最近这几天验证了下LZO这种压缩模式,有以下感觉:
最近LZO的使用问题,发现java.library.path设置问题,很多网上写的是在hadoop-env.sh文件里增加JAVA_LIBRARY_PATH这个属性(关于另一个增加HADOOP_CLASSPATH是有效的,确实在这个hadoop-0.20.205.0版本确实启动时,不会自动加载lib目录下的jar包)。
而我设置这个参数确实是没效果,我后来自己写了一个获取打印出java.library.path的,运行结果如下:
[hadoop@master hive_testdata]$ java Test_loadLibrary
/home/hadoop/jrockit-jdk1.6.0_29/jre/lib/amd64/jrockit:/home/hadoop/jrockit-jdk1.6.0_29/jre/lib/amd64:/home/hadoop/jrockit-jdk1.6.0_29/jre/../lib/amd64::/usr/local/lib
Load success
libgplcompression.so
第一行是我当前系统获取java.library.path的值
第二行是我自己把相关本地库放在/usr/local/lib下面后,加载成功了
第三行是测试在Liunx下面System.mapLibraryName这个方法返回值是什么
Test_loadLibrary.java源码如下:
import java.util.Properties;
import java.util.Set;
public class Test_loadLibrary
{
public static void main(String[] args)
{
Properties props = System.getProperties();
Set<Object> keys = props.keySet();
for (Object key : keys){
if (((String) key).equals("java.library.path"))
System.out.println(System.getProperty("java.library.path"));
if (((String) key).equals("."))
System.out.println(System.getProperty("."));
}
try{
System.loadLibrary("gplcompression");
System.out.println("Load success");
}catch (Throwable t) {
System.out.println("Error");
t.printStackTrace();
}
System.out.println(System.mapLibraryName("gplcompression"));
}
}
当我把相关本地库放在其中一个目录下面(/usr/local/lib),然后运行还是抱找不到gplcompression本地库。
后来没办法,修改了hadoop-lzo的GPLNativeCodeLoader的代码,增加了一个打印java.library.path的路径值,结果如下:
12/05/08 14:45:39 INFO lzo.GPLNativeCodeLoader: /home/hadoop/hadoop-0.20.205.0/libexec/../lib
12/05/08 14:45:39 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library
果然java.library.path是在$HADOOP_HOME/lib目录下,后来我把相关的本地库都放在$HADOOP_HOME/lib下面,运行总算成功了。
目前我还不知道原因,也许是我使用了的Jrockit的JVM吧(瞎猜的)。
经测试LZO发现,确实对性能上面提升很多。
但是有一个问题,就是如果用在streamming的(非java语言上面)方式的话,那么就很麻烦。目前我使用LZO的模式后,发现hive很多表结构要修改,并且查询单列数据都不是很正常。
例如:count这样的出来是NULL值,获取随机一列数据如果带有中文字符的就是乱码等很多问题产生。
另外网上也有介绍hive读取lzo的方式,网址:http://www.mrbalky.com/2011/02/24/hive-tables-partitions-and-lzo-compression/
但是这种方式是在HDFS里产生文件都带有后缀,如下图:
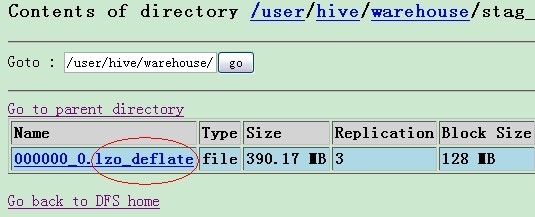
另外就是使用LZO后,产生的文件就一个(如果文件容量不大还好,如果太大就放在一个文件里就很折腾啊)。
但在hive里读取的时候,却任何数据都没读出来,如下图:

目前结论是hive生产环境中暂时不要使用如何压缩模式(默认格式即可),这样会导致在某些工具处理起来特别困难(特别使用streamming方式的功能,可能是需要实现LZO的解压方式吧)。
相关问题有很多,有待继续专研和攻克下去!!!