1.webkit中每个html页面对应于一颗dom树 和render树,dom用于描述html页面的的信息,而render树则用于布局,具体负责dom树如何显示在屏幕上,从MVC的角度来说,可以将render树看成是V,dom树看成是M,C则是具体的调度者,比HTMLDocumentParser等。webkit将这两部分分开,可以看出其设计意图,同一个dom,可以对应不同的render,或者不同的xml文档,对应于相同的render,显示出其极大的灵活性。
2. webkit的整个解析过程,大致是这样,从网络返回数据后,将数据交给HTMLDocumentParser,然后HTMLDocumentParser将文本字符的解析交给HTMLDocumentTokenizer来负责,HTMLDocumentTokenizer解析出一个一个的标签(html文档时是以标签为单位),HTMLDocumentParser将标签交给,HTMLTreeBuilder来构建dom树,所以正如1所提到,这里的HTMLDocumentParser从MVC的角度来看,其作用和地位应该是C,这样,MVC各兼其责,最终生成一颗render树,将其显示在屏幕上。
3. 通过1,2 的叙述,大家应该明白了dom树的生成时机,那么render树是何时生成的呢?通过源码发现,其实在每生成一个dom节点,就会去创建对应的render节点,也就是说,dom树和render树是同时生成的,小弟确实不是很明白这一点,为什么一定要在这个时候生成render树,如果将dom生成完毕后,再生成render树,是否能够体现出更大的灵活性?
废话不多说,下面将以上叙述,通过类图和时序图来表达.
类图document与parser之间的类图如下

类图描述:
a. 从上面的类图可以看出,webkit所表现出的极大的灵活性,对于HTML文档,是生成HTMLDocumentParser,对于其他的XML文档,则可以自行设计对应的Parser,对于上层是需要拿到一个DocumentParser即可
