AUC的计算方法总结。
最直观的,根据AUC这个名称,我们知道,计算出ROC曲线下面的面积,就是AUC的值。事实上,这也是在早期Machine Learning文献中常见的AUC计算方法。由于我们的测试样本是有限的。我们得到的AUC曲线必然是一个阶梯状的。因此,计算的AUC也就是这些阶梯下面的面积之和。这样,我们先把score排序(假设score越大,此样本属于正类的概率越大),然后一边扫描就可以得到我们想要的AUC。但是,这么 做有个缺点,就是当多个测试样本的score相等的时候,我们调整一下阈值,得到的不是曲线一个阶梯往上或者往右的延展,而是斜着向上形成一个梯形。此时,我们就需要计算这个梯形的面积。由此,我们可以看到,用这种方法计算AUC实际上是比较麻烦的。
一个关于AUC的很有趣的性质是,它和Wilcoxon-Mann-Witney Test是等价的。这个等价关系的证明留在下篇帖子中给出。而Wilcoxon-Mann-Witney Test就是测试任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score。有了这个定义,我们就得到了另外一中计算AUC的办法:得到这个概率。我们知道,在有限样本中我们常用的得到概率的办法就是通过频率来估计之。这种估计随着样本规模的扩大而逐渐逼近真实值。这
和上面的方法中,样本数越多,计算的AUC越准确类似,也和计算积分的时候,小区间划分的越细,计算的越准确是同样的道理。具体来说就是统计一下所有的 M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score相等的时候,按照0.5计算。然后除以MN。实现这个方法的复杂度为O(n^2)。n为样本数(即n=M+N)
第三种方法实际上和上述第二种方法是一样的,但是复杂度减小了。它也是首先对score从大到小排序,然后令最大score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推。然后把所有的正类样本的rank相加,再减去正类样本的score为最 小的那M个值的情况。得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。然后再除以M×N。即
AUC=((所有的正例位置相加)-M*(M+1))/(M*N)
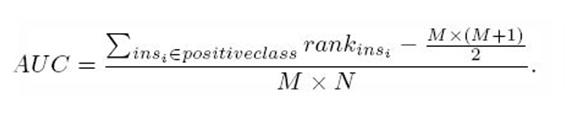
另外,特别需要注意的是,再存在score相等的情况时,对相等score的样本,需要 赋予相同的rank(无论这个相等的score是出现在同类样本还是不同类的样本之间,都需要这样处理)。具体操作就是再把所有这些score相等的样本 的rank取平均。然后再使用上述公式。
方法3的方法没有看太明白,但是方法2的思想很清楚。就是要通过正例和负例的比较。
roc求的是取一个正例和一个负例,正例的分数大于负例分数的概率
根据方法3的算法
awk 'BEGIN{s=0;w=0;h=0;}{if($1==1){h++;}else {w++;s=s+h;}}END{AUC=s/(w*h); print AUC}'
对于上面的计算方法的直观例子是:
左边表示实例的标注,+或者-
右边是模型给出的得分
+ 0.9
- 0.85
+ 0.8
+ 0.75
- 0.6
就是计算有多少个正例的得分大于负例
对于第一个负例而言,有一个正例的得分大于它,+1
第二个负例,有三个正例的得得分大于它,+3
所以一共有4个正例大于负例的得分
http://blog.csdn.net/sasuke546/article/details/8872525
AUC的计算方法实际上是计算每个离散ROC点之间所形成的梯形面积来估算的。
以下是Matlab的代码
输入score是分类器的输出向量,label是实际的标签,P是正类的样本数,N是负类的样本数,在标签中,正类是2类,负类是1类
- function [ Area ] = AUC( score , label, P, N )
- function [ A ] = Trapezoid_area(x1,x2,y1,y2) % Area of Trapezoid
- base = abs(x1-x2);
- height = (y1+y2)/2;
- A = base*height;
- end
- function [ f ] = equal(a,b) % isequal
- if(abs(a-b)<1e-8)
- f = 1;
- else
- f = 0;
- end
- end
- %AUC Summary of this function goes here
- % Detailed explanation goes here
- [Y,ind]=sort(score,'descend'); % sort, Y is the vector after sort
- % ind is the index of the original place
- NS = size(score,2);
- FP = 0;
- TP = 0;
- FPpv = 0; TPpv = 0;
- Area = 0; fprev = -999999999;
- i = 1;
- while (i<=NS)
- if(equal(Y(i),fprev)==0) % not equal
- Area = Area + Trapezoid_area(FP,FPpv,TP,TPpv);
- fprev = Y(i);
- FPpv = FP;
- TPpv = TP;
- end
- if(label(ind(i))==2) % instanse i is positive
- TP = TP +1;
- else % negative
- FP = FP + 1;
- end
- i = i + 1;
- end
- Area = Area + Trapezoid_area(N,FPpv,P,TPpv);
- Area = Area/(P*N);
- end
http://www.yewen.us/blog/2012/06/machine-learning-2-offline-evaluation/
机器学习手记系列 2: 离线效果评估
上一次说到选特征的一个简单方法, 但是如果真的要评估一个方法或者一类特征的效果, 简单的相似度计算是不够的, 在上线实验之前, 还是需要有一些别的方式来做验证.
我遇到过的大部分机器学习问题, 最终都转成了二分类问题 (概率问题). 最直白的比如 A 是否属于集合 S (某照片中的人脸是否是人物 Z), 排序问题也可以转换为二分类问题, 比如广告点击率或推荐的相关度, 把候选集分为点击/不点击或接受推荐/不接受推荐的二分类概率. 那在上线之前, 可以用过一些分类器性能评估的方法来做离线评估.
分类器的正确率和召回率
前几天在无觅上看到有人分享了一篇 数据不平衡时分类器性能评价之ROC曲线分析, 把这个问题已经讲差不多了, 我这复述一下.
先说混淆矩阵 (confusion matrix). 混淆矩阵是评估分类器可信度的一个基本工具, 设实际的所有正样本为 P (real-Positive), 负样本为 N (real-Negative), 分类器分到的正样本标为 pre-Positive', 负样本标为 pre-Negetive', 则可以用下面的混淆矩阵表示所有情况:
| real-positive | real-negative pre-positive' | TP (true positive) | FP (false positive) pre-negative' | FN (false negative) | TN (true negative)
通过这个矩阵, 可以得到很多评估指标:
FP rate = FP / N TP rate = TP / P Accuracy = (TP + TN) / (P + N) # 一般称之为准确性或正确性 Precision = TP / (TP + FP) # 另一些领域的准确性或正确性, 经常需要看上下文来判断 Recall = TP / P # 一般称之为召回率 F-score = Precision * Recall
在我接触过的大部分工作中, 大家都在关注 Precision 和 Recall. 同引用原文中提到的, 这样的分类评估性能只在数据比较平衡时比较好用 (正负例比例接近), 在很多特定情况下正负例是明显有偏的 (比如万分之几点击率的显示广告), 那就只能作为一定的参考指标.
分类器的排序能力评估
很多情况下我们除了希望分类器按某个阈值将正负样本完全分开, 同时还想知道候选集中不同条目的序关系. 比如广告和推荐, 首先需要一个基础阈值来保证召回的内容都满足基本相关度, 比如我一大老爷们去搜笔记本维修代理你给我出一少女睫毛膏的广告或推荐关注, 我绝对飙一句你大爷的然后开AdBlock 屏蔽之.
在保证了基础相关性 (即分类器的正负例分开) 后, 则需要比较同样是正例的集合里, 哪些更正点 (其实说白了就是怎样才收益最大化). 一般来说, 如果分类器的输出是一个正例概率, 则直接按这个概率来排序就行了. 如果最终收益还要通过评估函数转换, 比如广告的 eCPM = CTR*Price, 或推荐里 rev = f(CTR), (f(x) 是一个不同条目的获益权重函数), 那么为了评估序是否好, 一般会再引入 ROC 曲线和 AUC 面积两个指标.
ROC 曲线全称是 Receiver Operating Characteristic (ROC curve), 详细的解释可以见维基百科上的英文词条 Receiver_operating_characteristic 或中文词条 ROC曲线.
我对 ROC 曲线的理解是, 对某个样本集, 当前分类器对其分类结果的 FPR 在 x 时, TPR 能到 y. 如果分类器完全准确, 则在 x = 0 时 y 就能到 1, 如果分类器完全不靠谱, 则在 x = 1 时 y 还是为 0, 如果 x = y, 那说明这个分类器在随机分类. 因为两个都是 Rate, 是 [0, 1] 之间的取值, 所以按此方法描的点都在一个 (0, 0), (1, 1) 的矩形内, 拉一条直线从 (0, 0) 到 (1, 1), 如果描点在这条直线上, 说明分类器对当前样本就是随机分的
(做分类最悲催的事), 如果描点在左上方, 说明当前分类器对此样本分类效果好过随机, 如果在右下方, 那说明分类器在做比随机还坑爹的反向分类. 引用维基百科上的一个图来说明:
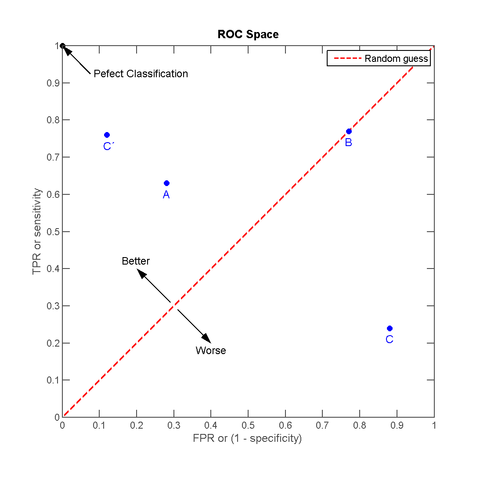
其中 C' 好于 A (都是正向的), B 是随机, C 是一个反效果 (跟 C' 沿红线轴对称, 就是说把 C 的结果反过来就得到 C').
