上篇说了半天,却回避了一个重要的问题:为什么要用异步呢,它有什么样的好处?坦率的说,我对这点的认识不是太深刻(套句俗语,只可意会,不可言传)。还是举个例子吧:
比如Client向Server发送一个request,Server收到后需要100ms的处理时间,为了方便起见,我们忽略掉网络的延迟,并且,我们认为Server端的处理能力是无穷大的。在这个use case下,如果采用同步机制,即Client发送request -> 等待结果 -> 继续发送,那么,一个线程一秒钟之内只能够发送10个request,如果希望达到10000 request/s的发送压力,那么Client端就需要创建1000个线程,而这么多线程的context switch就成为client的负担了。而采用异步机制,就不存在这个问题了。Client将request发送出去后,立即发送下一个request,理论上,它能够达到网卡发送数据的极限。当然,同时需要有机制不断的接收来自Server端的response。
以上的例子其实就是这篇的主题,异步的消息机制,基本的流程是这样的:
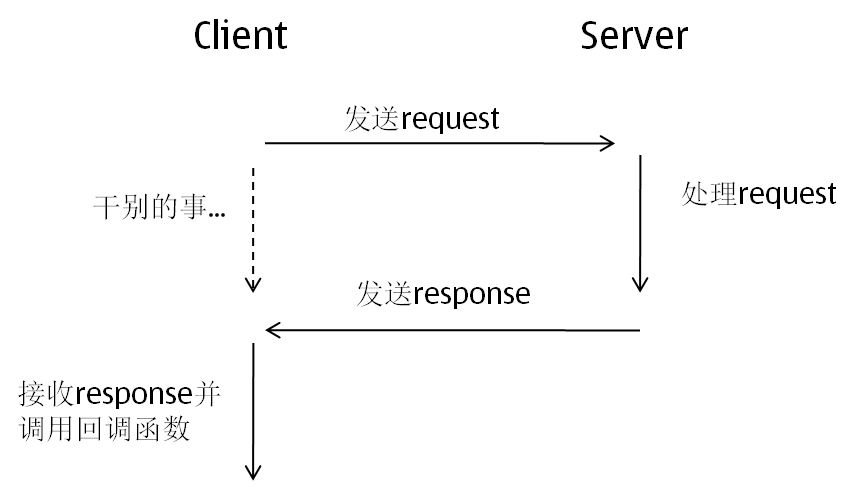
如果仔细琢磨的话,会发现这个流程中有两个很重要的问题需要解决:
1. 当client接收到response后,怎样确认它到底是之前哪个request的response呢?
2. 如果发送一个request后,这个request对应的response由于种种原因(比如server端出问题了)一直没有返回。client怎么能够发现类似这样长时间没有收到response的request呢?
对于第一个问题,一般会尝试给每个request分配一个独一无二的ID,返回的Response会同时携带这个ID,这样就能够将request和response对应上了。
对于第二个问题,需要有一个timeout机制,对于每一个request都有一个定时器,如果到指定时间仍然没有返回结果,那么会触发timeout操作。多说一句,timeout机制其实对于涉及网络的同步机制也是非常有必要的,因为有可能client与server之间的链接坏了,在极端情况下,client会被一直阻塞住。
纸上谈兵了这么久,还是看一个实际的例子。我在这里用Hadoop的RPC代码举例。这里需要事先说明的是,Hadoop的RPC对外的接口其实是同步的,但是,RPC的内部实现其实是异步消息机制。多说无益,直接看代码吧(讨论的所有代码都在org.apache.hadoop.ipc.Client.java
里):
这就是Client.java对外提供的接口。一共有两个参数,param是希望发送的request,remoteId是指远程server对应的Id。函数的返回就是response(也是继承自writable)。所以说,这是一个同步调用,一旦call函数返回,那么response也就拿到了。
call函数的具体实现一会再看,先介绍Client中两个重要的内部类:
call这个类对应的就是一次异步请求。它的几个成员变量:
id: 这个就是之前提过的,对于每一个request都需要分配一个唯一标示符,这样接收到response后才能知道到底对应哪个request;
param: 需要发送到server的request;
value: 从server发送过来的response;
error: 可能发生的异常(比如网络读写错误,server挂了,等等);
done: 表示这个call是否成功完成了,即是否接收到了response;
Connection这个类要比之前的Call复杂得多,所以我省略了很多这里不会被讨论的代码。
Connection对应于一个连接,即一个socket。但同时,它又继承自Thread,所有它本身又对应于一个线程。可以看出,在Hadoop的RPC中,一个连接对应于一个线程。先看他的成员变量:
server: 这是远程server的地址;
socket: 对应的socket;
in / out: socket的输入流和输出流;
calls: 重要的成员变量。它是一个hash表, 维护了这个connection正在进行的所有call和它们对应的id之间的关系。当读取到一个response后,就通过id在这张表中找到对应的call;
再看看它的run()函数。这是Connection这个线程的启动函数,我贴的代码中这个函数没做任何的删减,你可以发现,刨除一些冗余代码,这个函数其实就只做了一件事:receiveResponse,即等待接收response。
OK。回到call()这个函数,看看它到底做了什么:
首先,它创建了一个新的call(这个call是Call类的实体,注意和call()函数的区分),然后根据remoteId找到对应的connection(Client类中维护了一个connection pool),然后调用connection.sendParam()。从前面找到这个函数,你会发现它就是将request写入到socket,发送出去。
但值得一提的是,它使用的write是最普通的blocking IO,也是同步IO(后面会看到,它读取response也是用的blcoking IO,所以,hadoop RPC虽然是异步机制,但是采用的是同步blocking IO,所以,异步消息机制还采用什么样的IO机制是没有关系的)。
接下来,调用了call.wait(),将线程阻塞在这里。直到在某个地方调用了call.notify(),它才重新运行起来,然后一通判断后返回call.value,即接收到的response。
所以,剩下的问题是,到底是哪调用了call.notify()?
回到connection的receiveResponse函数:
首先,它从socket的输入流中读到一个id,然后根据这个id找到对应的call,调用call.setValue将从socket中读取的response放入到call的value中,然后调用calls.remove(id)将这个call从队列中移除。这里要注意的是call.setValue,这个函数将value设置好之后,调用了call.notify()!
好了,让我们再重头将流程捋一遍:
这里其实有两个线程,一个线程是调用Client.call(),希望向远程server发送请求的线程,另外一个线程就是connection对应的那个线程。当然,虽然有两个线程,但server对应的只有一个socket。第一个线程创建call,然后调用call.sendParam将request通过这个socket发送出去;而第二个线程不断的从socket中读取response。因此,request的发送和response的接收被分隔到不同的线程中执行,而且这两个线程之间关于socket的读写并没有任何的同步机制,因此我认为这个RPC是异步消息机制实现的,只不过通过call.wait()/call.notify()使得对外的接口看上去像是同步。
好了,Hadoop的RPC介绍完了(虽然我略掉了很多内容,比如timeout机制我这里就没写),说说我个人的评价吧。我认为,Hadoop的这个设计还是挺巧妙的,底层采用的是异步机制,但对外的接口提供的又是一般人比较习惯的同步方式。但是,我觉着缺点不是没有,一个问题是一个链接就要产生一个线程,这个如果是在几千台的cluster中,仍然会带来巨大的线程context switch的开销;另一个问题是对于同一个remote server只有一个socket来进行数据的发送和接收,这样的设计网络的吞吐量很有可能上不去。(一家之言,欢迎指正)
未完待续~