马尔可夫过程
出自 MBA智库百科(http://wiki.mbalib.com/)
马尔可夫过程(Markov Process)
什么是马尔可夫过程
1、马尔可夫性(无后效性)
过程或(系统)在时刻t0所处的状态为已知的条件下,过程在时刻t >
t0所处状态的条件分布,与过程在时刻t0之前年处的状态无关的特性称为马尔可夫性或无后效性。
即:过程“将来”的情况与“过去”的情况是无关的。
2、马尔可夫过程的定义
具有马尔可夫性的随机过程称为马尔可夫过程。
用分布函数表述马尔可夫过程:
设I:随机过程{X(t),t/in T}的状态空间,如果对时间t的任意n个数值:
![]() (注:X(tn)在条件X(ti)
(注:X(tn)在条件X(ti)
= xi下的条件分布函数)
![]() (注:X(tn))在条件X(tn
(注:X(tn))在条件X(tn
− 1) = xn − 1下的条件分布函数)
或写成:
![]()
定义
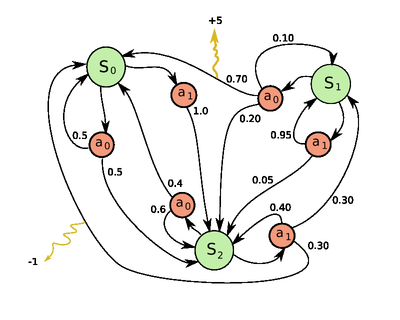
一个很简单的只有3个状态和2个动作的MDP例子。
一个马尔可夫决策过程是一个4 -
元组
![]() ,其中
,其中
S是状态的有限集合,
A是动作的有限集合(或者,As是处于状态s下可用的一组动作的有限集合),
![]() 表示t时刻的动作
表示t时刻的动作
a 将导致马尔可夫过程由状态 s
在t+1
时刻转变到状态s' 的概率。
Ra(s,s')
表示以概率Pa(s,s')从状态 s
转变到状态s'
后收到的即时奖励(或预计即时奖励)。
(马尔可夫决策过程理论实际上并不需要 S
或 A
这两个集合是有限的,但下面的基本算法假定它们是有限的。)
马尔可夫决策过程(MDPs)以安德烈马尔可夫的名字命名,针对一些决策的输出结果部分随机而又部分可控的情况,给决策者提供一个决策制定的数学建模框架。MDPs对通过动态规划和强化学习来求解的广泛的优化问题是非常有用的。MDPs至少早在20世纪50年代就被大家熟知(参见贝尔曼1957年)。大部分MDPs领域的研究产生于罗纳德.A.霍华德1960年出版的《动态规划与马尔可夫过程》。今天,它们被应用在各种领域,包括机器人技术,自动化控制,经济和制造业领域。
更确切地说,一个马尔可夫决策过程是一个离散时间随机控制的过程。在每一个时阶(each time step),此决策过程处于某种状态 s
,决策者可以选择在状态 s
下可用的任何动作 a。该过程在下一个时阶做出反应随机移动到一个新的状态 s',并给予决策者相应的奖励 Ra(s,s')。
此过程选择 s'作为其新状态的概率又受到所选择动作的影响。具体来说,此概率由状态转变函数 Pa(s,s')来规定。因此,下一个状态
s' 取决于当前状态 s
和决策者的动作 a 。但是考虑到状态 s
和动作 a,不依赖以往所有的状态和动作是有条件的,换句话说,一个的MDP状态转换具有马尔可夫特性。
马尔可夫决策过程是一个马尔可夫链的扩展;区别是动作(允许选择)和奖励(给予激励)的加入。相反,如果忽视奖励,即使每一状态只有一个动作存在,那么马尔可夫决策过程即简化为一个马尔可夫链。
![]()
这时称过程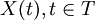 具马尔可夫性或无后性,并称此过程为马尔可夫过程。
具马尔可夫性或无后性,并称此过程为马尔可夫过程。
3、马尔可夫链的定义
时间和状态都是离散的马尔可夫过程称为马尔可夫链, 简记为![]() 。
。
马尔可夫过程的概率分布
研究时间和状态都是离散的随机序列:![]() ,状态空间为
,状态空间为![]()
1、用分布律描述马尔可夫性
对任意的正整数n,r和![]() ,有:
,有:
![]()
PXm + n = aj |
Xm = ai,其中![]() 。
。
2、转移概率
称条件概率Pij(m,m +
n) = PXm + n = aj |
Xm = ai为马氏链在时刻m处于状态ai条件下,在时刻m+n转移到状态aj的转移概率。
说明:转移概率具胡特点:
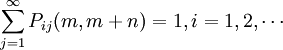 。
。
由转移概率组成的矩阵 称为马氏链的转移概率矩阵。它是随机矩阵。
称为马氏链的转移概率矩阵。它是随机矩阵。
3、平稳性
当转移概率Pij(m,m +
n)只与i,j及时间间距n有关时,称转移概率具有平稳性。同时也称些链是齐次的或时齐的。
此时,记Pij(m,m +
n) = Pij(n),Pij(n) =
PXm + n = aj |
Xm = ai(注:称为马氏链的n步转移概率)
P(n) = (Pij(n))为n步转移概率矩阵。
特别的, 当 k=1 时,
一步转移概率:Pij = Pij(1) =
PXm + 1 = aj | Xm =
ai。
一步转移概率矩阵:P(1)

马尔可夫过程的应用举例
设任意相继的两天中,雨天转晴天的概率为1/3,晴天转雨天的概率为1/2,任一天晴或雨是互为逆事件。以0表示晴天状态,以1表示雨天状态,Xn表示第n天状态(0或1)。试定出马氏链![]() 的一步转移概率矩阵。又已知5月1日为晴天,问5月3日为晴天,5月5日为雨天的概率各等于多少?
的一步转移概率矩阵。又已知5月1日为晴天,问5月3日为晴天,5月5日为雨天的概率各等于多少?
解:由于任一天晴或雨是互为逆事件且雨天转晴天的概率为1/3,晴天转雨天的概率为1/2,故一步转移概率和一步转移概率矩阵分别为:
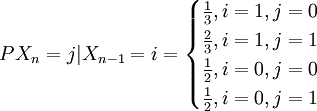

故5月1日为晴天,5月3日为晴天的概率为:
![]()
又由于:
故5月1日为晴天,5月5日为雨天的概率为:P01(4) = 0.5995
问题
MDPs的核心问题是为决策者找到一个这样的策略:找到到函数π,此函数指定决策者处于状态s的时候将会选择的动作π(s)。请注意,一旦一个马尔可夫决策过程以这种方式结合策略,这样可以为每个状态决定动作,由此产生的组合行为类似于马尔可夫链。
我们的目标是选择一个策略π,它将最大限度地积累随机回报,通常预期折扣数目总和超会过一个假定的无限范围:
![]() (当我们选择 at
(当我们选择 at
= π(st ))
其中是折扣率,满足![]() 。它通常接近1。
。它通常接近1。
由于马尔可夫特性,作为上面假设的,特定问题的最优政策的确可以只写成s的功能。