如果我们有足够多的样本, 则对一个分类器可以在 ROC 曲线图上画出若干个点, 把这些点和 (0, 0), (1, 1) 连起来求凸包, 就得到了 AUC 面积 (Area Under Curve, 曲线下面积). 非常明显, 这个凸包的最小下面积是 0.5 (从 (0, 0) 到 (1, 1) 的这条线), 最大是 1.0 (整个矩形面积), AUC 值越大, 说明分类效果越好.
用 ROC 曲线定义的方式来描点计算面积会很麻烦, 不过还好前人给了我们一个近似公式, 我找到的最原始出处是 Hand, Till 在 Machine Learning 2001 上的一篇文章给出 [文章链接].
中间的推导过程比较繁琐, 直接说我对这个计算方法的理解: 将所有样本按预估概率从小到大排序, 然后从 (0, 0) 点开始描点, 每个新的点是在前一个点的基础上, 横坐标加上当前样本的正例在总正例数中的占比, 纵坐标加上当前样本的负例在总负例数中的占比, 最终的终点一定是 (1, 1), 对这个曲线求面积, 即得到 AUC. 其物理意义也非常直观, 如果我们把负例都排在正例前面, 则曲线一定是先往上再往右, 得到的面积大于 0.5, 说明分类器效果比随机好, 最极端的情况就是所有负例都在正例前, 则曲线就是
(0, 0) -> (0, 1) -> (1, 1) 这样的形状, 面积为 1.0.
同样给一份 C 代码实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
structSampleNode { doublepredict_value; unsignedintpos_num; unsignedintneg_num;};intcmp(constvoid*a,constvoid*b){ SampleNode *aa = (SampleNode *)a; SampleNode *bb = (SampleNode *)b; return(((aa->predict_value)-(bb->predict_value)>0)?1:-1);}doublecalcAuc(SampleNode samples[],intsample_num) qsort(samples, sample_num,sizeof(SampleNode), // init all counters doublesum_pos = 0; doublesum_neg = 0; doublenew_neg = 0; doublerp = 0; for(inti if(samples[i].neg_num >= 0) { new_neg += samples[i].neg_num; } if(samples[i].pos_num >= 0) { // calc as trapezium, not rectangle rp += samples[i].pos_num * (sum_neg + new_neg)/2; sum_pos += samples[i].pos_num; } sum_neg = new_neg; } returnrp/(sum_pos*sum_neg);} |
分类器的一致性
如果分类器的概率结果就是最终结果序, 那 AUC 值基本可以当作最终效果来用. 但是实际应用中分类器的结果都要再做函数转换才是最终序, 则评估的时候需要将转换函数也带上去做 AUC 评估才行. 某些应用中这个转换函数是不确定的, 比如广告的价格随时会变, 推荐条目的重要性或收益可能也是另一个计算模型的结果. 在这种情况下, 如果我们可以保证分类器概率和实际概率一致, 让后续的转换函数拿到一个正确的输入, 那么在实际应用中才能达到最优性能.
为了评估分类器概率和实际概率的一致性, 引入 MAE (Mean Absolute Error, 平均绝对误差) 这个指标, 维基百科对应的词条是Mean_absolute_error. 最终的计算方法很简单, 对样本 i, fi 是预估概率,
yi是实际概率, 则 i 上绝对误差是 ei,
累加求平均就是 MAE:
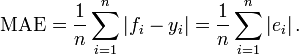
MAE 的值域是 [0, +∞), 值越小说明分类器输出和实际值的一致性越好. 我个人认为如果 MAE 和实际概率一样大, 那这个分类器的波动效果也大到让预估近似随机了.
MAE 看起来和标准差有点像, 类似标准差和方差的关系, MAE 也有一个对应的 MSE (Mean Squared Error, 均方差?), 这个指标更多考虑的是极坏情况的影响, 计算比较麻烦, 一般用的也不多, 有兴趣的可以看维基百科上的词条Mean_squared_error.
MAE 计算太简单, MSE 计算太纠结, 所以都不在这给出代码实现.