Google
BigTable阅读笔记
摘要
Google BigTable是一个分布式的结构化数据存储系统,用来存储海量的数据,这些数据分布在以千计数的普通PC集群上(GFS,MapReduce都是分布在这样的集群上)。
Google有很多项目都使用BigTable存储数据,如Web索引、Google地图、Google金融等。这些应用对存储量、响应速度、吞吐量需求各异,但BigTable还是成功成为一个灵活且高性能的解决方案。
1.概要
BigTable是一个分布式的结过婚数据存储系统,它存储着PB级别的数据。
BigTable的设计目标是:
(1)适用性广;
(2)扩展方便;
(3)高性能;
(4)高可用;
BigTable和数据库比较类似,它的实现参照了很多数据库的实现策略(并行数据库,内存数据库),但它提供了一套完全不同的接口;
BigTable不支持关系型模型,即不支持schema,它提供的模型允许用户动态控制数据的分布和格式;
BigTable视一切数据为字符串,用户可以把结构化或半结构化的数据串行化到字符串里,进行存储;
2.数据模型
BigTable是一个稀疏的、分布式的、持久化存储的多维排序map,map的索引是行名称、列名称、时间戳,value是只有用户能理解含义的二进制串。
(row:string + column:string + time:int64) => (string)
为什么设计成这样的数据模型呢?首先考虑一种常见的应用,存储网页(webtable):
URL为关键字,URL含有各种属性,每种属性有一定的历史,如下图
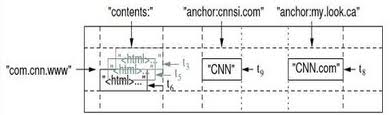
图一:网页存储片段
行(rows):
(1)表中的行是任意的字符串(64k上限),对每一行的读写都是原子的;
(2)BigTable通过行关键字组织数据,每个行都能动态分区,每个分区叫一个子表(tablet),子表是数据分布与负载均衡的最小单位;
(3)第二点保证了读取行中少数几列的数据时效率很高,应用层还能利用位置相关特性,将一些需要的数据放置在一起。
仍以存储网页为例:
能够以URL主域反转作为key,进行网页的存储,这样同一个主域下的网页都存在一起,能够提高查询效率。
com.google.maps/site1.html
com.google.maps/site2.html
列族(column families):
(1)列关键字组成的集合叫列族,列族是访问控制的基本单位;
(2)同一个列族下的数据通常类型相同;
(3)列族必须先创建才能使用,创建后,任何一个列关键字下都能存放数据。
(4)一张表可以有无限多个列;
一般来说,一张表中列族不能太多(几百个足以),并且列族在运行期间很少改变。
列族名称由 族名称(family)+限定符(qualifier)组成,其中:
(1)族名称必须是可打印字符;
(2)限定符可以是任意字符;
访问控制、磁盘以及内存的使用统计都是在列族层面进行的。仍以存储网页为例,权限控制能允许某些应用添加新的基本数据、某些应用读取基本数据并创建继承的列族、一些应用则只能浏览。
时间戳(timestamps):
(1)时间戳类型为int64,精度为毫秒;
(2)一份数据可以有多个时间戳版本,以避免版本冲突;
(3)不同时间戳版本的数据按时间戳降序排列,即最新的数据在最前面;
一般来说,只会保存某个数据的最近n个版本,可以设置参数定期进行垃圾收集。
以存储网页为例,存储的网页的时间戳是网页的抓取时间,垃圾收集机制能保证只存储最近3个版本的网页数据。
3.API
BigTable提供了建立和删除表以及列族的API,修改集群、表、列族元数据的API,例如访问权限。
客户端程序能通过这些API对BigTable进行如下操作:
(1)写入或者删除BigTable中的值;
(2)从每行中遍历、查找BigTable的表中的数据子集;
(3)单行上的事务处理,利用这个功能,可以对一个行关键字下的数据进行原子的读-更新-写操作(BigTable并不支持跨行的事务操作);
(4)BigTable允许把数据项作为整数计数器;
(5)BigTable允许用户在服务器的地址空间执行脚本程序;
(6)BigTable可以和MapReduce一起使用,可以利用已开发的wrapper类,把BigTable当做MapReduce的输入和输出。
4.基础构件
BigTable是建立在其他几个Google基础构建基础上的高级别应用:
(1)BigTable使用GFS存储日志、数据文件;
(2)BigTable使用SSTable作为内部存储数据的格式;
(3)BigTable依赖于高可用、序列化的分布式所服务Chubby;
5.实现
BigTable包括三个主要组件:可链入客户端程序的库、一个Master服务器和多个子表(tablet)服务器;针对系统的负载情况,能够很容易的向集群中添加和删除子表服务器。
Master服务器主要负责以下工作:
(1)为子表服务器分配子表;
(2)检测加入或者失效的子表服务器;
(3)均衡子表服务器负载;
(4)对GFS上的文件进行垃圾回收;
(5)相关schema的修改与维护;
Tablet服务器主要负责的工作:
(1)管理子表集合;
(2)子表的读写处理;
(3)子表过大时,自动分隔;
和大部分的单Master分布式系统类似,数据流均不经过Master服务器,客户端直接和Tablet服务器通信,进行数据的读写。
BigTable的客户端程序不必通过Master服务器来获取子表的位置信息,大多数客户端程序甚至完全不用和Master交互。
一个BigTable集群存储了很多表,每个表包含一个子表集合,而每个子表包含某个范围内行的所有数据。初始状态下,每个表只有一个子表,随着数据量的增长,子表会自动分割为100M级别的多个子表。
