下面是网上看到的一些关于内存和CPU方面的一些很不错的文章. 整理如下:
转: CPU的等待有多久?
原文标题:What Your Computer Does While You Wait
原文地址:http://duartes.org/gustavo/blog/
[注:本人水平有限,只好挑一些国外高手的精彩文章翻译一下。一来自己复习,二来与大家分享。]
本文以一个现代的、实际的个人电脑为对象,分析其中CPU(Intel Core 2 Duo 3.0GHz)以及各类子系统的运行速度——延迟和数据吞吐量。通过粗略的估算PC各个组件的相对运行速度,希望能给大家留下一个比较直观的印象。本文中的数据来自实际应用,而非理论最大值。时间的单位是纳秒(ns,十亿分之一秒),毫秒(ms,千分之一秒),和秒(s)。吞吐量的单位是兆字节(MB)和千兆字节(GB)。让我们先从CPU和内存开始,下图是北桥部分:
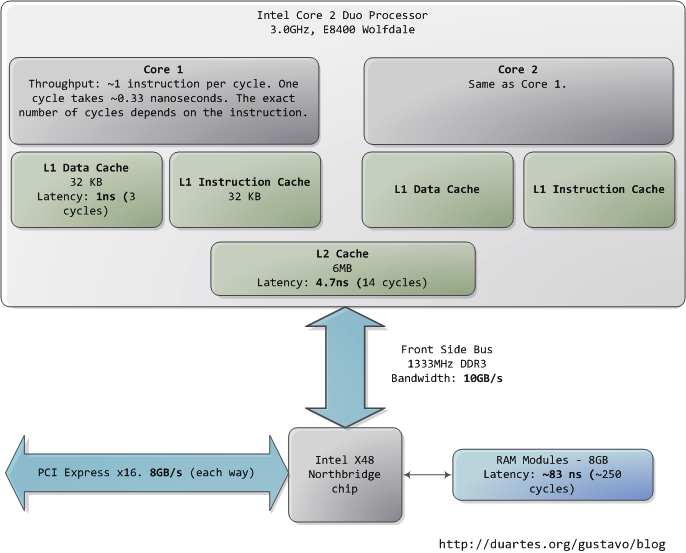
第一个令人惊叹的事实是:CPU快得离谱。在Core 2 3.0GHz上,大部分简单指令的执行只需要一个时钟周期,也就是1/3纳秒。即使是真空中传播的光,在这段时间内也只能走10厘米(约4英寸)。把上述事实记在心中是有好处的。当你要对程序做优化的时候就会想到,执行指令的开销对于当今的CPU而言是多么的微不足道。
当CPU运转起来以后,它便会通过L1 cache和L2 cache对系统中的主存进行读写访问。cache使用的是静态存储器(SRAM)。相对于系统主存中使用的动态存储器(DRAM),cache读写速度快得多、造价也高昂得多。cache一般被放置在CPU芯片的内部,加之使用昂贵高速的存储器,使其给CPU带来的延迟非常低。在指令层次上的优化(instruction-level optimization),其效果是与优化后代码的大小息息相关。由于使用了高速缓存技术(caching),那些能够整体放入L1/L2 cache中的代码,和那些在运行时需要不断调入/调出(marshall into/out of)cache的代码,在性能上会产生非常明显的差异。
正常情况下,当CPU操作一块内存区域时,其中的信息要么已经保存在L1/L2 cache,要么就需要将之从系统主存中调入cache,然后再处理。如果是后一种情况,我们就碰到了第一个瓶颈,一个大约250个时钟周期的延迟。在此期间如果CPU没有其他事情要做,则往往是处在停机状态的(stall)。为了给大家一个直观的印象,我们把CPU的一个时钟周期看作一秒。那么,从L1 cache读取信息就好像是拿起桌上的一张草稿纸(3秒);从L2 cache读取信息则是从身边的书架上取出一本书(14秒);而从主存中读取信息则相当于走到办公楼下去买个零食(4分钟)。
