一。安装mysql for Hive metadata
$ sudo apt-get install mysql-server
$ mysql -u root -ppassword
$ vi /etc/mysql/my.cnf
port=3306
socket=/var/run/mysqld/mysqld.sock
...
二. Hive的配置
hive-site.xml的编辑:
<configuration> <property> <name>hive.metastore.local</name> <value>true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive01?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>password</value> </property> </configuration>
三。 Hadoop的配置
Hadoop的配置采用伪分布式方式(新版的希望采用分为core,hdfs,mapred三个配置文件的方式,我还是用的单个:hadoop-site.xml):
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/allen/data</value> <description>A base for other temporary directories.</description> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
尝试start-all.sh
localhost: ssh: connect to host localhost port 22: Connection refused
$ sudo apt-get install ssh
搞定
搞定Hive(mysql)+Hadoop!
-----------------------------------------------------下面就是eclipse了---------------------------------------------
四。Eclipse中运行Hive
上来就报找不到java。。。
在eclipse文件夹下新建一个jre/bin/
ln -s $JAVA_HOME/bin/java过来
就好了
new peoject,location:/home/allen/Desktop/hive0.7.1
从$HADOOP_HOME/拷贝core,test,tools,servlet,jetty等jar到hive0.7.1/lib下,添加进build path。
在build path中删除一些src/jdbc/src/java/...等等不是一级的src path。。。
将conf文件夹加到classpath:
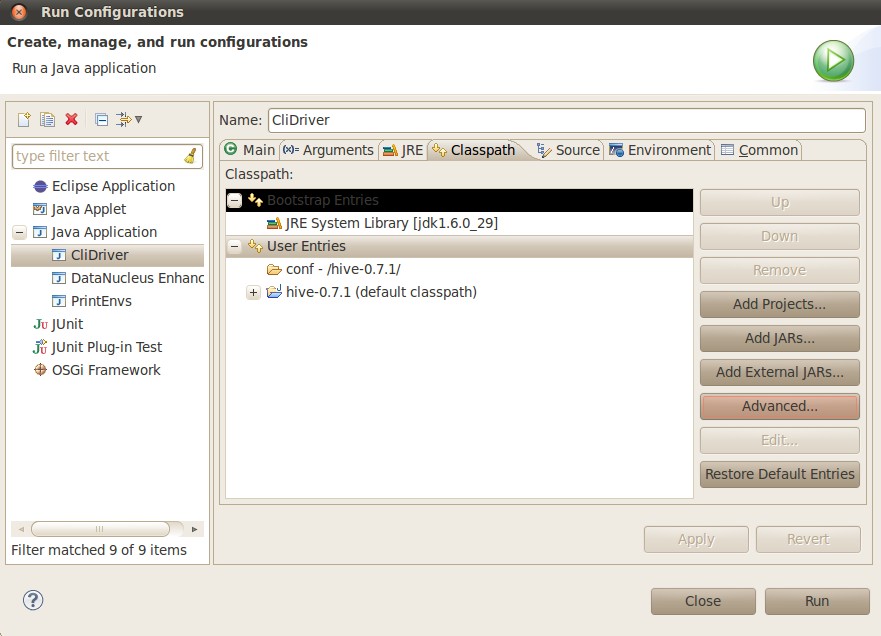
run CliDriver
Hive history file=/tmp/allen/hive_job_log_allen_201203041606_843912565.txt hive> show tables; show tables; FAILED: Error in metadata: org.datanucleus.jdo.exceptions.ClassNotPersistenceCapableException: The class "org.apache.hadoop.hive.metastore.model.MDatabase" is not persistable. This means that it either hasnt been enhanced, or that the enhanced version of the file is not in the CLASSPATH (or is hidden by an unenhanced version), or the Meta-Data/annotations for the class are not found. NestedThrowables: org.datanucleus.exceptions.ClassNotPersistableException: The class "org.apache.hadoop.hive.metastore.model.MDatabase" is not persistable. This means that it either hasnt been enhanced, or that the enhanced version of the file is not in the CLASSPATH (or is hidden by an unenhanced version), or the Meta-Data/annotations for the class are not found. FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask hive>
