堆排序,时间复杂度是O(nlogn),原地排序
重点是堆(最大堆,最小堆)这种数据结构。一个堆在逻辑上是一颗完全二叉树样的东东,最大堆的特点是父结点的值比两个子结点的值要大,此外没有其它特点了,最小堆的定义类似。
这章讲了用最大堆来排序,然后讲了用堆来实现优先队列。由于实现堆的时间犯了点小错误,调试了大半个小时,因此优先队列的代码还没来得及实现呢,明天补上吧。
下面是堆排序的内容。
这里是用数组来实现堆的,关于再者的关系,我觉得下面这个图应该表达得很清楚。当然了,下面的代码数组的下标是从0开始的。
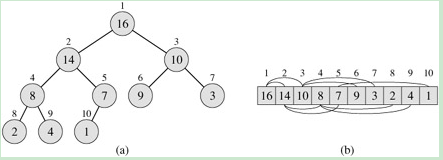
整个堆排序的算法,核心在于maxHeapity(int i) 这个函数,它的作用是保持下标为i的结点和它的两个子结点之间的最大堆的性质(即结点i的值要比它的两个子结点的值要大)。
堆排序的算法思想是:
- 给定一个待排序的数组,在它上面建一个最大堆。
- 这时,根结点的值一定是最大的,因此,把它与数组的最后一个元素交换。交换之后,数组的最大值就存在于最后一个位置了。
- 但是对于根结点与它的两个子结点,它们之间可能违背了最大堆的性质,因此,需要调用一次maxHeapity(int 0),以保持最大堆的性质。
- 在此之后,当前的根结点的值又是当前的最大值(除了刚才的最大值之外的)。因此,将它与数组的倒数第二个元素进行交换,并重复第3步。
- 这样一直循环,直到数组中第二小的元素处于第二个位置上为止。此时最小的元素一定在第一个位置上
Java code: