并发编程中的NUMA架构
为更高的扩展性和NUMA做准备
近年来,多处理器支持的最广泛的模型对称多处理器(SMP)让位于非均匀存储器存取(NUMA)架构。对称多处理器模型的一个最大的问题就是处理器总线会限制未来的可伸缩性,因为每一个处理器拥有同样的机会访问内存和输入输出系统。
使用非均匀内存访问架构,每个处理器可以更快的访问离自己近的内存。当处理器的数目超过四个的时候,非均匀内存访问架构可以提供更好的伸缩性。在windows的可伸缩性技术条款中,非均匀内存访问架构按照下面所属进行组织(见图1-17)
每个计算机或者机器可以有一个或者多个组。
每个组有一个或者多个非均匀内存访问节点。
每个非均匀内存访问架构节点有一个或者多个物理处理器或者插槽(一个真正的微处理
器)。组成这些非均匀内存访问架构节点的不同微处理器可以访问一块本地内存和io。
每个处理器或者插槽有一个或者多个物理核心,因为他们通常是一个多核的微处理器。
每一个物理核心可以提供一个或者多个逻辑处理器或者硬件线程。
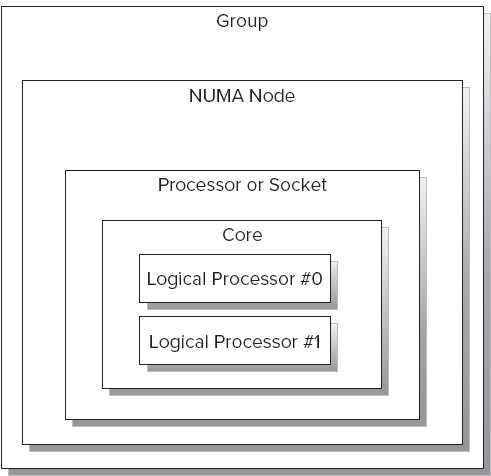
图 1-17
图1-18展示了带有一个由两个非均匀内存访问架构节点组成的计算机。每个非均匀内存访问架构节点有两个可以访问自己本地内存和io的微处理器。如果一个运行在处理非均匀内存访问架构节点#0的处理器#0的物理核心#0上的新城需要方位位于非均匀内存访问架构节点#1的本地内存里,那么它就必须使用两者之间的共享总线,但是这个要比访问自己的本地内存要慢。
带有非均匀内存访问架构的计算机有多余一个的系统总线。某一组特定的处理器使用自己可用的系统总线。因此,每组处理器可以访问它自己的内存和它自己的io通道。就像前边所解释的,以适当的协调方案他们仍然有能力访问其他处理器所拥有的内存。然而,很显然访问其他节点的内存要比通过自己的本地系统总线访问本地内存要昂贵得多。
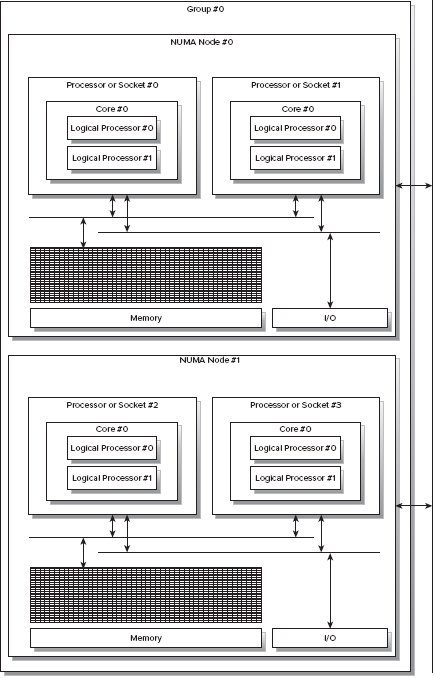
图 1-18
非均匀内存访问架构的硬件需要特定的优化技术。应用程序必须要知道非均匀内存访问架构的硬件和它的配置。所以,他们可以运行那些需要访问同一个非均匀内存访问节点的类似内存位置的并发任务和线程。应用程序必须要避免昂贵的内存访问,并且他们必须要支持并发和考虑内存的需求。
Windows 7 和windows 2008 R2引入的前边提到的处理器组的概念。运行在一个特定核心、处理器、节点或者组上的一个线程、进程或者中断的草组可以显示偏好。然而在TPL和C#中却没有支持这种低级别的定义。TPL对在非均匀内存访问架构的工作进行了优化,它尽量的使用那些最方便支持并行的核心和尽可能的使用本地内存的线程。因此,虽然你的代码已经对非均匀内存访问架构做了优化,但是当支持你的并行代码的线程需要访问其他节点的内存的时候,你仍然会面对一些难以预料的性能问题。
虽然windows的API提供了很多函数来帮助在NUMA架构上工作,但是他们并不兼容托管线程。因此,在使用C#和TPL的时候就不能使用它们了。
Coreinfo是一个简单的功能强大的命令行工具,它可以为你展示关于处理器,处理器的组织和缓存拓扑的有用信息。它可以展示逻辑处理器或者硬件线程和物理核心之间的映射关系。除此之外,它可以展示有关NUMA节点、组、插槽和所有缓存级别的信息。在运行你的性能测试之前,你可以很容易的保存有关这些硬件的信息,你也可以推测是否是NUMA架构导致了性能问题。你可以在这个网址http://technet.microsoft.com/en-us/sysinternals/cc835722
.aspx下载Coreinfo2.0.然后,你可以解压缩可执行文件并在命令行里执行它。
这个工具使用windows API中的GetLogicalProcessorInfomation函数获取所有信息并展示在屏幕上。列表1-1展示了在一个使用英特尔i7微处理器的电脑上运行Coreinfo2.0的输出结果。在逻辑处理器和物理处理器映射部分显示一个单独的插槽有四个物理核心。然而,由于这个中央处理器提供了英特尔超线程技术,Coreinfo告诉我们它是Hyperthreaded。Coreinfo使用一个星号来展示映射。在这个例子中,四个物理核心每个都有两个物理线程;所以使用了两个星号。除此之外,还有一个统一的8MB的3级缓存。这八个物理线程共享这个缓存;因此,Coreinfo在Logical
Processor to Cache Map的最后一行的左边显示了八个星号。这意味着这个缓存被映射到所有的硬件线程和他们的物理核心。
LISTING 1-1: Information displayed by CoreInfo v2.0 for a single Intel Core i7
Logical to Physical Processor Map:
**------ Physical Processor 0 (Hyperthreaded)
--**---- Physical Processor 1 (Hyperthreaded)
----**-- Physical Processor 2 (Hyperthreaded)
------** Physical Processor 3 (Hyperthreaded)
Logical Processor to Socket Map:
******** Socket 0
Logical Processor to NUMA Node Map:
******** NUMA Node 0
Logical Processor to Cache Map:
**------ Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
**------ Instruction Cache 0, Level 1, 32 KB, Assoc 4, LineSize 64
**------ Unified Cache 0, Level 2, 256 KB, Assoc 8, LineSize 64
--**---- Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
--**---- Instruction Cache 1, Level 1, 32 KB, Assoc 4, LineSize 64
--**---- Unified Cache 1, Level 2, 256 KB, Assoc 8, LineSize 64
----**-- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
----**-- Instruction Cache 2, Level 1, 32 KB, Assoc 4, LineSize 64
----**-- Unified Cache 2, Level 2, 256 KB, Assoc 8, LineSize 64
------** Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
------** Instruction Cache 3, Level 1, 32 KB, Assoc 4, LineSize 64
------** Unified Cache 3, Level 2, 256 KB, Assoc 8, LineSize 64
******** Unified Cache 4, Level 3, 8 MB, Assoc 16, LineSize 64
Logical Processor to Group Map:
******** Group 0
列表1-2展示了在一个使用英特尔i7有两个NUMA节点的电脑上运行coreinfo2的结果。每个NUMA节点有带有八个物理线程的插槽。
LISTING 1-2: Information displayed by CoreInfo v2.0 for two NUMA nodes with a single Intel
Core i7 inside each one
Logical to Physical Processor Map:
**-------------- Physical Processor 0 (Hyperthreaded)
--**------------ Physical Processor 1 (Hyperthreaded)
----**---------- Physical Processor 2 (Hyperthreaded)
------**-------- Physical Processor 3 (Hyperthreaded)
--------**------ Physical Processor 4 (Hyperthreaded)
----------**---- Physical Processor 5 (Hyperthreaded)
------------**-- Physical Processor 6 (Hyperthreaded)
--------------** Physical Processor 7 (Hyperthreaded)
Logical Processor to Socket Map:
********-------- Socket 0
--------******** Socket 1
Logical Processor to NUMA Node Map:
********-------- NUMA Node 0
--------******** NUMA Node 1
Logical Processor to Cache Map:
**-------------- Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
**-------------- Instruction Cache 0, Level 1, 32 KB, Assoc 4, LineSize 64
**-------------- Unified Cache 0, Level 2, 256 KB, Assoc 8, LineSize 64
--**------------ Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
