序言
这是一篇全面介绍 Webkit 和 Gecko 内部操作的入门文章,是以色列开发人员塔利·加希尔大量研究的成果。在过去的几年中,她查阅了所有公开发布的关于浏览器内部机制的数据(请参见资源),并花了很多时间来研读网络浏览器的源代码。她写道:
在 IE 占据 90% 市场份额的年代,我们除了把浏览器当成一个“黑箱”,什么也做不了。但是现在,开放源代码的浏览器拥有了过半的市场份额,因此,是时候来揭开神秘的面纱,一探网络浏览器的内幕了。呃,里面只有数以百万行计的
C++ 代码...
塔利在她的网站上公布了自己的研究成果,但是我们觉得它值得让更多的人来了解,所以我们在此重新整理并公布。
作为一名网络开发人员,学习浏览器的内部工作原理将有助于您作出更明智的决策,并理解那些最佳开发实践的个中缘由。尽管这是一篇相当长的文档,但是我们建议您花些时间来仔细阅读;读完之后,您肯定会觉得所费不虚。保罗·爱丽诗 (Paul Irish),Chrome 浏览器开发人员事务部
简介
网络浏览器很可能是使用最广的软件。在这篇入门文章中,我将会介绍它们的幕后工作原理。我们会了解到,从您在地址栏输入google.com直到您在浏览器屏幕上看到 Google 首页的整个过程中都发生了些什么。
目录
1.1我们要讨论的浏览器
目前使用的主流浏览器有五个:Internet Explorer、Firefox、Safari、Chrome 浏览器和 Opera。本文中以开放源代码浏览器为例,即 Firefox、Chrome 浏览器和 Safari(部分开源)。根据StatCounter 浏览器统计数据,目前(2011
年 8 月)Firefox、Safari 和 Chrome 浏览器的总市场占有率将近 60%。由此可见,如今开放源代码浏览器在浏览器市场中占据了非常坚实的部分。
1.2浏览器的主要功能
浏览器的主要功能就是向服务器发出请求,在浏览器窗口中展示您选择的网络资源。这里所说的资源一般是指 HTML 文档,也可以是 PDF、图片或其他的类型。资源的位置由用户使用 URI(统一资源标示符)指定。
浏览器解释并显示 HTML 文件的方式是在 HTML 和 CSS 规范中指定的。这些规范由网络标准化组织W3C(万维网联盟)进行维护。
多年以来,各浏览器都没有完全遵从这些规范,同时还在开发自己独有的扩展程序,这给网络开发人员带来了严重的兼容性问题。如今,大多数的浏览器都是或多或少地遵从规范。
浏览器的用户界面有很多彼此相同的元素,其中包括:
- 用来输入 URI 的地址栏
- 前进和后退按钮
- 书签设置选项
- 用于刷新和停止加载当前文档的刷新和停止按钮
- 用于返回主页的主页按钮
奇怪的是,浏览器的用户界面并没有任何正式的规范,这是多年来的最佳实践自然发展以及彼此之间相互模仿的结果。HTML5 也没有定义浏览器必须具有的用户界面元素,但列出了一些通用的元素,例如地址栏、状态栏和工具栏等。当然,各浏览器也可以有自己独特的功能,比如 Firefox 的下载管理器。
1.3浏览器的高层结构
浏览器的主要组件为 (1.1):
- 用户界面- 包括地址栏、前进/后退按钮、书签菜单等。除了浏览器主窗口显示的您请求的页面外,其他显示的各个部分都属于用户界面。
- 浏览器引擎- 在用户界面和呈现引擎之间传送指令。
- 呈现引擎- 负责显示请求的内容。如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
- 网络- 用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
- 用户界面后端- 用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
- JavaScript 解释器。用于解析和执行 JavaScript 代码。
- 数据存储。这是持久层。浏览器需要在硬盘上保存各种数据,例如 Cookie。新的 HTML 规范 (HTML5) 定义了“网络数据库”,这是一个完整(但是轻便)的浏览器内数据库。
