计划缓存中的缓存对象有什么不同
原文标题:What are the different cached objects in the plan cache?
原文地址:
http://blogs.msdn.com/b/sqlprogrammability/archive/2006/05/04/ketan-duvedi.aspx?wa=wsignin1.0
过程缓存又称为计划缓存,主要用来缓存查询计划以提高查询执行的性能。通过缓存编译计划和执行计划,系统就不需要每次执行的时候都编译查询了。这无疑将大幅提高性能,所以过程缓存也成为SQL SERVER中非常关键且常被用到的组件。除了计划会被缓存外,过程缓存中还包括algebrized视图、扩展存储过程(XPs)和非活动游标。
过程缓存中包含下面这些缓存:
1. 编译计划(CP)
2. 执行计划(MXC)
3. Algebrizer树(ProcHdr)
4. 扩展存储过程(XPs)
5. 非活动游标
CP、ProHdr和XPs都是顶层对象,它们被分别存放在不同的缓存存储区中(cachestore)。缓存存储区是SQL SERVER 2005中用来缓存东西的一种新机制。同一个缓存存储区拥有统一的缓存策略(比如成本、老化和换出机制)。通过执行sys.dm_os_memory_cache_hash_tables可以得到系统中所有缓存存储区的一个列表,执行sys.dm_exec_cached_plans可以得到编译计划缓存的内容。
MXC和非活动游标是作为每个相应编译计划的依赖对象而缓存的。它们存储在编译计划里面的链表中。执行sys.dm_exec_caced_plan_dependent_objects可以得到依赖给定CP的MXC和非活动游标。
编译计划(CP)
当我们编译一个查询时,我们为该查询生成一个编译计划(CP)。因为系统是为整个批(而不是每个语句)生成一个编译计划,所以如果一个批包含多个查询语句,那么CP就是批中所有查询而编译成的计划。批中每一条语句由一个CStmt表示,这样一个批就有一个CStmt数组。每个CStmt实际上包含特定语句的查询计划。CStmts数组实际上是存储在一个计划框架(plan skeleton)中。所以,一个CP包含计划框架、符号表、参数收集器、顶层内存对象、MXC链表等等。通常一个CP是非常宝贵的,因为编译一个查询的代价实在太大,所以我们想缓存它们,并且确保它们在内存压力下不是第一个被换出去。
基于查询类型的不同,系统有两类CP。如果查询是动态SQL或者是Prepared的,那么就是“SQL CP”;而像触发器、存储过程、函数等对象,我们称之为“OBJ CP”。这两类CP分别存储在不同的缓存存储区中。这样我们就有两个CP缓存存储区了:一个存储SQL CP;一个存储OBJ CP。一个CP可以被多个用户所共享。
在查询执行的过程中,系统从CP中为整个批生成一个执行计划(MXC)。CStmts中的每个编译计划转变成运行时的执行计划,被保存在XStmts中。就像MXC通过链表存放在CP中一样,XStmts是通过链表存放在CStmts中的。
执行计划(MXC)
执行计划(MXC)是运行时对象,它联系到CP上。MXC包括运行时参数、局部变量信息、一些运行时状态(如当前执行的stmt等)、运行时创建的对象的ID、包含运行时信息和其他信息的顶层内存对象等等。MXC是单用户的,所以如果有3个用户同时执行同一个批,那么就会有同一个CP的3个不同的MXC。所以CP和MXC之间是1:N的关系。MXC不能脱离CP而存在。相对于CP,也有两类不同MXC:SQL MXC和OBJ MXC。因为MXC是依附于CP的,所以他们不能保存到独立的缓存存储区中,而只能保存到CP中的。有两条MXC链表:第一条是查询链表,它保存CP的空闲的MXC(即没有被使用的);第二条是枚举链表,它保存着CP中所有的MXC(不管是否正在使用)。查询链表用来为执行的批找到一个MXC内存。枚举链表用来遍历一个CP中所有的MXC。这在计算批及其它东西使用的内存时很有用。