5.1子表的位置
使用一个三层、类似B+数的结构存储子表的位置信息。

Google BigTable子表位置信息
图二:子表位置信息存储
(1)第一层是一个存储在Chubby中的文件,包含根子表(Root Tablet)的位置信息。
根子表包含了一个特殊的元数据(metadata)表里所有的子表位置信息。元数据表的每个子表包含一个用户子表的集合。
跟子表实际上是元数据表的第一个子表,它被特殊处理过–它永远不会被分割;
(2)第二层是其它各个元数据表,每个子表的位置信息都放在一个行关键字下面,这个关键字由子表所在表的标示符和子表的最后一行编码而成;
(3)第三册是用户子表表的位置信息;
客户端会在树状的存储结构查询子表的位置信息,并缓存这些信息。
5.2子表分配
任何时刻,一个子表只能分配给一个子表服务器。Master中记录了哪些可用的子表服务器,哪些子表分配给了哪些子表服务器等元信息。
当一个子表没有被分配,且某个子表服务器有足够的空间来装载子表,Master会发送装载控制指令给该子表服务器,完成子表的分配。
BigTable使用Chubby跟踪子表服务器的状态,当一个子表服务器启动时,在Chubby的指定目录下会创建一个唯一的文件,代表独占锁。
Master服务器实时监控这个目录,便能知道是否有新的子表服务器加入。如果丢失了独占锁,例如断网、会话丢失、子表服务器自然终止,就认为该子表服务器其停止了子表的服务。
此时Master服务器就会尽快的把子表分配给其他的子表服务器。
如果子表服务器挂掉之前来不及释放自己的独占锁也没有关系,Master会有定时心跳,尝试与子表服务器通信,若无回应,Master会主动解除Chubby上的文件锁。
Master启动时,必须要了解当前子表的分配状态,之后才能修改分配状态,启动步骤为:
(1)Master从Chubby获取唯一的Master锁,以防止集群进入其他的Master;
(2)Master扫描Chubby文件锁目录,获取正在运行的子表服务器列表;
(3)和所有子表服务器通信,获取所有子表分配信息;
(4)扫描元数据表获取所有子表的集合;
5.3子表服务

Google BigTable子表服务
图三:子表服务
如图所示,子表的持久化信息是保存在GFS上的。所有更新日志提交到重做(REDO)日志中。在这些更新操作中,最新提交的那些数据存放在一个排序的缓存中,我们称这个缓存为memtable;较早的更新存放在SSTable中。
为了恢复一个子表,子表服务器首先从元数据表中读取它的元数据,元数据包含组成这个子表的SSTable的列表,以及重做点(REDO point)的集合,这些重做点指向可能含有该子表数据的已提交日志。
子表服务器把SSTable的索引读进内存,通过再次执行重做点之后提交的更新再重建memtable。
(1)对子表服务器的写操作步骤:
检测操作格式,例如完整性;
检测发起者权限;
记录成功操作的日志;
写的内容插入到memtable里。
(2)对子表服务器的读操作步骤:
完整性与权限检查;
合并SSTable与memtable视图完成读数据的合并;
5.4数据压缩(compactions)
数据压缩分为三种:
(1)最小化压缩;
(2)合并压缩;
(3)最大化压缩;
随着写操作的执行,memtable的大小不断增加,当达到一个门限值时,就不再增长,而是转化为SSTable,写入GFS,这种压缩成为最小化压缩(Minor Compaction)
最小化压缩的目的:
(1)限制使用内存:memtable是在内存中的,必须限制大小;
(2)容灾恢复时,减少日志读取量:memtable中的数据是易失的,灾难恢复时,结合SSTABLE+最新的日志就能恢复所有数据;
每次最小化压缩会创建一个SSTable,如果一直实施最小化更新,创建更多的SSTable,则可能导致读操作来临时要读取多个SSTable上的更新数据以获取最新的结果;
解决该问题的方法是:定期后台合并SSTable和memtable的内容,组成的新有序SSTable,这个过程叫合并压缩(Merging Compaction),合并压缩完成后,合并之前的SSTable和memtable就能够被删除了。
合并所有SSTable的合并压缩称为最大化压缩(Major Compaction);最大化压缩是为了解决合并压缩中可能存在被删除数据。
BigTable定期循环扫描所有子表,执行最大化压缩。这种机制允许BigTable按时回收被删除的资源。
6.优化
为了达到对用户的高性能、高可用、高可靠性要求,做了如下优化:
(1)局部性分组(locality groups)
为了提高访问效率,通常不会一起访问的列族分割成不同的局部性分组,例如网页、网页元数据。
(2)压缩(compression)
压缩的目的是减少存储空间;
(3)缓存(Caching)
(4)bloom filter优化
bloom filter是一个经典数据结构:它能快速准备的判断一个元素不在一个集合中。
Google用它来优化判断SSTable的位置。
(5)日志提交实现
追加日志;
日志关键字排序;
(6)快速恢复
子表从一个子表服务器转移到另一个子表服务器时,必须先做一次最小化压缩;
这样做的好处是,新子表服务器装载子表时不需要从日志中进行恢复。
(7)不变性
SSTable是固化到磁盘上的,因此其访问无需同步;
删除也可以通过标记完成;
7.经验教训
(1)任何错误随时都可能发生:网络中断、协议错误、内存数据顺滑、时钟偏差、网络分区;
(2)添加特性需要慎重:分行事务真的需要么?
(3)监控尤其重要;
(4)简介的设计和编码会给维护和调试带来巨大的帮助;