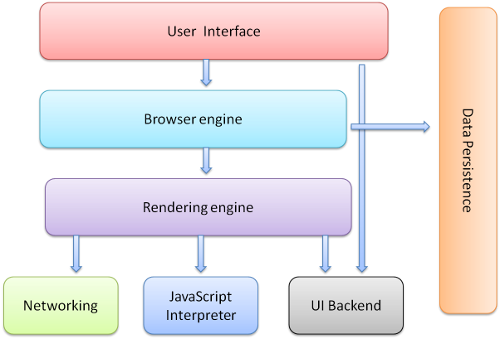
图:浏览器的主要组件。
值得注意的是,和大多数浏览器不同,Chrome 浏览器的每个标签页都分别对应一个呈现引擎实例。每个标签页都是一个独立的进程。
Chapter 2
呈现引擎
呈现引擎的作用嘛...当然就是“呈现”了,也就是在浏览器的屏幕上显示请求的内容。
默认情况下,呈现引擎可显示 HTML 和 XML 文档与图片。通过插件(或浏览器扩展程序),还可以显示其它类型的内容;例如,使用 PDF 查看器插件就能显示 PDF 文档。但是在本章中,我们将集中介绍其主要用途:显示使用 CSS 格式化的 HTML 内容和图片。
2.1呈现引擎
本文所讨论的浏览器(Firefox、Chrome 浏览器和 Safari)是基于两种呈现引擎构建的。Firefox 使用的是 Gecko,这是 Mozilla 公司“自制”的呈现引擎。而 Safari 和 Chrome 浏览器使用的都是 Webkit。
Webkit 是一种开放源代码呈现引擎,起初用于 Linux 平台,随后由 Apple 公司进行修改,从而支持苹果机和 Windows。有关详情,请参阅webkit.org。
2.2主流程
呈现引擎一开始会从网络层获取请求文档的内容,内容的大小一般限制在 8000 个块以内。
然后进行如下所示的基本流程:

图:呈现引擎的基本流程。
呈现引擎将开始解析 HTML 文档,并将各标记逐个转化成“内容树”上的DOM节点。同时也会解析外部 CSS 文件以及样式元素中的样式数据。HTML 中这些带有视觉指令的样式信息将用于创建另一个树结构:呈现树。
呈现树包含多个带有视觉属性(如颜色和尺寸)的矩形。这些矩形的排列顺序就是它们将在屏幕上显示的顺序。
呈现树构建完毕之后,进入“布局”处理阶段,也就是为每个节点分配一个应出现在屏幕上的确切坐标。下一个阶段是绘制-
呈现引擎会遍历呈现树,由用户界面后端层将每个节点绘制出来。
需要着重指出的是,这是一个渐进的过程。为达到更好的用户体验,呈现引擎会力求尽快将内容显示在屏幕上。它不必等到整个 HTML 文档解析完毕之后,就会开始构建呈现树和设置布局。在不断接收和处理来自网络的其余内容的同时,呈现引擎会将部分内容解析并显示出来。
2.3主流程示例
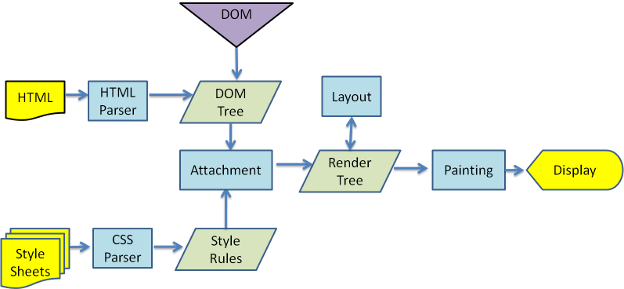
图:Webkit 主流程
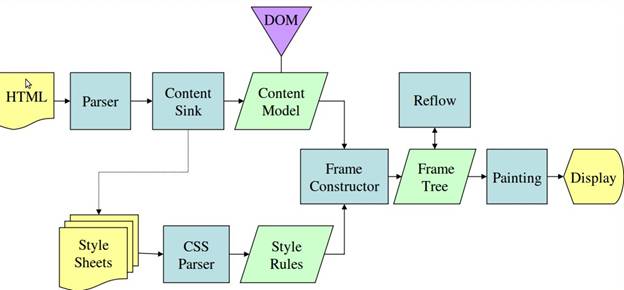
图:Mozilla 的 Gecko 呈现引擎主流程 (3.6)
从图 3 和图 4 可以看出,虽然 Webkit 和 Gecko 使用的术语略有不同,但整体流程是基本相同的。
Gecko 将视觉格式化元素组成的树称为“框架树”。每个元素都是一个框架。Webkit 使用的术语是“呈现树”,它由“呈现对象”组成。对于元素的放置,Webkit 使用的术语是“布局”,而 Gecko 称之为“重排”。对于连接 DOM 节点和可视化信息从而创建呈现树的过程,Webkit 使用的术语是“附加”。有一个细微的非语义差别,就是 Gecko 在 HTML 与 DOM 树之间还有一个称为“内容槽”的层,用于生成 DOM 元素。我们会逐一论述流程中的每一部分:
Chapter 3
3.1解析 - 综述
解析是呈现引擎中非常重要的一个环节,因此我们要更深入地讲解。首先,来介绍一下解析。
解析文档是指将文档转化成为有意义的结构,也就是可让代码理解和使用的结构。解析得到的结果通常是代表了文档结构的节点树,它称作解析树或者语法树。
示例 - 解析2 + 3 - 1这个表达式,会返回下面的树:
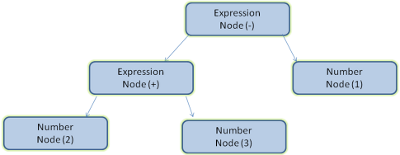
图:数学表达式树节点
3.1.1语法
解析是以文档所遵循的语法规则(编写文档所用的语言或格式)为基础的。所有可以解析的格式都必须对应确定的语法(由词汇和语法规则构成)。这称为与上下文无关的语法。人类语言并不属于这样的语言,因此无法用常规的解析技术进行解析。
3.1.2解析器和词法分析器的组合
解析的过程可以分成两个子过程:词法分析和语法分析。
词法分析是将输入内容分割成大量标记的过程。标记是语言中的词汇,即构成内容的单位。在人类语言中,它相当于语言字典中的单词。
语法分析是应用语言的语法规则的过程。
解析器通常将解析工作分给以下两个组件来处理:词法分析器(有时也称为标记生成器),负责将输入内容分解成一个个有效标记;而解析器负责根据语言的语法规则分析文档的结构,从而构建解析树。词法分析器知道如何将无关的字符(比如空格和换行符)分离出来。
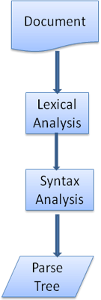
图:从源文档到解析树
解析是一个迭代的过程。通常,解析器会向词法分析器请求一个新标记,并尝试将其与某条语法规则进行匹配。如果发现了匹配规则,解析器会将一个对应于该标记的节点添加到解析树中,然后继续请求下一个标记。
如果没有规则可以匹配,解析器就会将标记存储到内部,并继续请求标记,直至找到可与所有内部存储的标记匹配的规则。如果找不到任何匹配规则,解析器就会引发一个异常。这意味着文档无效,包含语法错误。
3.1.3翻译
很多时候,解析树还不是最终产品。解析通常是在翻译过程中使用的,而翻译是指将输入文档转换成另一种格式。编译就是这样一个例子。编译器可将源代码编译成机器代码,具体过程是首先将源代码解析成解析树,然后将解析树翻译成机器代码文档。
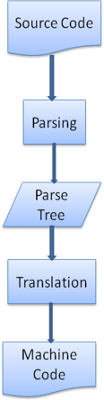
图:编译流程
3.1.4解析示例
在图 5 中,我们通过一个数学表达式建立了解析树。现在,让我们试着定义一个简单的数学语言,用来演示解析的过程。
词汇:我们用的语言可包含整数、加号和减号。
语法:
- 构成语言的语法单位是表达式、项和运算符。
- 我们用的语言可以包含任意数量的表达式。
- 表达式的定义是:一个“项”接一个“运算符”,然后再接一个“项”。
- 运算符是加号或减号。
- 项是一个整数或一个表达式。
让我们分析一下2 + 3 - 1。
匹配语法规则的第一个子串是2,而根据第 5 条语法规则,这是一个项。匹配语法规则的第二个子串是2
+ 3,而根据第 3 条规则(一个项接一个运算符,然后再接一个项),这是一个表达式。下一个匹配项已经到了输入的结束。2 + 3 - 1是一个表达式,因为我们已经知道2
+ 3是一个项,这样就符合“一个项接一个运算符,然后再接一个项”的规则。2 + +不与任何规则匹配,因此是无效的输入。
3.1.5词汇和语法的正式定义
词汇通常用正则表达式表示。
例如,我们的示例语言可以定义如下:
INTEGER :0|[1-9][0-9]* PLUS : + MINUS: -
正如您所看到的,这里用正则表达式给出了整数的定义。
语法通常使用一种称为BNF的格式来定义。我们的示例语言可以定义如下:
expression := term operation term operation := PLUS | MINUS term := INTEGER | expression
之前我们说过,如果语言的语法是与上下文无关的语法,就可以由常规解析器进行解析。与上下文无关的语法的直观定义就是可以完全用 BNF 格式表达的语法。有关正式定义,请参阅关于与上下文无关的语法的维基百科文章。
3.1.6解析器类型
有两种基本类型的解析器:自上而下解析器和自下而上解析器。直观地来说,自上而下的解析器从语法的高层结构出发,尝试从中找到匹配的结构。而自下而上的解析器从低层规则出发,将输入内容逐步转化为语法规则,直至满足高层规则。
让我们来看看这两种解析器会如何解析我们的示例:
自上而下的解析器会从高层的规则开始:首先将2 + 3标识为一个表达式,然后将2
+ 3 - 1标识为一个表达式(标识表达式的过程涉及到匹配其他规则,但是起点是最高级别的规则)。
自下而上的解析器将扫描输入内容,找到匹配的规则后,将匹配的输入内容替换成规则。如此继续替换,直到输入内容的结尾。部分匹配的表达式保存在解析器的堆栈中。
| 堆栈 | 输入 | |
|---|---|---|
| 2 + 3 - 1 | ||
|
|