查询执行时,第一步先查找CP,如果不存在,就要编译这个查询,从而生成一个新的CP。一旦我们有了CP(不管是从缓存还是新生成的),我们就要检查MXC查询链表中是否有空闲MXC,如果没有任何空闲的MXC,那么我们需要生成一个新的MXC。如果查询列表有一个空闲MXC,那么我们将它从链表中取出然后使用。在执行结束时,我们根据是否需要缓存,或者销毁这个MXC或者将它还到空闲链表中。
Algebrizer 树 (ProcHdr)
ProcHdr是为存储过程、函数、触发器、约束、缺省和视图而创建的,它含有Algebrizer(即normailized,归一化)树。然而只有视图、约束和缺省的ProcHdr是缓存的。ProcHdr被存放在单独的缓存存储区中。每个Prochdr对象大小是8K。ProcHdr缓存存储区的HASH表的大小是CP缓存存储区HASH表的1/10。
扩展存储过程(XPs)
XPs是像sp_ExecuteSql, sp_CursorOpen, sp_TraceCreate这些预定义的存储过程。它们包括函数名称和实现的DLL名称。它们被存放在单独的缓存存储区中。因为每个缓存条目非常小,所以每个条目的内存对象为256字节。XP的缓存存储区的HASH表的大小总是127。
游标:
非活动的游标被缓存在编译计划中,这样并发使用游标就可以重复使用内存了。假设有一个批中定义并使用一个游标,但是没有删除它。如果有两个用户执行这个批,那么就会有两个活动的游标。一旦游标被删除(可能在其他批中),我们可以缓存这两个游标内存而不是释放它。这个非活动游标的链表被保存在CP中的CStmtCursorSelect(游标定义语句)中。下次有人要执行这个批,我们就可以重新使用这个被缓存的游标内存、适当初始化它,然后用作一个活动游标。
就像刚刚提过的,非活动游标存放在CP中对应CstmtCursorSelect的链表中。就像MXC,它也有两个链表:查询链表和枚举链表。查询链表只是保存非活动游标;枚举链表为游标语句(CStmtCursorSelect)保存所有游标(包括活动和非活动的),用来遍历给定语句(或CP)的所有游标。
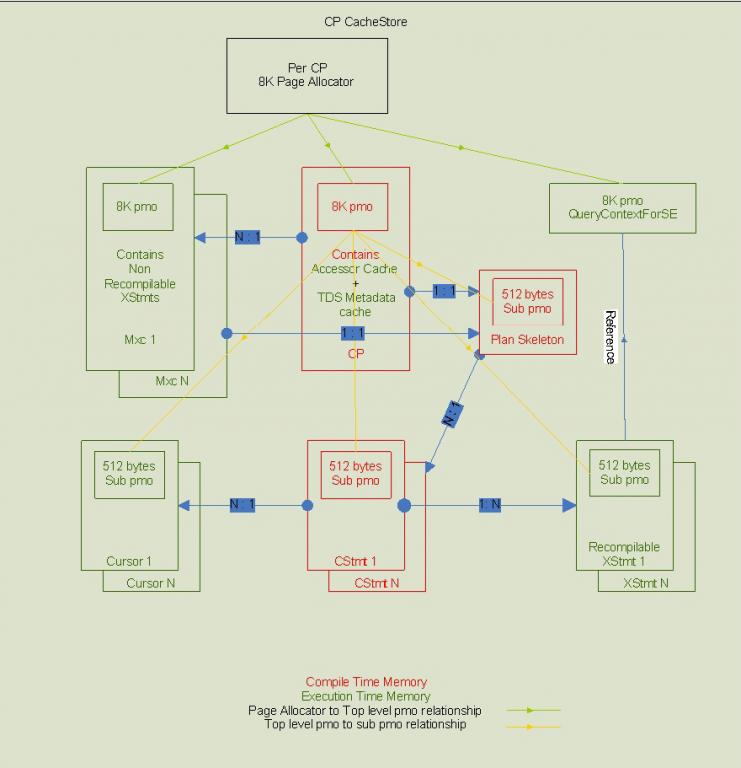
内存布局
一个批会在有下面这些内存对象:
•顶层的编译计划对象(CP_PMO,8K),这也包括为SE辅助缓存及TDS元数据缓存的内存。对于单语句批,由于没有为CStmt创建的子对象(sub pmo),所以分配的Stmt内存是从CP_PMO中分配的。如果需要的话,辅助缓存和TDS元数据缓存是在执行时创建的。这样,CP_PMO也会包括执行时内存,所以可能会在执行时看到内存会增加。
•顶层的MXC对象(MXC_PMO,8K),CP中每个MXC有一个MXC_PMO对象。该对象同时还包括批中非重编译的XStmts.
•顶层的QueryContextForSE对象(8K)。查询中每个XStmt对应一个QueryContextForSE对象。
•每个CStmt(除单语句批)一个下层对象(512字节)。它是从CP_PMO中创建的。
•每个重编译的XStmt一个下层对象(512字节)。这是从CP_PMO中创建的。对于NUMA机器,每个XStmt对象是一个8K的顶层对象,而不是下层对象。
•每个CP相连的框架一个下层对象(512字节)。这是从CP_PMO中创建的。
•每个游标一个下层对象(512字节)。这是从CP_PMO中创建的。
每个编译计划包括一个从缓存存储区中创建的页分配器。这个页分配器用来分配所有与批相关联的顶层的8K的内存对象。这样,编译和执行时的内存都来自于编译计划缓存存储区(CP cachestore)。