主存操作的准确延迟是不固定的,与具体的应用以及其他许多因素有关。比如,它依赖于列选通延迟(CAS)以及内存条的型号,它还依赖于CPU指令预取的成功率。指令预取可以根据当前执行的代码来猜测主存中哪些部分即将被使用,从而提前将这些信息载入cache。
看看L1/L2 cache的性能,再对比主存,就会发现:配置更大的cache或者编写能更好的利用cache的应用程序,会使系统的性能得到多么显著的提高。如果想进一步了解有关内存的诸多信息,读者可以参阅Ulrich Drepper所写的一篇经典文章《What Every Programmer Should Know About Memory》。
人们通常把CPU与内存之间的瓶颈叫做冯·诺依曼瓶颈(von Neumann bottleneck)。当今系统的前端总线带宽约为10GB/s,看起来很令人满意。在这个速度下,你可以在1秒内从内存中读取8GB的信息,或者10纳秒内读取100字 节。遗憾的是,这个吞吐量只是理论最大值(图中其他数据为实际值),而且是根本不可能达到的,因为主存控制电路会引入延迟。在做内存访问时,会遇到很多零 散的等待周期。比如电平协议要求,在选通一行、选通一列、取到可靠的数据之前,需要有一定的信号稳定时间。由于主存中使用电容来存储信息,为了防止因自然 放电而导致的信息丢失,就需要周期性的刷新它所存储的内容,这也带来额外的等待时间。某些连续的内存访问方式可能会比较高效,但仍然具有延时。而那些随机 的内存访问则消耗更多时间。所以延迟是不可避免的。
图中下方的南桥连接了很多其他总线(如:PCI-E, USB)和外围设备:
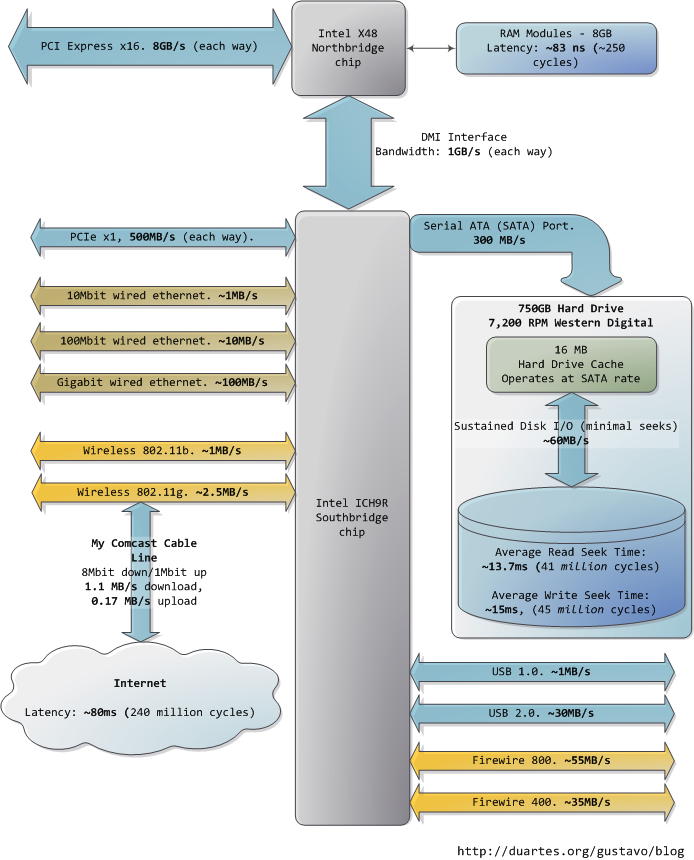
令人沮丧的是,南桥管理了一些反应相当迟钝的设备,比如硬盘。就算是缓慢的系统主存,和硬盘相比也可谓速度如飞了。继续拿办公室做比喻,等待硬盘寻道的时间相当于离开办公大楼并开始长达一年零三个月的环球旅行。这就解释了为何电脑的大部分工作都受制于磁盘I/O,以及为何数据库的性能在内存缓冲区被耗尽后会陡然下降。同时也解释了为何充足的RAM(用于缓冲)和高速的磁盘驱动器对系统的整体性能如此重要。
虽然磁盘的"连续"存取速度确实可以在实际使用中达到,但这并非故事的全部。真正令人头疼的瓶颈在于寻道操作,也就是在磁盘表面移动读写磁头到正确的磁道上,然后再等待磁盘旋转到正确的位置上,以便读取指定扇区内的信息。RPM(每分钟绕转次数)用来指示磁盘的旋转速度:RPM越大,耽误在寻道上的时间就越少,所以越高的RPM意味着越快的磁盘。这里有一篇由两个Stanford的研究生写的很酷的文章,其中讲述了寻道时间对系统性能的影响:《Anatomy of a Large-Scale Hypertextual Web Search Engine》
当 磁盘驱动器读取一个大的、连续存储的文件时会达到更高的持续读取速度,因为省去了寻道的时间。文件系统的碎片整理器就是用来把文件信息重组在连续的数据块 中,通过尽可能减少寻道来提高数据吞吐量。然而,说到计算机实际使用时的感受,磁盘的连续存取速度就不那么重要了,反而应该关注驱动器在单位时间内可以完 成的寻道和随机I/O操作的次数。对此,固态硬盘可以成为一个很棒的选择。
硬盘的cache也有助于改进性能。虽然16MB的cache只能覆盖整个磁盘容量的0.002%,可别看cache只有这么一点大,其效果十分明显。它可以把一组零散的写入操作合成一个,也就是使磁盘能够控制写入操作的顺序,从而减少寻道的次数。同样的,为了提高效率,一系列读取操作也可以被重组,而且操作系统和驱动器固件(firmware)都会参与到这类优化中来。
最后,图中还列出了网络和其他总线的实际数据吞吐量。火线(fireware)仅供参考,Intel X48芯片组并不直接支持火线。我们可以把Internet看作是计算机之间的总线。去访问那些速度很快的网站(比如google.com),延迟大约45毫秒,与硬盘驱动器带来的延迟相当。事实上,尽管硬盘比内存慢了5个数量级,它的速度与Internet是在同一数量级上的。目前,一般家用网络的带宽还是要落后于硬盘连续读取速度的,但"网络就是计算机"这句话可谓名符其实。如果将来Internet比硬盘还快了,那会是个什么景象呢?
我希望这些图片能对您有所帮助。当这些数字一起呈现在我面前时,真的很迷人,也让我看到了计算机技术发展到了哪一步。前文分开的两个图片只是为了叙述方便,我把包含南北桥的整张图片也贴出来,供您参考。
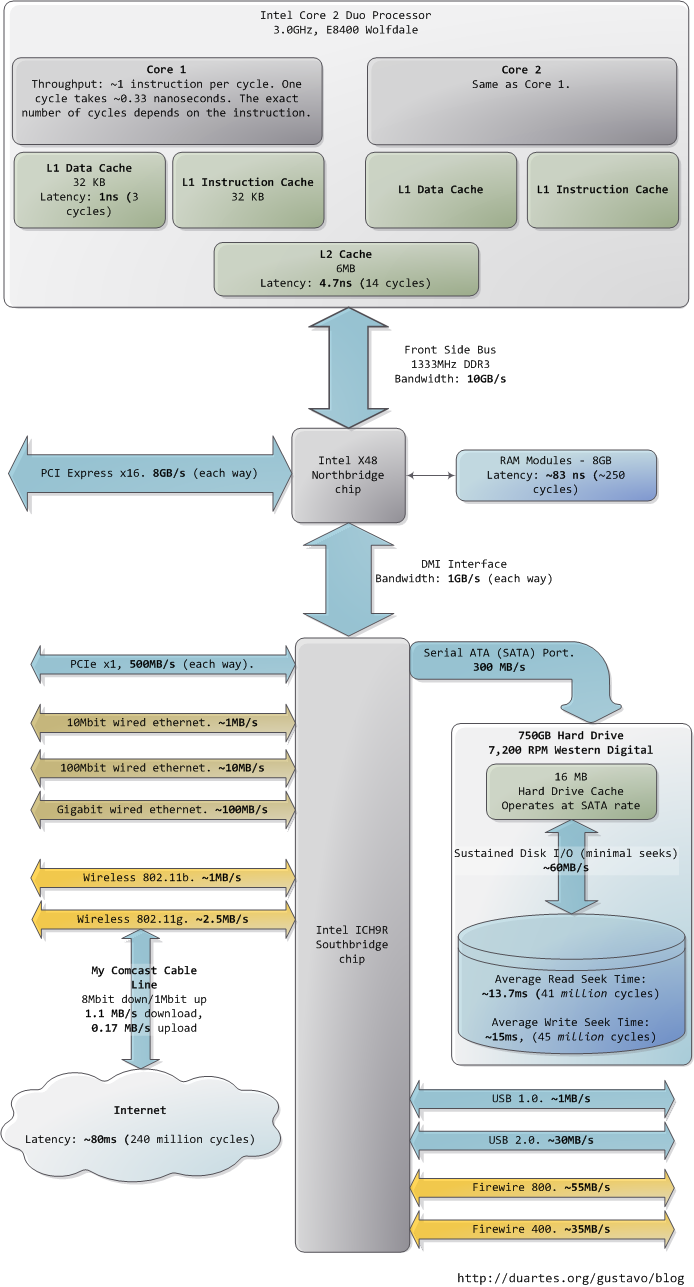
参考: http://blog.csdn.net/drshenlei/article/details/4240703
转: CPU如何操作内存
原文标题:Getting Physical With Memory
原文地址:http://duartes.org/gustavo/blog/
[注:本人水平有限,只好挑一些国外高手的精彩文章翻译一下。一来自己复习,二来与大家分享。]
在你试图理解一个复杂的系统时,如果能揭去表面的抽象并专注于最低级别的概念,往往会有不小的收获。在这个精神的指导下,让我们看看对于内存和I/O端口操作来说最简单、最基础的概念,即CPU与总线之间的接口。其中的细节是很多上层概念的基础,比如线程同步。当然了,既然我是个程序员,就暂且忽略那些只有电子工程师才会去关注的东西吧。下图是我们的老朋友,Core 2:
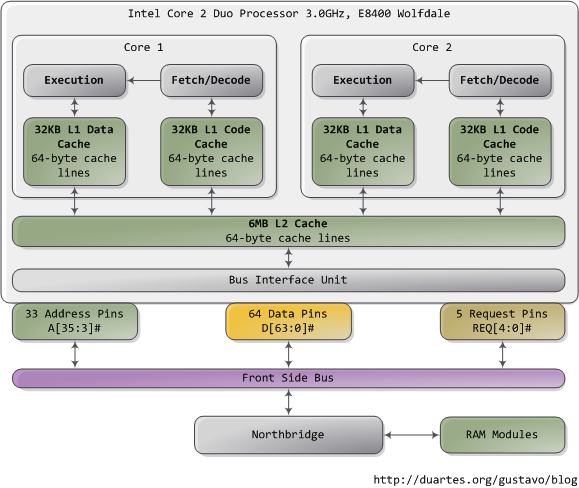
Core 2 处理器有775个管脚,其中约半数仅仅用于供电而不参与数据传输。当你把这些管脚按照功能分类后,就会发现这个处理器的物理接口惊人的简单。本图展示了参与内存和I/O端口操作的重要管脚:地址线,数据线,请求线。这些操作均发生在前端总线的事务上下文结构(the context of a transaction)中。前端总线事务的执行包含五个阶段:仲裁,请求,侦听,响应,数据操作。在执行事务的过程中,前端总线上的各个部件扮演着不同的角色。这些部件称之为agent。通常,agent就是全部的处理器外加北桥。
