JobClient的runJob()方法是用于新建JobClient实例和调用其submitJob()方法。提交作业后,runJob()将每秒轮询作业的进度,如果发现与上一个记录不同,便把报告显示到控制台。作业完成后,如果成功,就显示作业计数器。否则,导致作业失败的错误会被记录到控制台。
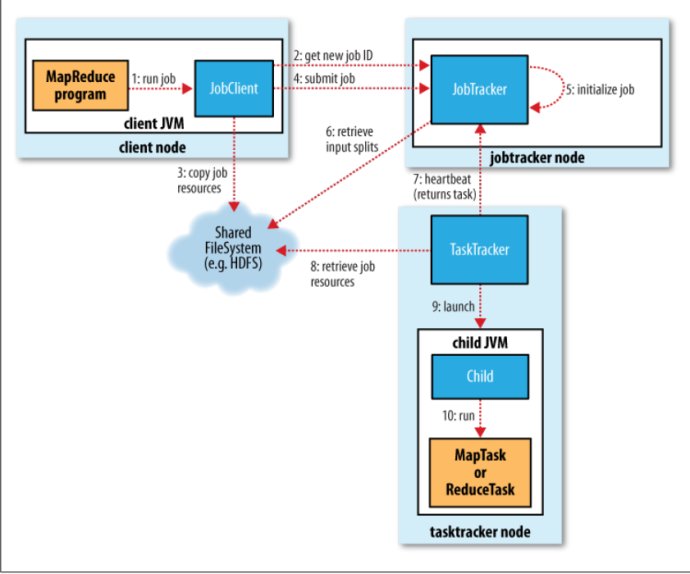
1、向jobtracker请求一个新的作业ID(通过Jobtracker的getNewJobId())
2、检查作业的输出说明。比如,如果没有指定输出目录或者它已经存在,作业就不会被提交,并有错误返回给MapReduce程序。
3、计算作业的输出划分。如果划分无法计算,比如因为输入路径不存在,作业就不会被提交,并有错误返回给MapReduce程序。
4、将运行作业所需要的资源---包括作业的JAR文件、配置文件和计算所得的输入划分--复制到一个以作业ID号命名的目录中jobtracker的文件系统。作业JAR的副本较多(由mapred.submit.replication 属性控制,默认为10),如此一来,在tasktracker运行作业任务时,集群能为它们提供许多副本进行访问。(步骤3)
5、告诉jobtracker作业准备执行(通过调用JobTracker的submitJob()方法)(步骤4)
6、Jobtracker接受到对其submitJob()方法调用后,会把此调用放入一个内部的队列中,交由作业调度器进行调度,并对其进行初始化。初始化包括创建一个代表该正在运行的作业的对象,它封装任务和记录信息,以便跟踪任务的状态和进程(步骤5)
7、要创建运行任务列表,作业调度器首先从共享文件系统中获取JobClient已经计算好的输入划分信息(步骤6)然后为每个划分创建一个map任务。创建的reduce任务的数量由JobConf的mapred.reduce.tasks属性决定,它是用setNumReduceTasks()方法来设定的,然后调度器便创建这么多reduce任务来运行。任务在此时指定ID号。
8、TaskTraker 执行一个简单的循环,定期发送心跳(heartbeat)方法调用Jobtracker。心跳方法告诉jobtracker,tasktracker是否存活,同时也充当两者之间的消息通道。作业心跳方法调用的一部分,tasktracker会指明它是否已经准备运行新的任务,如果是,jobtracker会为他分配一个任务,并使用心跳方法的返回值与tasktracker进行通信(步骤7)
9、现在,tasktracker已经被分配了任务,下一步是运行任务。首先,它本地化作业的JAR文件,将它从共享文件系统复制到tasktracker所在的文件系统。同时,将应用程序所需要的全部文件从分布式缓存复制到本地磁盘。然后,为任务新建一个本地工作目录,并把JAR文件中的内容解压到这个文件夹下。第三步,新建一个TaskRunner实例来运行任务。
TaskRunner启动一个新的Java虚拟机(步骤9)来运行每个任务(步骤10),使得用户第一的map和reduce函数的任何缺陷都不会影响tasktracker(比如导致它崩溃或者挂起)。但在不同的任务之间重用JVM还是可能的。
子进程通过 umbilical 接口与父进程进行通信。它每隔几秒便告知父进程它的进度,直到任务完成。