首先要清楚的是:
Http协议的交互要有一定的认识.Http是基于TCP的.是应用层的协议,基于连接的.
Http是一个基于请求/响应模式的,无状态的协议(request/response based ,stateless protocol),无状态即是我先发给了你一个请求,后面我又发一个请求,服务器是不知道你先前发过一次请求的.有时候是要克服这个的,如登录了之后我就可以访问一些资源.
HTTP1.0和HTTP1.1的区别在于建立的连接数,请求数是一样的.
方法其实对应于数据库中的crud
Get:query
put:save
post:update
delete方法:delete
那么它们之间是如何进行连接的呢?实际上就是跟TCP的那个连接是一样的意思:服务端启动之后就监听,看客户端有没有对他进行的连接,这就是HTTP连接的原理
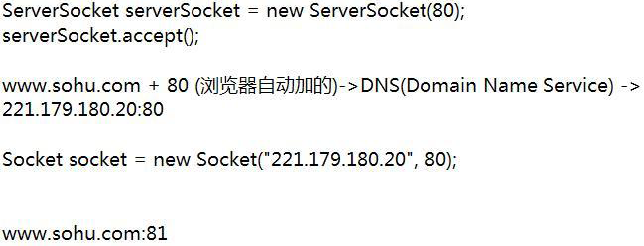
Http1.0和Http1.1的区别:
在Http1.0中,当连接建立后,浏览器发送一个请求,服务器回应一个消息,之后,连接就被关闭。当浏览器下次请求的时候,需要重新建立连接,很显然这种需要不断建立连接的通信方式开销比较大。早期的Web页面通常只包含HTML文本,因此即使建立连接的开销比较大,也不会有太大的影响。而现在的Web页面往往包含多种资源(图片,动画,声音等),每获取一种资源,就建立一次连接,这样就增加了HTTP服务器的开销,造成了Internet上的信息堵塞
在Http1.1版本中,给出了一个持续连接(Persistent Connections)的机制,并将其作为Http1.1中建立连接的缺省行为。通过这种连接,浏览器可以在建立一个连接之后,发送请求并得到回应,然后继续发送请求并再次得到回应。而且,客户端还可以发送流水线请求,也就是说,客户端可以连续发送多个请求,而不用等待每一个响应的到来,这里有个超时的概念,当你多长时间没有去连接服务端时,服务端自动断开连接
一个WEB站点每天可能要接收到上百万的用户请求,为了提高系统的效率,HTTP 1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。但是,这也造成了一些性能上的缺陷,例如,一个包含有许多图像的网页文件中并没有包含真正的图像数据内容,而只是指明了这些图像的URL地址,当WEB浏览器访问这个网页文件时,浏览器首先要发出针对该网页文件的请求,当浏览器解析WEB服务器返回的该网页文档中的HTML内容时,发现其中的<img>图像标签后,浏览器将根据<img>标签中的src属性所指定的URL地址再次向服务器发出下载图像数据的请求
HTTP请求和HTTP响应:
HTTP请求由三部分组成,分别是:请求行,消息报头,请求正文
请求行以一个方法符号开头,后面跟着请求URI和协议的版本,以CRLF作为结尾。请求行以空格分隔。除了作为结尾的CRLF外,不允许出现单独的CR或LF字符,格式如下:
– Method Request-URI HTTP-Version CRLF
Method表示请求的方法,Request-URI是一个统一资源标识符,标识了要请求的资源,HTTP-Version表示请求的HTTP协议版本, CRLF表示回车换行。例如:
– GET /test.html HTTP/1.1 (CRLF)
最主要的两个方法就是GET和POST
GET方法用于获取由Request-URI所标识的资源的信息,常见形式是:
–GET Request-URI HTTP/1.1,都是放在请求行里面的
POST方法用于向服务器发送请求,要求服务器接受附在请求后面的数据。POST方法在表单提交的时候用的最多
•采用POST方法提交表单的例子,是放在请求体里面的
POST /login.jsp HTTP/1.1 (CRLF)
Accept:image/gif (CRLF) (….)
Host:www.sample.com (CRLF)(….)
….
Cache-Control:no=cache (CRLF)
(CRLF)注意这里有两个回车换行,表示下面的是请求体,以上的是请求头
username=hello&password=123456
还有一个常用的方法就是HEAD
HEAD方法与GET方法几乎是一样的,他们的区别在于HEAD方法只是请求消息报头,而不是完整的内容。对于HEAD请求的回应部分来说,它的HTTP头部中包含的信息与通过GET请求所得到的信息是相同的。利用这个方法,不必传输整个资源的内容,就可以得到Request-URI所标识的资源的信息。这个方法通常用于测试超链接的有效性,是否可以访问,以及最近是否更新等
与HTTP请求类似,HTTP响应也是由三个部分组成,分别是:状态行,消息报头,响应正文
状态行由协议版本,数字形式的状态代码,相应的状态描述组成,各元素之间以空格分隔,除了结尾的CRLF(回车换行)序列外,不允许出现CR或LF字符。格式如下:
–HTTP-Version Status-Code Reason-Phrase CRLF
•HTTP-Version表示服务器HTTP协议的版本,Status-Code表示服务器发回的响应代码,Reason-Phrase表示状态代码的文本描述, CRLF表示回车换行,例如:
–HTTP/1.1 200 OK (CRLF)
Http消息:
HTTP消息由客户端到服务器的请求和服务器到客户端的响应组成。请求消息和响应消息都是由开始行,消息报头(可选),空行(只有CRLF的行),消息正文(可选)组成。
•对于请求消息,开始行就是请求行,对于响应消息,开始行就是状态行
还有一点需要注意的是:
get与post方法之间的差别:
1) 浏览器地址栏呈现的结果不同(表象)
2) 真正的原因在于向服务器端发送请求时的形式是不同的
get的请求格式: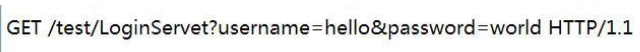
post的请求格式:
通过浏览器进行文件上传时,一定要使用post方式而绝不能使用get方式。原因是:,因为get方式请求时对它的信息的长度是有要求的,但是post却是没有限制的.
JAVAWeb中的应用的部署方式多种多样,主要有三种:
配置项目启动的方式多种多样,
1)<Context path="/test" docBase="D:/JAVA/JAVA WEB/shengsiyuan/test/WebRoot" reloadable="true"/>这种方式应该是比较好的一种方式.path是逻辑路径,docBase是物理路径,path是项目的上下文路径,注意的是它跟项目名没有任何的关系的
2)通过MyEclipse的方式去部署的时候实际上在tomcat的webapp里面的那个test本质上就是WebRoot,不建议使用这个方式去部署,这太依赖于IDE了,有些公司不会使用MyEclipse的,而且有个弱点,每次都去部署,浪费时间.
3)把webroot的目录拷贝到webapp那里去,然后修改名字.