C#之int挑战Java之Integer
注:
此文是我为本人拙著《.NET 4.0面向对象编程漫谈》所新写的扩充阅读材料。
本文涉及到一些JVM原理和Java的字节码指令,推荐感兴趣的读者阅读一本有关JVM的经典书籍《深入Java虚拟机(第2版)》,将它与我在《.NET 4.0面向对象编程漫谈》中介绍的CLR原理与IL汇编指令作个对比,相信读者会有一定的启发。而仔细对比两个类似事物的异同,是很有效的学习方法之一。
今后我还将在个人博客上放出其他的文章,希望能帮助书的读者开拓视野,启发思考,大家一起探讨技术的奥秘。
本文所述之内容仅代表个人之理解,任何疏漏及错误请直接回贴指出。
===============================================================================
1 奇特的程序输出
前段时间,一个学生给我看了一段“非常诡异”的Java代码:
public class TestInteger {
public static void main(String[] args){
Integer v1=100;
Integer v2=100;
System.out.println(v1==v2); //输出:true
Integer w1=200;
Integer w2=200;
System.out.println(w1==w2); //输出:false
}
}
让这个学生最困惑的是,为什么这些如此相似的代码会有这样令人意外的输出?
我平时多使用C#,Java用得不多,初看到这段代码的输出,我也同样非常奇怪:怎么会这样呢?100和200这两个整型数值对Integer这个类有本质上的差别吗?
为了弄明白出现上述现象的底层原因,我使用javap工具反汇编了Java编译器生成的.class文件:
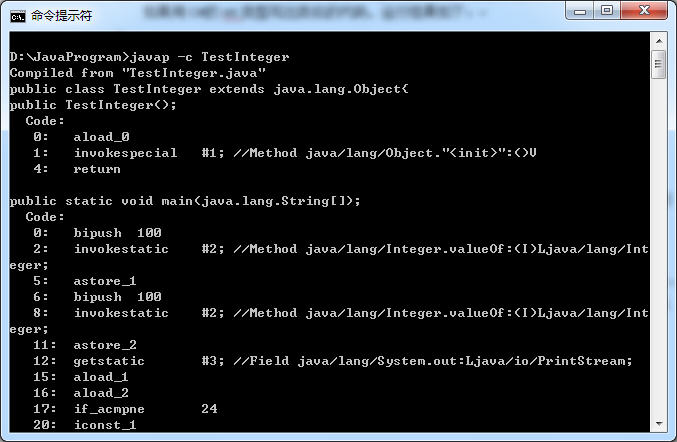
通过仔细阅读Java编译器生的字节码,我发现以下给Integer变量赋值的语句:
Integer v1=100;
实际上调用的是Integer.valueOf方法。
而完成两个Integer变量比较的以下语句:
System.Console.WriteLine(v1 == v2);
实际生成的是if_acmpne指令。其中的a代表“address”,cmp代表“Compare”,ne代表“not equal”。
这条指令的含义是:比较Java方法栈中的两个操作数(即v1与v2),看看它们是不是指向堆中的同一个对象。
当给v1和v2赋值100时,它们将引用同一个Integer对象。
那为什么当值改为200时,v1和v2就“翻脸了”,分别引用不同的Integer对象?
秘密就在于Integer.valueOf方法。幸运的是,Java的类库是开源的,所以我们可以毫不费力地看到相关的源代码:
public static Integer valueOf(int i) {
if(i >= -128 && i <= IntegerCache.high)
return IntegerCache.cache[i + 128];
else
return new Integer(i);
}
一切真相大白,原来Integer在内部使用了一个私有的静态类IntegerCache,此类内部封装了一个Integer对象的cache数组来缓存Integer对象,其代码如下:
private static class IntegerCache {
static final Integer cache[];
//……
}
再仔细看看IntegerCache内部的代码,会看到它使用静态初始化块在cache数组中保存了[-128,127]区间内的一共256个Integer对象。
当给Integer变量直接赋整数值时,如果这个数值位于[-128,127]内,JVM(Java Virtual Machine)就直接使用cache中缓存的Integer对象,否则,JVM会重新创建一个Integer对象。
一切真相大白。
2 进一步探索Integer
我们再进一步地看看这个有趣的Integer:
Integer v1=500;
Integer v2=300;
Integer addResult=v1+v2; //结果:800
double divResult=(double)v1/v2; //结果:1.6666666666666667
哟,居然Integer对象支持加减乘除运算耶!它是怎么做到的?
再次使用javap反汇编.class文件,不难发现:
Integer类的内部有一个私有int类型的字段value,它代表了Integer对象所“封装”的整数值。
private final int value;
当需要执行v1+v2时,JVM会调用v1和v2两个Integer对象的intValue方法取出其内部所封装的整数值value,然后调用JVM直接支持的iadd指令将这两个整数直接相加,结果送回方法栈中,然后调用Integer.valueOf方法转换为Integer对象,让addResult变量引用这一对象。
除法则复杂一点,JVM先调用i2d指令将int转换为double,然后再调用ddiv指令完成浮点数相除的工作。
通过上述分析,我们可以知道,其实Integer类本身并不支持加减乘除,而是由Java编译器将这些加减乘除的语句转换为JVM可以直接执行的字节码指令(比如本例中用到的iadd和ddiv),其中会添加许多条用于类型转换的语句。
由此可见,与原始数据类型int相比,使用Integer对象直接进行加减乘除会带来较低的运行性能,应避免使用。
3 JDK中Integer类的“弯弯绕”设计方案
现在,我们站在一个更高的角度,探讨一下Integer的设计。
我个人认为,给Integer类型添加一个“对象缓冲”不是一个好的设计,从最前面的示例代码大家一定会感到这一设计给应用层的代码带来了一定的混乱。另外,我们看到JDK设计者只缓存了[-128,127]共256个Integer对象,他可能认为这个区间内的整数是最常用的,所以应该缓存以提升性能。就我来看,这未免有点过于“自以为是”了,说这个区间内的Integer对象用得最多有什么依据?对于那些经常处理>128的整数值的应用程序而言,这个缓存一点用处也没有,是个累赘。就算真要缓存,那也最好由应用程序开发者自己来实现,因为他可以依据自己开发的实际情况缓存真正用到的对象,而不需背着这个包容着256个Integer对象的大包袱。
而且前面也看到了,基于Integer对象的加减乘除会增加许多不必要的类型转换指令,远不如直接使用原始数据类型更快