[本文内容主要摘自网上资料,本来想自己写的,可是看着有的资料已经写的很好了,就整理转载了过来,再此,谢过原作者了:》]
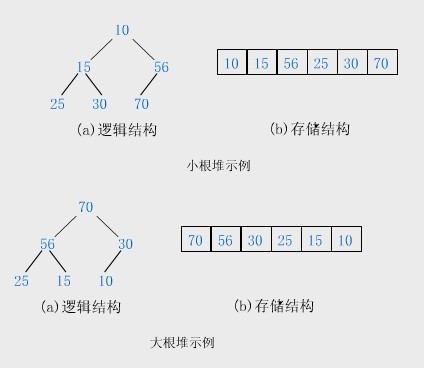
堆排序: 是一种选择排序,但它的效率比直接选择排序要高,因为,可以借助于树形结构来减少比较次数。
定义:
n个关键字序列Kl,K2,…,Kn称为堆,当且仅当该序列满足如下性质(简称为堆性质):
(1) ki≤K2i且ki≤K2i+1 或 (2)Ki≥K2i且ki≥K2i+1(1≤i≤
![]() )
)
(注意: i从1开始,而不是从0开始)
若将此序列所存储的向量R[1..n]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
算法思想:
利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单。
1)将初始待排关键字序列(R1,....Rn)构建成大顶堆,此堆为初始的无序区;
2)将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,....Rn-1) 和新的有序区 Rn, 并且满足R[1,2...n-1]<=R[n];
3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
示例演示:
给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。
首先根据该数组元素构建一个完全二叉树,得到
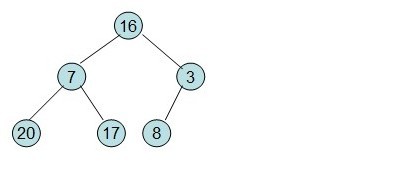
然后需要构造初始堆,则从最后一个非叶节点开始调整,调整过程如下:

20和16交换后导致16不满足堆的性质,因此需重新调整

这样就得到了初始堆。
在完全二叉树中,所有序号![]() 的结点都是叶子,因此以这些结点为根的子树均已是堆。这样,我们只需依次将以序号为
的结点都是叶子,因此以这些结点为根的子树均已是堆。这样,我们只需依次将以序号为![]()
, ![]() -1,…,1的结点作为根的子树都调整为堆即可。
-1,…,1的结点作为根的子树都调整为堆即可。
每次调整都是从父节点、左孩子节点、右孩子节点三者中选择最大者跟父节点进行交换(交换之后可能造成被交换的孩子节点不满足堆的性质,因此每次交换之后要重新对被交换的孩子节点进行调整)。
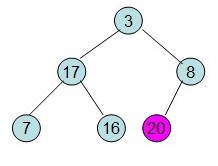
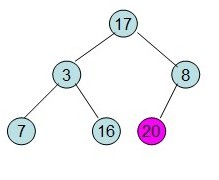
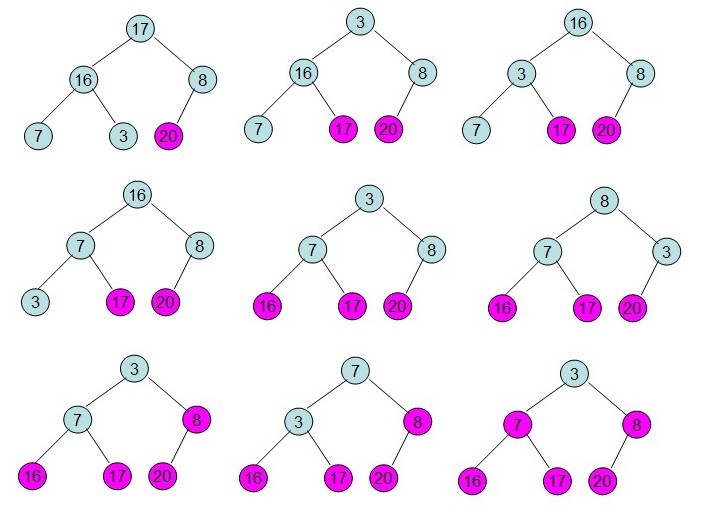
这样整个区间便已经有序了。
算法分析:
堆排序的时间,主要由建立初始堆和反复重建堆这两部分的时间开销构成。
堆排序的最坏时间复杂度为O(nlgn)。堆排序的平均性能较接近于最坏性能。
由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。
堆排序是就地排序,辅助空间为O(1),
它是不稳定的排序方法。
程序代码:
void HeapSort(int *a ,int size)
{
BuildHeap(a,size); //构造大顶堆
int t;
// 有序区为 i+1....size 无序区为 1...i
for (int i=size;i>1;i--)
{
//交换堆顶和最后一个元素,即每次将剩余元素中的最大者放到最后面
t=a[i];
a[i]=a[1];
a[1]=t;
HeapAdjust(a,1,i-1); //重新调整堆顶节点成为大顶堆
}
}
void BuildHeap(int *a,int size)
{
for (int i=size/2;i>=1;i--) // 非叶节点最大序号值为size/2
{
HeapAdjust(a,i,size);
}
}
void HeapAdjust(int *a, int i,int size)
{
int lChild=2*i;
int rChild=2*i+1;
int iMax=i;
if (i<=size/2) //如果i是叶节点就不用进行调整
{
if (lChild<=size&&a[lChild]>a[iMax])
{
iMax=lChild;
}
if (rChild<=size&&a[rChild]>a[iMax])
{
iMax=rChild;
}
//iMax为最大值所在的节点编号
if (iMax!=i)
{
int t=a[iMax];
a[iMax]=a[i];
a[i]=t;
HeapAdjust(a,iMax,size); //避免调整之后以iMax为父节点的子树不是堆
}
}
}
使用:
int b[5]={4,1,3,2,5};
HeapSort(b-1,5); // b-1, 确保序列是从索引1开始
参考资料:
http://www.cnblogs.com/dolphin0520/archive/2011/10/06/2199741.html