KMP算法
作者:ljs
2011-06-20
(转载请注明出处,谢谢!)
KMP(Knuth–Morris–Pratt)算法的发明时间几乎跟BM(Boyer-Moore)算法在同一时期,即上世纪70年代末(巧合的是随着互联网的发展对文本处理提出了更高的要求,从而最近几年字符处理又成了热门话题),二者在最坏情况下的时间复杂度都是O(n)。它与BM算法的主要区别是:
1)在每次匹配中都是从左到右匹配,BM算法每一次匹配过程都是从模式串末尾开始匹配(指针从右到左移动),直到发现匹配失败字符(mismatch)才根据两张表(好后缀位移表-good suffix shift table和坏字符位移表-bad character shift table)决定向右移动一定的位置,因此在实践中KMP的比较次数一般要多于BM的比较次数,因为BM算法中最好情况下的比较次数为O(n/m)。(比较一下下面的测试输出和我的另一篇BM-Horspool文中的输出,可以看出BM算法或其简化版一开始就从字符串尾部比较的优势了)
2)KMP算法不依赖于字符集的大小,只是根据模式串的信息做预处理,BM算法需要根据字符集给坏字符(因为坏字符的来源是文本,而不是模式串)建立一张位移表,因此KMP算法的存储空间可以少一些。
以下讨论设文本T长度为n,模式串P长度为m。T的当前位置指针为i(0<=i<n),P的当前位置指针为j(0<=j<m)。
KMP算法跟BM算法一样,用空间换取时间,基本的要求是能够最大幅度地向右移动模式串,同时又要保证不会遗漏能够成功匹配的子串。分两大步骤:1) 对模式串预处理,建立失败函数; 2)匹配过程。
****************
首先需要根据模式串预先计算一张表叫做失败函数(failure function) - f(j)。f(j)的变量j对应模式串中的下标,具体含义是,在模式串的前缀P[0...j]这个字符串中,存在一个它的最长的前缀和后缀二者完全相等,该前缀的长度就是f(j)的值。定义f(0)=0。如果不存在这样的前缀和后缀完全相等,f(j)取值为0。
例如:模式串xyzabc,如果j=3, P[j]=a,则考虑前缀xyza中是否存在这样的最长前缀和后缀完全相等,这里不存在,所以f(3)=0; 又如:模式串ABABACA,如果j=4, P[j]=A,则考虑前缀ABABA中是否存在这样的最长前缀和后缀完全相等,这里有一个最长的前缀ABA可以跟等值的后缀重叠,该前缀长度为3,所以f(4)=3。注意f(j)是一个长度值,j是一个索引值,在高级语言中,长度值对应后一个字符的索引值,根据这个特点,可以在KMP算法中将f(j)作为模式串中第j+1个字符出现匹配失败(mismatch)时下一次j指针位置值。
****************
KMP匹配过程也是通过不停地修改i和j的值直到找到匹配的文本子串,需要考虑这几种情况:
1) j指针等于0(即指向模式串的第一个字符位置),但是T[i] != P[j],这时需要将模式串的第一个字符与文本的下一个字符比较,即i指针加1,但是j指针仍为0。
2)j指针不等于0,前面连续的j个字符P[0...j-1]与T[i-j...i-1]都匹配成功,这时候就要用到失败函数f了。具体做法是把f[j-1]的值作为下一次的j值,但是i指针的值不变,这样保证不会遗漏能够成功匹配的子串。例如: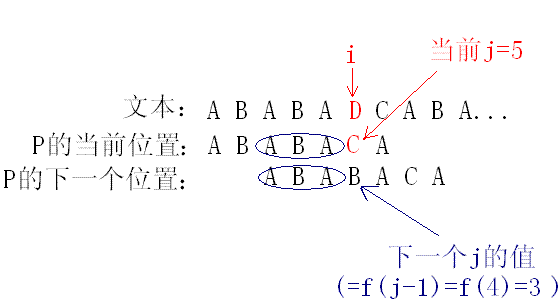
有趣的是计算失败函数f可以使用KMP匹配算法本身的算法过程,这是因为计算f实质上就是模式串与自身匹配的过程,只是在匹配一开始,需要将模式串向右错开一个字符位置(即i=1,j=0)。
实现:
测试输出: