统计自然语言处理--数学基础
李亚超
2010-10-28
1简介
这一部分介绍统计自然语言处理的数学基础,主要内容包括概率论和数理统计。要把所有要点详细的介绍完,很难。在这里,我只是把以后在自然语言处理中会用得到比较重要的数学知识做个介绍。单纯的数学公式是很枯燥的,比如在上中学时学的余弦定理,那时候就是一个单纯的数学公式,但是现在自然语言处理上,比如新闻分类,那就生动多了。多以在这里我想说的是数学是百科之母。
2概率基础
2.1 基础概率简介
概率论是统计自然语言处理的理论基础,有些知识我们在中学或者是大学已经学过了,在这里就不在做过多的赘述。比如,概率空间(
Probability spaces
)、条件概率和独立性(Conditional probability and independence)、随机变量、期望和方差。
在这里我只是介绍一下条件概率,因为这个概率模型以后会很多次提到,并且用途也很广。比如最大熵问题,HMM模型,语言模型中求字符串的概率。用的比较多的是多参数的链式法则。
在机器翻译中这个模型是语言模型。
例如,S表示特定排列的词串w1,w2,w3,w4,w5...wn。如果要求出S在文中出现的概率,即用P(S)表示S的概率,利用条件概率这个S的概率等于S中各个词的概率乘积,于是P(S)可以展开为:
P(S)=P(w1*w2*w3...wn)=P(w1)P(w2|w1)P(w3|w1w2)...P(wn|w1w2w3...wn-1)
其中P(w1)表示词w1在文中出现的频率,P(w2|w1)表示已知第一个词的前提下,第二个词出现的频率,以后的一次类推。
在实际应用中,如果词串太长后面的计算量太大,用
N
元语法模型或者是
马尔可夫假设
,即任意一个词
wi
出现的概率只有前一个
wi-1
词决定
,
这样前面的公式就变得简单多了,
P(S)=P(w1)P(w2|w1)P(w3|w2)...P(wn|wn-1)
,这里用的是二元语法模型,也可以用三元,四元模型,不过随着数量的增加计算的复杂度也相应的增加。
接下来的问题是,如果计算
P(wi|wi-1)
,
只要数一数这对词(
wi-1,wi)
在统计的文本中出现了多少次,以及
wi-1
本身在同样的文本中前后相邻出现了多少次
,然后用两个数一除就可以了
,P(wi|wi-1) = P(wi-1,wi)/ P (wi-1)
。
也许人们不相信,就是这个简单的数学公式,可以解决复杂的语音识别、机器翻译、中文分词消歧问题。
李开复用统计语言模型把
997
词语音识别的问题简化成了一个
20
词的识别问题,实现了有史以来第一次大词汇量非特定人连续语音的识别。
Google
的中英文自动翻译也是主要基于这个统计语言模型。
2.2
贝叶斯定理
(Bayes’theorem)
简单地说
Bayes
是个逆概率问题,
比如,我们要可以把求P(A/B)
,的问题转换为求
P(B/A)
的问题。
当正向概率很复杂时,这个公式就显示出他的作用,以后我们会经常用到的。他由条件概率的定义引出。
Bayes定理:P(B|A)=P(AB)/P(A) = P(A|B)P(B)/P(A)
这样在给定A的条件下,求P(B|A),我们可以忽略A的只,因为他在所有的情况下都是常数。
所以,argmax(P(A|B)P(B)/P(A)) = argmax(P(A|B)P(B)),这个公式在机器翻译中用的很广泛,比如用在
翻译模型
。
除了这些,Bayes公式在自然语言处理中用的很广泛,以后会经常用到。
Bayes统计
2.2.1 Bayes更新
Bayes统计是用来测量信任度,可以通过计算以前的数据,在遇到新的证据时,通过Bayes定理重新更新以前的数据。
2.2.2 Bayes决策理论
Bayes决策理论是Bayes定理的一个应用,Bayes本身就是求逆概率问题,所以可以通过事后数据来决定那个模型更好地符合实际。
2.3 Bayes
贝叶斯网络
我们在以前提到马尔科夫链(MarkovChain),它描述了这样的一个
状态
序列,每个状态值取决于其前面的有限的状态。
这种模型,对很多实际问题来讲是一种很粗略的简化。在现实生活中,很多事物相互的关系并不能用一条链来串起来。它们之间的关系可能是交叉的、错综复杂的。
不能用一条链来描述。
如下图:
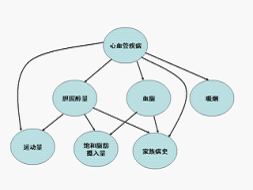
我们可以把上述的
有向图看成一个网络,
它就是贝叶斯网络。其中每个圆圈表示一个状态。状态之间的连线表示它们的因果关系。比如从心血管疾病出发到吸烟的弧线表示心血管疾病可能和吸烟有关。当然,这些关系可以有一个量化的可信度(belief),用一个概率描述。我们可以通过这样一张网络估计出一个人的心血管疾病的可能性。在网络中每个节点概率的计算,可以用贝叶斯公式来进行,贝叶斯网络因此而得名。由于网络的每个弧有一个可信度,贝叶斯网络也被称作信念网络(belief networks)。
和马尔可夫链类似,贝叶斯网络中的每个状态值取决于前面有限个状态。不同的是,贝叶斯网络比马尔可夫链灵活,它不受马尔可夫链的链状结构的约束,因此可以更准确地描述事件之间的相关性。可以讲,马尔可夫链是贝叶斯网络的特例,而贝叶斯网络是马尔可夫链的推广。
使用贝叶斯网络必须知道各个状态之间相关的概率。得到这些参数的过程叫做训练。和训练马尔可夫模型一样,训练贝叶斯网络要用一些已知的数据。比如在训练上面的网络,需要知道一些心血管疾病和吸烟、家族病史等有关的情况。
贝叶斯网络在图像处理、文字处理、支持决策等方面有很多应用。在文字处理方面,语义相近的词之间的关系可以用一个贝叶斯网络来描述。我们利用贝叶斯网络,可以找出近义词和相关的词,在Google 搜索和Google 广告中都有直接的应用。
对于机器翻译可以应用在找出同义词或歧义消除。