我们平时看到的文件,其本质上是有词组成的,我们可以看做是词的集合,当我们把相同的词就可以看做是一个词的向量了。
这里的tvx tvd tvf 就是以这种形式表示doc的:
tvx : doc的数量,以及每个doc 在 tvd 以及 tvf 中开始的位置。
tvd : 每个doc的域信息: 有多少个域,具体是那几个域,每个域向量在tvf文件中的位置,
tvf : 每个doc 的每域的 向量集合 ,向量集合中的每个元素就是一个 term: term文本,次数,位置等信息
这三者之间的关系,我们还是引用告诉的总结:
http://blog.csdn.net/forfuture1978/archive/2009/12/10/4976793.aspx
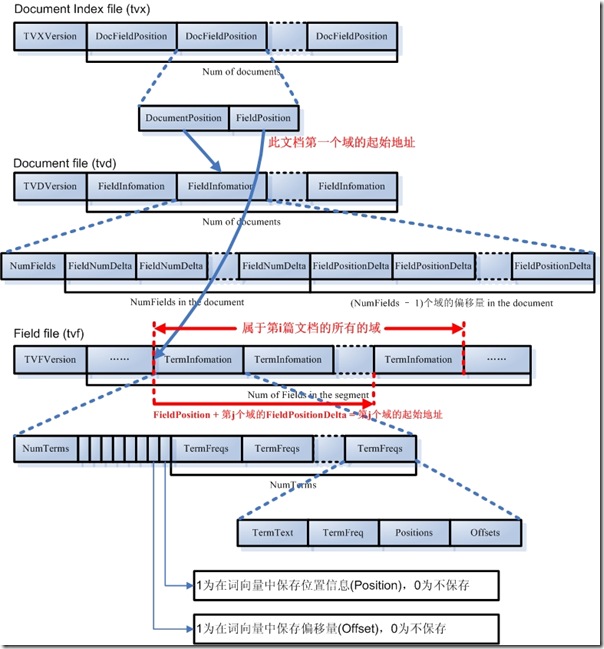
我们最后来看看源代码
1 首先在tvx 文件中写入 tvd 和tvf 开始的位置
2 在tvd中写入当前doc的字段的个数,然后遍历所有的字段,在tvd 中,写入每个字段的term 数目,已经每个term 具体信息在tvf中的位置, 最后写tvf信息,遍历每隔term ,写入每个term 信息。