b. HTMLParserScheduler中的职责是实现异步解析,具体可以参照前面的文章webkit中timer的应用
c. HTMLScriptRunner主要是用来运行脚本
parser的时序图:
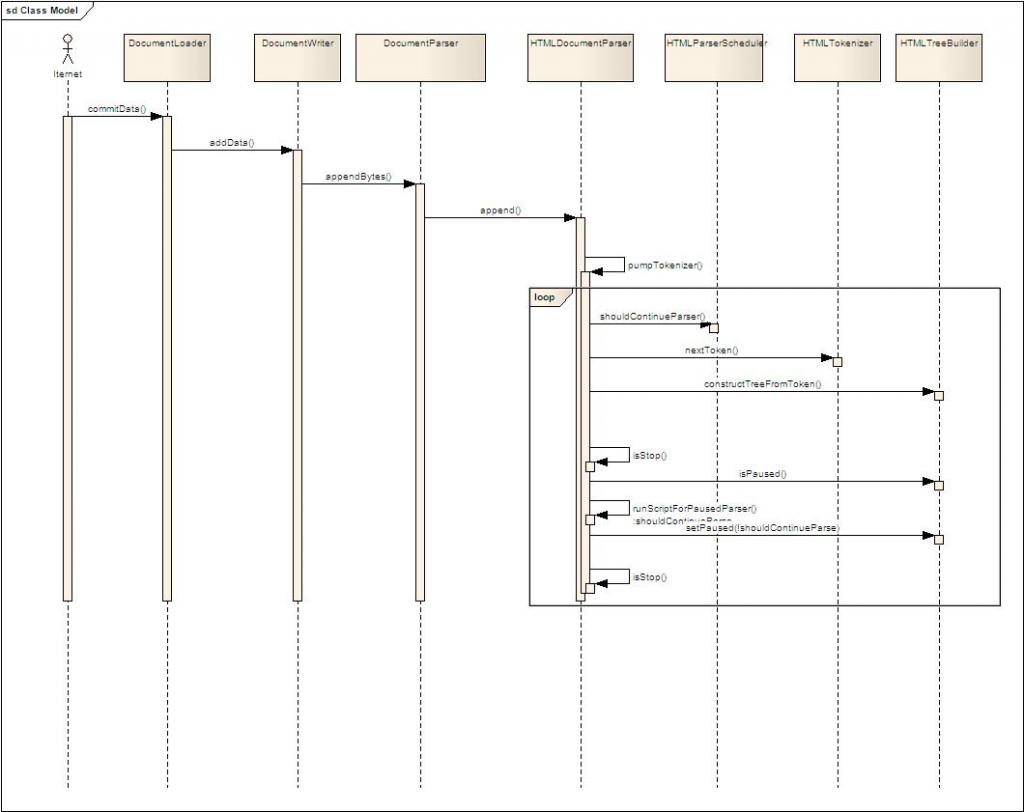
时序图描述:
a. 网络请求的数据并不是一步到位传给DocumentLoader,传给DocumentLoader经过了很多层次,为了画图的方便,我这个地方做了简化
b. 在解析数据的时候,webkit引入了一个中间层,DocumentWriter
构建具体的dom节点时序图如下:
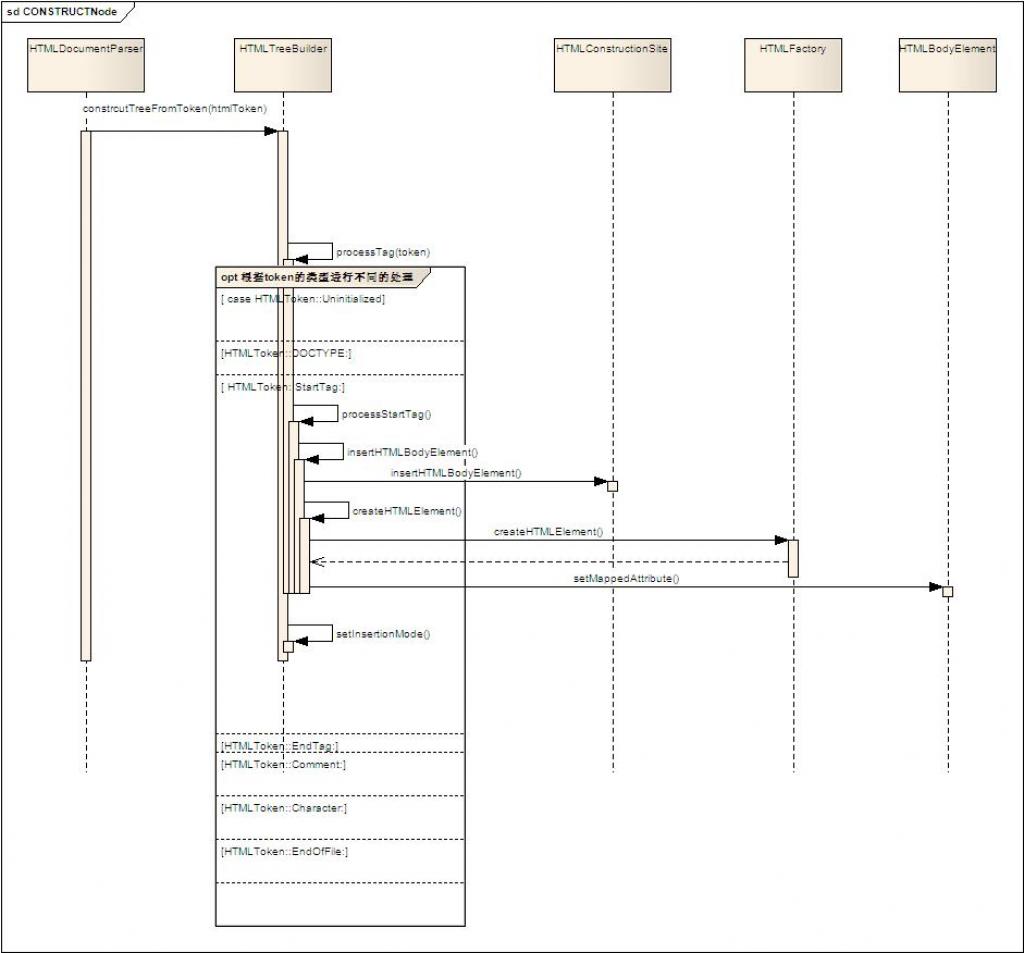
构造dom节点时序图描述:
a. 以上是以构建body节点为例来说明构建节点的流程
b. 在HTMLTreeBuilder的processTag中,是根据不同的标签类型进行处理,上面的时序图仅仅体现出类型,下面将源码贴上:
- void HTMLTreeBuilder::processToken(AtomicHTMLToken& token)
- {
- switch (token.type()) {
- case HTMLToken::Uninitialized:
- ASSERT_NOT_REACHED();
- break;
- case HTMLToken::DOCTYPE:
- processDoctypeToken(token);
- break;
- case HTMLToken::StartTag:
- processStartTag(token);
- break;
- case HTMLToken::EndTag:
- processEndTag(token);
- break;
