awk三种使用方式:
1. awk [-F field-separator] ‘command’ file1 file2 …。field-separator必须用引号或双引号扩上。
2. 将awk指令写入脚本中,并且指定执行该脚本的解析器为“#!/usr/bin/awk -f”,awk路径不同系统可能不一样。运行该脚本:test.awk file1 file2 …。
3. 将awk指令写入脚本中,执行awk –f scripfile file1 file2 …。
awk每次在文件中读一行,找到域分隔符(若未制定-F,则默认为空格),设置其为域n(从1开始,$1,$2…$n,$0代表原文件中的行),直至一新行,然后,划分这一行作为一条记录,接着 awk再次启动下一行读进程。
awk语句语法规则和其它脚本(如js,但是没有其类的功能,而且数组下标从1开始)语言非常类似。另外,可以给命令添加信息头或信息尾,或两者都加,两者中不一定就只是为了输出,可以设置一些值等,它们就是普通语句,只不过执行的位置特殊点。在信息头中可以声明一些变量,从而可以在接下来的执行语句中使用。
注意:
- {print $1,$2}会在第一个数据域和第二个数据域中添加OFS(输出域分隔符,awk内置变量会有介绍)。
- 如果忘了添加文件,那么会默认以标准输入作为内容来源,ctrl+D代表输入内容结束。
- 为了防止语法错误,应该保证:
- command用单引号括起来。
- 命令内所有引号成对出现。
- 确保用花括号括起全部动作,用圆括号括起全部条件语句。
条件语句
如果要使用正则,用/regex/形式,“~”表示匹配正则表达式,“!~”表示不匹配正则表达式(如$1 !~ /john/),其它变量比较操作使用>,>=,<,<=,==,!=,数据类型自动匹配。判断时,可以用if(compare),也可以直接compare或(compare),当然我推荐用if(compare),否则对于语法的记忆比较麻烦,容易出错。比较语句使用&&,||,!操作符,用法类似C语言。
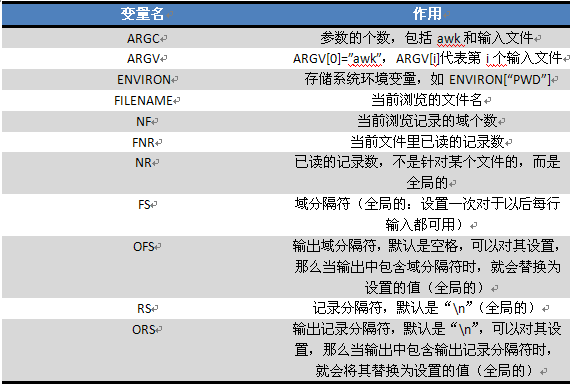
awk内置变量
内置字符串函数
字符串都用””括起来,正则用//括起来。

printf用法和C类似,但是不需要加()。如printf “%d/n” a。
可以向awk命令传递值:awk ‘END {print AGE}’ AGE=10 file。
awk,sed,tr支持在匹配特殊字符时可直接使用ctrl+v, ctrl+?来匹配。
awk,tr还支持/X形式来匹配特殊字符。
grep不支持特殊字符查找。
awk -F '/t' 'BEGIN {count=0} {count+=$3} END {print count}' 进行累加
awk '{print "'\"'"}'可用来输入单引号
awk '{print "\""}'可用来输入双引号