本文只分析请求阶段。在此阶段中,发出请求的agent往往是一个处理器,它输出两个数据包。下图列出了第一个数据包中最为重要的位,这些数据位通过处理器的地址线和请求线输出:
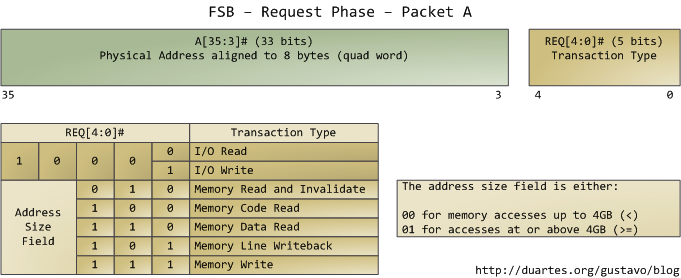
地址线输出指定了事务发生的物理内存起始地址。我们有33条地址线,他们指定了数据包的第35至第3位,第2至第0位为0。因此,实际上这33条地址线构成了一个36位的、以8字节对齐的地址,正好覆盖64GB的物理内存。这种设定从奔腾Pro就开始了。请求线指定了事务的类型。当事务类型为I/O请求时,地址线指出的是I/O端口地址而不是内存地址。当第一个数据包被发送以后,同样由这组管脚,在下一个总线时钟周期发送第二个数据包:
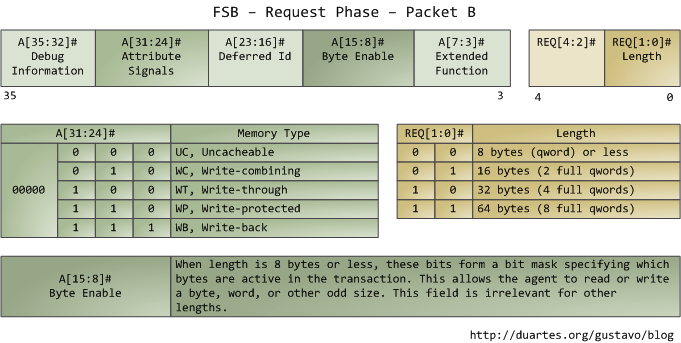
属性信号(attribute signal A[31:24])很有趣,它反映了Intel处理器所支持的5种内存缓冲功能。把这些信息发布到前端总线后,发出请求的agent就可以让其他处理器知道如何根据当前事务处理他们自己的cache,以及让内存控制器(也就是北桥)知道该如何应对。一块指定内存区域的缓存类型由处理器通过查询页表(page table)来决定,页表由OS内核维护。
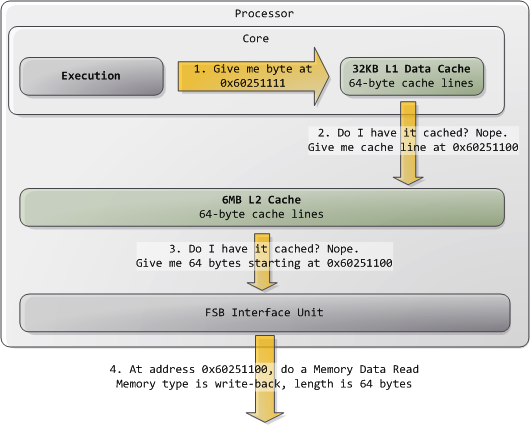
典型的情况是,内核把全部内存都视为"回写"类型(write-back),从而获得最好的性能。在回写模式下,内存的最小访问单元为一个缓存线(cache line),在Core 2中是64字节。当程序想读取内存中的一个字节时,处理器会从L1/L2 cache读取包含此字节的整条缓存线的内容。当程序做写入内存操作时,处理器只是修改cache中的对应缓存线,而不会更新主存中的信息。之后,当真的需要更新主存时,处理器会把那个被修改了的缓存线整体放到总线上,一次性写入内存。所以大部分的请求事务,其数据长度字段都是11(REQ[1:0]),对应64 字节。下图展示了当cache中没有对应数据时,内存读取访问的过程:
在Intel计算机上,有些物理内存范围被映射为设备地址而不是实际的RAM存储器地址,比如硬盘和网卡。这使得驱动程序可以像读写内存那样,方便的与设备通信。内核会在页表中标记出这类内存映射区域为不可缓存的(uncacheable)。对不可缓存的内存区域的访问操作会被总线原封不动的按顺序执行,其操作与应用程序或驱动程序所发出的请求完全一致。因此,这时程序可以精确控制读写单个字节、字、或其它长度的信息。这都是通过设置第二个数据包中的字节使能掩码(byte enable mask A[15:8])来完成的。
前面讨论的这些基本知识还包含很多关联的内容。比如:
1、 如果应用程序想要尽可能高的运行速度,就应该把会被一起访问的数据尽量组织在同一条缓存线中。一旦这条缓存线被载入,之后的读取操作就会加快很多,不再需要额外的内存访问了。
2、 对于回写式内存访问,作用于一条缓存线的任何内存操作都一定是原子的(atomic)。这种能力是由处理器的L1 cache提供的,所有数据被同时读写,中途不会被其他处理器或线程打断。特别的,32位和64位的内存操作,只要不跨越缓存线的边界,就都是原子操作。
3、 前端总线是被所有的agent所共享的。这些agent在开启一个事务之前,必须先进行总线使用权的仲裁。而且,每一个agent都需要侦听总线上所有的事务,以便维持cache的一致性。因此,随着部署更多的、多核的处理器到Intel计算机,总线竞争问题会变得越来越严重。为解决这个问题,Core i7将处理器直接连接于内存,并以点对点的方式通信,取代之前的广播方式,从而减少总线竞争。
本 文讲述的都是有关物理内存请求的重要内容。当涉及到内存锁定、多线程、缓存一致性的问题时,总线这个角色又将浮出水面。当我第一次看到前端总线数据包的描 述时,会有种恍然大悟的感觉,所以我希望您也能从本文中获益。下一篇文章,我们将从底层爬回到上层去,研究一个抽象概念:虚拟内存。
参考: http://blog.csdn.net/drshenlei/article/details/4243733
[转]: 主板芯片组与内存映射
原文标题:Motherboard Chipsets and the Memory Map
原文地址:http://duartes.org/gustavo/blog/
[注:本人水平有限,只好挑一些国外高手的精彩文章翻译一下。一来自己复习,二来与大家分享。]
我打算写一组讲述计算机内幕的文章,旨在揭示现代操作系统内核的工作原理。我希望这些文章能对电脑爱好者和程序员有所帮助,特别是对这类话题感兴趣但没有相关知识的人们。讨论的焦点是Linux,Windows,和Intel处理器。钻研系统内幕是我的一个爱好。我曾经编写过不少内核模式的代码,只是最近一段时间不再写了。这第一篇文章讲述了现代Intel主板的布局,CPU如何访问内存,以及系统的内存映射。
作为开始,让我们看看当今的Intel计算机是如何连接各个组件的吧。下图展示了主板上的主要组件:
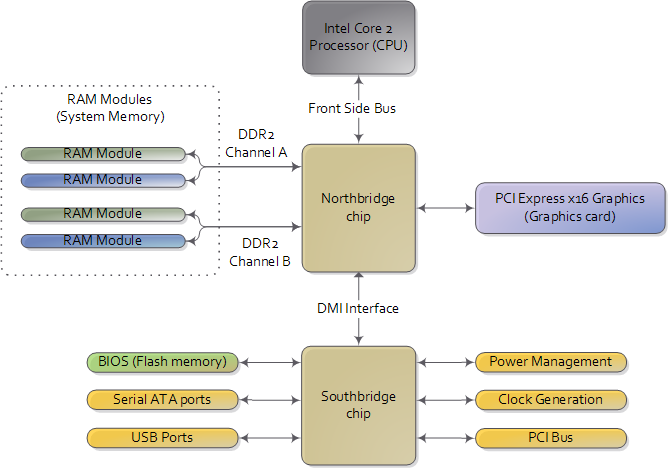
现代主板的示意图,北桥和南桥构成了芯片组。
当你看图时,请牢记一个至关重要的事实:CPU一点也不知道它连接了什么东西。CPU仅仅通过一组针脚与外界交互,它并不关心外界到底有什么。可能是一个电脑主板,但也可能是烤面包机,网络路由器,植入脑内的设备,或CPU测试工作台。CPU主要通过3种方式与外界交互:内存地址空间,I/O地址空间,还有中断。
{kind=link}
眼下,我们只关心主板和内存。安装在主板上的CPU与外界沟通的门户是前端总线(front-side bus),前端总线把CPU与北桥连接起来。每当CPU需要读写内存时,都会使用这条总线。CPU通过一部分管脚来传输想要读写的物理内存地址,同时另一些管脚用于发送将被写入或接收被读出的数据。一个Intel Core 2 QX6600有33个针脚用于传输物理内存地址(可以表示233个地址位置),64个针脚用于接收/发送数据(所以数据在64位通道中传输,也就是8字节的数据块)。这使得CPU可以控制64GB的物理内存(233个地址乘以8字节),尽管大多数的芯片组只能支持8GB的RAM。
现在到了最难理解的部分。我们可能曾经认为内存指的就是RAM,被各式各样的程序读写着。的确,大部分CPU发出的内存请求都被北桥转送给了RAM管理器,但并非全部如此。物理内存地址还可能被用于主板上各种设备间的通信,这种通信方式叫做内存映射I/O。这类设备包括显卡,大多数的PCI卡(比如扫描仪或SCSI卡),以及BIOS中的flash存储器等。
当北桥接收到一个物理内存访问请求时,它需要决定把这个请求转发到哪里:是发给RAM?抑或是显卡?具体发给谁是由内存地址映射表来决定的。映射表知道每一个物理内存地址区域所对应的设备。绝大部分的地址被映射到了RAM,其余地址由映射表来通知芯片组该由哪个设备来响应此地址的访问请求。这些被映射为设备的内存地址形成了一个经典的空洞,位于PC内存的640KB到1MB之间。当内存地址被保留用于显卡和PCI设备时,就会形成更大的空洞。这就是为什么32位的操作系统无法使用全部的4GB RAM。Linux中,/proc/iomem这个文件简明的列举了这些空洞的地址范围。下图展示了Intel PC低端4GB物理内存地址形成的一个典型的内存映射:
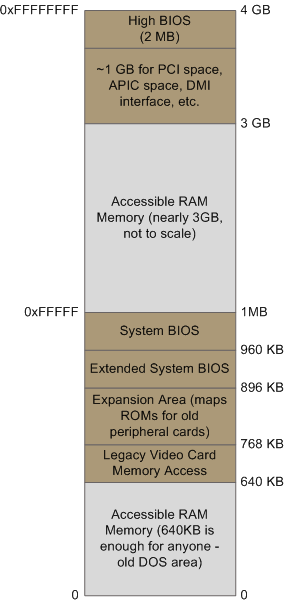
Intel系统中,低端4GB内存地址空间的布局。
实际的地址和范围依赖于特定的主板和电脑中接入的设备,但是对于大多数Core 2系统,情形都跟上图非常接近。所有棕色的区域都被设备地址映射走了。记住,这些在主板总线上使用的都是物理地址。在CPU内部(比如我们正在编写和运行的程序),使用的是逻辑地址,必须先由CPU翻译成物理地址以后,才能发布到总线上去访问内存。
这个把逻辑地址翻译成物理地址的规则比较复杂,而且还依赖于当时CPU的运行模式(实模式,32位保护模式,64位保护模式)。不管采用哪种翻译机制,CPU的运行模式决定了有多少物理内存可以被访问。比如,当CPU工作于32位保护模式时,它只可以寻址4GB物理地址空间(当然,也有个例外叫做物理地址扩展,但暂且忽略这个技术吧)。由于顶部的大约1GB物理地址被映射到了主板上的设备,CPU实际能够使用的也就只有大约3GB的RAM(有时甚至更少,我曾用过一台安装了Vista的电脑,它只有2.4GB可用)。如果CPU工作于实模式,那么它将只能寻址1MB的物理地址空间(这是早期的Intel处理器所支持的唯一模式)。如果CPU工作于64位保护模式,则可以寻址64GB的地址空间(虽然很少有芯片组支持这么大的RAM)。处于64位保护模式时,CPU就有可能访问到RAM空间中被主板上的设备映射走了的区域了(即访问空洞下的RAM)。要达到这种效果,就需要使用比系统中所装载的RAM地址区域更高的地址。这种技术叫做回收(reclaiming),而且还需要芯片组的配合。
这些关于内存的知识将为下一篇文章做好铺垫。下次我们会探讨机器的启动过程:从上电开始,直到boot loader准备跳转执行操作系统内核为止。如果你想更深入的学习这些东西,我强烈推荐Intel手册。虽然我列出的都是第一手资料,但Intel手册写得很好很准确。这是一些资料:
《Datasheet for Intel G35 Chipset》描述了一个支持Core 2处理器的有代表性的芯片组。这也是本文的主要信息来源。
《Datasheet for Intel Core 2 Quad-Core Q6000 Sequence》是一个处理器数据手册。它记载了处理器上每一个管脚的作用(当你把管脚按功能分组后,其实并不算多)。很棒的资料,虽然对有些位的描述比较含糊。
《Intel Software Developer's Manuals》是杰出的文档。它优美的解释了体系结构的各个部分,一点也不会让人感到含糊不清。第一卷和第三卷A部很值得一读(别被"卷"字吓倒,每卷都不长,而且您可以选择性的阅读)。
Pádraig Brady建议我链接到Ulrich Drepper的一篇关于内存的优秀文章。确实是个好东西。我本打算把这个链接放到讨论存储器的文章中的,但此处列出的越多越好啦。
参考: http://blog.csdn.net/drshenlei/article/details/4246441
转: 计算机的引导过程
原文标题:How Computers Boot Up
原文地址:http://duartes.org/gustavo/blog/
[注:本人水平有限,只好挑一些国外高手的精彩文章翻译一下。一来自己复习,二来与大家分享。]
前一篇文章介绍了Intel计算机的主板与内存映射,从而为本文设定了一个系统引导阶段的场景。引导(Booting)是一个复杂的,充满技巧的,涉及多个阶段,又十分有趣的过程。下图列出了此过程的概要:
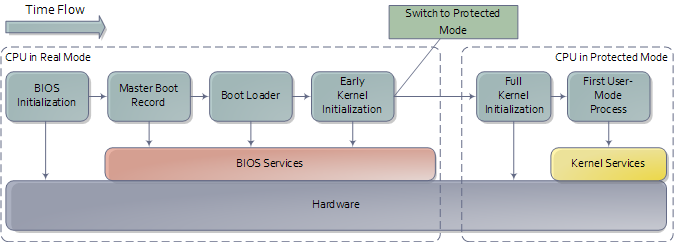
引导过程概要
当 你按下计算机的电源键后(现在别按!),机器就开始运转了。一旦主板上电,它就会初始化自身的固件(firmware)——芯片组和其他零零碎碎的东西 ——并尝试启动CPU。如果此时出了什么问题(比如CPU坏了或根本没装),那么很可能出现的情况是电脑没有任何动静,除了风扇在转。一些主板会在CPU 故障或缺失时发出鸣音提示,但以我的经验,此时大多数机器都会处于僵死状态。一些USB或其他设备也可能导致机器启动时僵死。对于那些以前工作正常,突然 出现这种症状的电脑,一个可能的解决办法是拔除所有不必要的设备。你也可以一次只断开一个设备,从而发现哪个是罪魁祸首。
如果一切正常,CPU就开始运行了。在一个多处理器或多核处理器的系统中,会有一个CPU被动态的指派为引导处理器(bootstrap processor简写BSP),用于执行全部的BIOS和内核初始化代码。其余的处理器,此时被称为应用处理器(application processor简写AP),一直保持停机状态直到内核明确激活他们为止。虽然Intel CPU经历了很多年的发展,但他们一直保持着完全的向后兼容性,所以现代的CPU可以表现得跟原先1978年的Intel 8086完全一样。其实,当CPU上电后,它就是这么做的。在这个基本的上电过程中,处理器工作于实模式,分页功能是无效的。此时的系统环境,就像古老的MS-DOS一样,只有1MB内存可以寻址,任何代码都可以读写任何地址的内存,这里没有保护或特权级的概念。
CPU上电后,大部分寄存器的都具有定义良好的初始值,包括指令指针寄存器(EIP),它记录了下一条即将被CPU执行的指令所在的内存地址。尽管此时的Intel CPU还只能寻址1MB的内存,但凭借一个奇特的技巧,一个隐藏的基地址(其实就是个偏移量)会与EIP相加,其结果指向第一条将被执行的指令所处的地址0xFFFFFFF0(长16字节,在4GB内存空间的尾部,远高于1MB)。这个特殊的地址叫做复位向量(reset vector),而且是现代Intel CPU的标准。
主板保证在复位向量处的指令是一个跳转,而且是跳转到BIOS执行入口点所在的内存映射地址。这个跳转会顺带清除那个隐藏的、上电时的基地址。感谢芯片组提供的内存映射功能,此时的内存地址存放着CPU初始化所需的真正内容。这些内容全部是从包含有BIOS的闪存映射过来的,而此时的RAM模块还只有随机的垃圾数据。下面的图例列出了相关的内存区域:
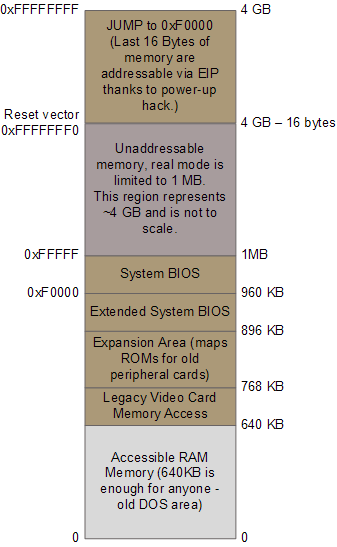
引导时的重要内存区域
随后,CPU开始执行BIOS的代码,初始化机器中的一些硬件。之后BIOS开始执行上电自检过程(POST),检测计算机中的各种组件。如果找不到一个可用的显卡,POST就会失败,导致BIOS进入停机状态并发出鸣音提示(因为此时无法在屏幕上输出提示信息)。如果显卡正常,那么电脑看起来就真的运转起来了:显示一个制造商定制的商标,开始内存自检,天使们大声的吹响号角。另有一些POST失败的情况,比如缺少键盘,会导致停机,屏幕上显示出错信息。其实POST即是检测又是初始化,还要枚举出所有PCI设备的资源——中断,内存范围,I/O端口。现代的