需要安装DataNucleus for Eclipse 插件,见http://guoyunsky.iteye.com/blog/1178076
1)通过Eclipse安装datanucleus
Help->Install New Software->Work with输入框里输入网址http://www.datanucleus.org/downloads/eclipse-update/
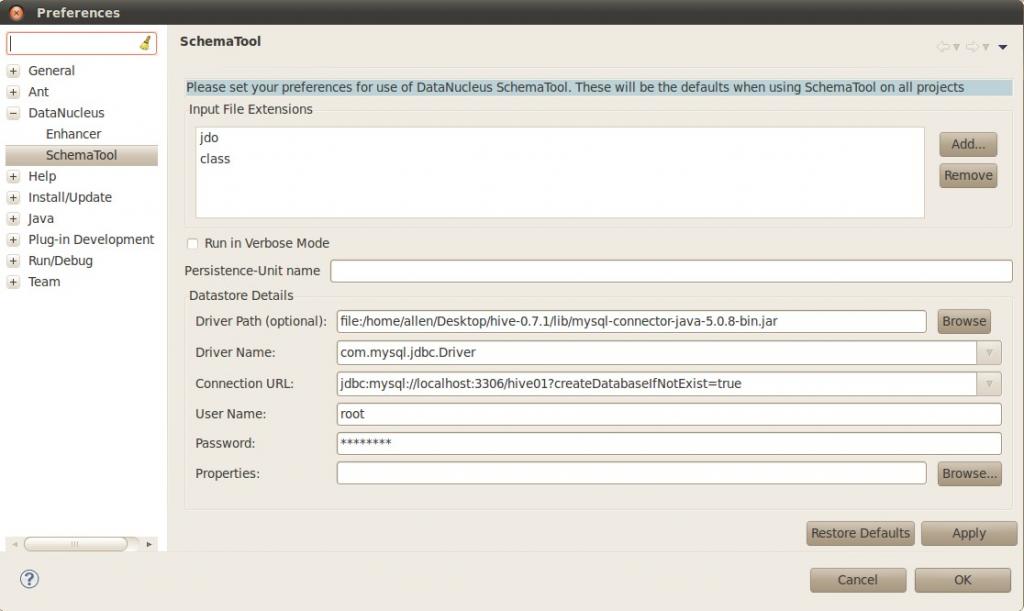
2)设置datanucleus
Window->Preferences->DataNucleus->SchemaTool->
根据你在hive-default.xml里的配置进行设置Drive Path、Driver Name、Connection URL:
3)在你到工程上部署datanucleus,也就是hive源码:
右击Hive源码工程->DataNucleus->Add DataNucleus Support->
之后再看Hive源码工程的Dataucleus会多几项,Enable Auto-Enhancement
再次运行CliDriver,OK!:
Hive history file=/tmp/allen/hive_job_log_allen_201203041630_1488547381.txt hive> show tables; show tables; OK Time taken: 3.312 seconds hive>
Debug CliDriver
hive> select * from table02 where id =500000; select * from table02 where id =500000; Total MapReduce jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator java.io.IOException: Cannot run program "null/bin/hadoop" (in directory "/home/allen/Desktop/hive-0.7.1"): java.io.IOException: error=2, No such file or directory at java.lang.ProcessBuilder.start(ProcessBuilder.java:460) at java.lang.Runtime.exec(Runtime.java:593) at java.lang.Runtime.exec(Runtime.java:431) at org.apache.hadoop.hive.ql.exec.MapRedTask.execute(MapRedTask.java:246) at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:130) at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:57) at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:1066) at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:900) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:748) at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:165) at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:242) at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:457) Caused by: java.io.IOException: java.io.IOException: error=2, No such file or directory at java.lang.UNIXProcess.<init>(UNIXProcess.java:148) at java.lang.ProcessImpl.start(ProcessImpl.java:65) at java.lang.ProcessBuilder.start(ProcessBuilder.java:453) ... 11 more
看打印猜应该跟程序读不到$HADOOP_HOME有关,通过往eclipse配置环境中set变量解决:
