Resilient Distributed Dataset (RDD)弹性分布数据集
◆ RDD是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现。RDD是Spark最核心的东西,它表示已被分区,不可变的并能够被并行操作的数据集合,不同的数据集格式对应不同的RDD实现。RDD必须是可序列化的。RDD可以cache到内存中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。这对于迭代运算比较常见的机器学习算法, 交互式数据挖掘来说,效率提升比较大。
◆ RDD的特点:
- 它是在集群节点上的不可变的、已分区的集合对象。
- 通过并行转换的方式来创建如(map, filter, join, etc)。
- 失败自动重建。
- 可以控制存储级别(内存、磁盘等)来进行重用。
- 必须是可序列化的。
- 是静态类型的。
◆ RDD的好处
- RDD只能从持久存储或通过Transformations操作产生,相比于分布式共享内存(DSM)可以更高效实现容错,对于丢失部分数据分区只需根据它的lineage就可重新计算出来,而不需要做特定的Checkpoint。
- RDD的不变性,可以实现类Hadoop MapReduce的推测式执行。
- RDD的数据分区特性,可以通过数据的本地性来提高性能,这与Hadoop MapReduce是一样的。
- RDD都是可序列化的,在内存不足时可自动降级为磁盘存储,把RDD存储于磁盘上,这时性能会有大的下降但不会差于现在的MapReduce。
◆ RDD的存储与分区
- 用户可以选择不同的存储级别存储RDD以便重用。
- 当前RDD默认是存储于内存,但当内存不足时,RDD会spill到disk。
- RDD在需要进行分区把数据分布于集群中时会根据每条记录Key进行分区(如Hash 分区),以此保证两个数据集在Join时能高效。
◆ RDD的内部表示
在RDD的内部实现中每个RDD都可以使用5个方面的特性来表示:
- 分区列表(数据块列表)
- 计算每个分片的函数(根据父RDD计算出此RDD)
- 对父RDD的依赖列表
- 对key-value RDD的Partitioner【可选】
- 每个数据分片的预定义地址列表(如HDFS上的数据块的地址)【可选】
◆ RDD的存储级别
RDD根据useDisk、useMemory、deserialized、replication四个参数的组合提供了11种存储级别:
- val NONE = new StorageLevel(false, false, false)
- val DISK_ONLY = new StorageLevel(true, false, false)
- val DISK_ONLY_2 = new StorageLevel(true, false, false, 2)
- val MEMORY_ONLY = new StorageLevel(false, true, true)
- val MEMORY_ONLY_2 = new StorageLevel(false, true, true, 2)
- val MEMORY_ONLY_SER = new StorageLevel(false, true, false)
- val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, 2)
- val MEMORY_AND_DISK = new StorageLevel(true, true, true)
- val MEMORY_AND_DISK_2 = new StorageLevel(true, true, true, 2)
- val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false)
- val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, 2)
◆ RDD定义了各种操作,不同类型的数据由不同的RDD类抽象表示,不同的操作也由RDD进行抽实现。
RDD的生成
◆ RDD有两种创建方式:
1、从Hadoop文件系统(或与Hadoop兼容的其它存储系统)输入(例如HDFS)创建。
2、从父RDD转换得到新RDD。
◆ 下面来看一从Hadoop文件系统生成RDD的方式,如:val file = spark.textFile("hdfs://..."),file变量就是RDD(实际是HadoopRDD实例),生成的它的核心代码如下:
- // SparkContext根据文件/目录及可选的分片数创建RDD, 这里我们可以看到Spark与Hadoop MapReduce很像
- // 需要InputFormat, Key、Value的类型,其实Spark使用的Hadoop的InputFormat, Writable类型。
- def textFile(path: String, minSplits: Int = defaultMinSplits): RDD[String] = {
- hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable],
- classOf[Text], minSplits) .map(pair => pair._2.toString) }
- // 根据Hadoop配置,及InputFormat等创建HadoopRDD
- new HadoopRDD(this, conf, inputFormatClass, keyClass, valueClass, minSplits)
◆ 对RDD进行计算时,RDD从HDFS读取数据时与Hadoop MapReduce几乎一样的:
RDD的转换与操作
◆ 对于RDD可以有两种计算方式:转换(返回值还是一个RDD)与操作(返回值不是一个RDD)。
◆ 转换(Transformations) (如:map, filter, groupBy, join等),Transformations操作是Lazy的,也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,Spark在遇到Transformations操作时只会记录需要这样的操作,并不会去执行,需要等到有Actions操作的时候才会真正启动计算过程进行计算。
◆ 操作(Actions) (如:count, collect, save等),Actions操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。
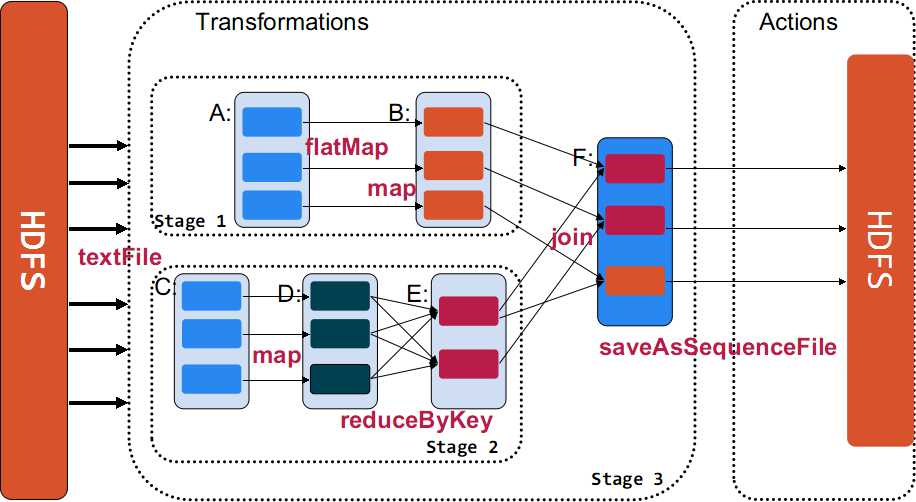
◆ 下面使用一个例子来示例说明Transformations与Actions在Spark的使用。
- val sc = new SparkContext(master, "Example", System.getenv("SPARK_HOME"),
- Seq(System.getenv("SPARK_TEST_JAR")))
- val rdd_A = sc.textFile(hdfs://.....)
- val rdd_B = rdd_A.flatMap((line => line.split("\\s+"))).map(word => (word, 1))
- val rdd_C = sc.textFile(hdfs://.....)
- val rdd_D = rdd_C.map(line => (line.substring(10), 1))
- val rdd_E = rdd_D.reduceByKey((a, b) => a + b)
- val rdd_F = rdd_B.jion(rdd_E)
- rdd_F.saveAsSequenceFile(hdfs://....)