--**------------ Instruction Cache 1, Level 1, 32 KB, Assoc 4, LineSize 64
--**------------ Unified Cache 1, Level 2, 256 KB, Assoc 8, LineSize 64
----**---------- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
----**---------- Instruction Cache 2, Level 1, 32 KB, Assoc 4, LineSize 64
----**---------- Unified Cache 2, Level 2, 256 KB, Assoc 8, LineSize 64
------**-------- Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
------**-------- Instruction Cache 3, Level 1, 32 KB, Assoc 4, LineSize 64
------**-------- Unified Cache 3, Level 2, 256 KB, Assoc 8, LineSize 64
********-------- Unified Cache 4, Level 3, 8 MB, Assoc 16, LineSize 64
--------**------ Data Cache 5, Level 1, 32 KB, Assoc 8, LineSize 64
--------**------ Instruction Cache 5, Level 1, 32 KB, Assoc 4, LineSize 64
--------**------ Unified Cache 5, Level 2, 256 KB, Assoc 8, LineSize 64
----------**---- Data Cache 6, Level 1, 32 KB, Assoc 8, LineSize 64
----------**---- Instruction Cache 6, Level 1, 32 KB, Assoc 4, LineSize 64
----------**---- Unified Cache 6, Level 2, 256 KB, Assoc 8, LineSize 64
------------**-- Data Cache 7, Level 1, 32 KB, Assoc 8, LineSize 64
------------**-- Instruction Cache 7, Level 1, 32 KB, Assoc 4, LineSize 64
------------**-- Unified Cache 7, Level 2, 256 KB, Assoc 8, LineSize 64
--------------** Data Cache 8, Level 1, 32 KB, Assoc 8, LineSize 64
--------------** Instruction Cache 8, Level 1, 32 KB, Assoc 4, LineSize 64
--------------** Unified Cache 8, Level 2, 256 KB, Assoc 8, LineSize 64
--------******** Unified Cache 9, Level 3, 8 MB, Assoc 16, LineSize 64
Logical Processor to Group Map:
**************** Group 0
当在NUMA架构上工作的时候,为了避免需要频繁的方位其他NUMA节点的内存,测试不同的分区技术是很重要的。它既是所有的潜在的因素。
决定是否使用并行
有时候,并行并不是最好的优化算法的选择。只有在并行可以比顺序执行有比较大的性能提升的时候,并行才有意义。没有银弹可以决定是否适合使用并行,这需要依靠某个特定解决方案的特点和性能的需求来决定。例如,如果一个并行算法可以减少完成一个工作30%的时间,这在串行版本只需要很短时间时是微不足道的。然而,如果你完成同样的性能提升的是一个需要十八个小时执行完的批处理过程,你可以少之星十三个小时,这个时候使用并行是有意义的。
你可以考虑并行执行的额外特性来改善已有程序。你可以设计解决方案来更加灵敏的应对用户通过异步的任务和线程利用并行的优势。
并行编程比经典的串行编程更加复杂。然而,一旦你开始创建基于任务的设计和编写并行代码,避免并行的思想是很困难的。