- case HTMLToken::Comment:
- processComment(token);
- return;
- case HTMLToken::Character:
- processCharacter(token);
- break;
- case HTMLToken::EndOfFile:
- processEndOfFile(token);
- break;
- }
- }
c. setInsertionMode: 主要是为了记录解析的状态,所有状态由下面的枚举来定义
- enum InsertionMode {
- InitialMode,
- BeforeHTMLMode,
- BeforeHeadMode,
- InHeadMode,
- InHeadNoscriptMode,
- AfterHeadMode,
- InBodyMode,
- TextMode,
- InTableMode,
- InTableTextMode,
- InCaptionMode,
- InColumnGroupMode,
- InTableBodyMode,
- InRowMode,
- InCellMode,
- InSelectMode,
- InSelectInTableMode,
- InForeignContentMode,
- AfterBodyMode,
- InFramesetMode,
- AfterFramesetMode,
- AfterAfterBodyMode,
- AfterAfterFramesetMode,
- };
以上是dom节点生成的时序图,我们知道,最后是要构建一颗dom树,和render树,所以,下面的步骤,是将dom节点attach到一个树上,时序图见下:
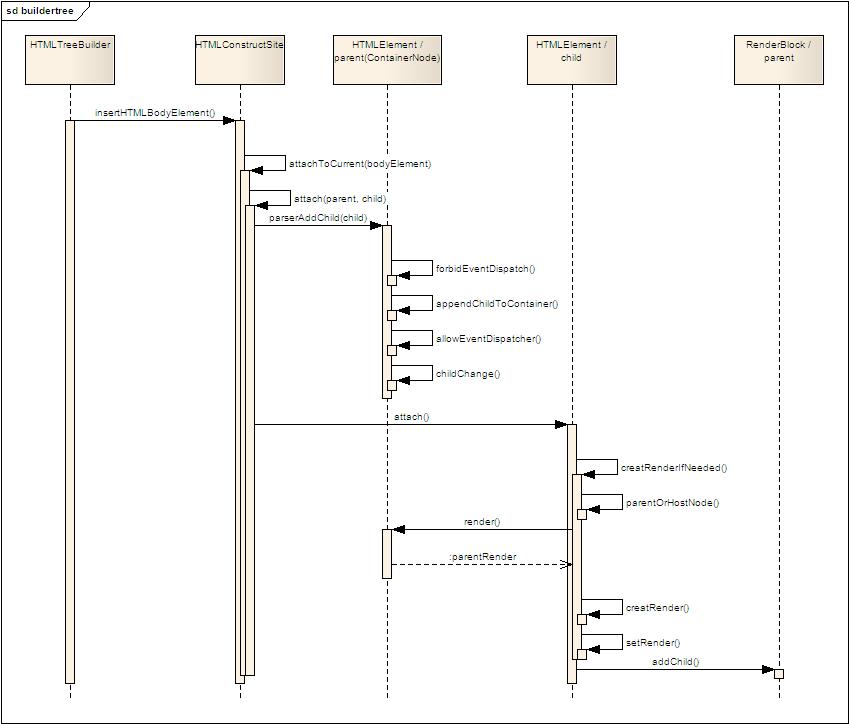
以上就是构建dom树和render树的过程