schedule子句是专门为循环并行构造的时候使用的子句,只能用于循环并行构造(parallel for)中。
根据OpenMP Spec(http://openmp.org/mp-documents/OpenMP3.1-CCard.pdf)可以知道:
schedule的语法为:
schedule(kind[, chunk_size])
kind:
• static: Iterations are divided into chunks of size chunk_size. Chunks are assigned to threads in the team in round-robin fashion in order of thread number.
• dynamic: Each thread executes a chunk of iterations then requests another chunk until no chunks remain to be distributed.
• guided: Each thread executes a chunk of iterations then requests another chunk until no chunks remain to be assigned. The chunk sizes start large and shrink to the indicated chunk_size as chunks are scheduled.
• auto: The decision regarding scheduling is delegated to the compiler and/or runtime system.
• runtime: The schedule and chunk size are taken from the run-sched-var ICV
(1)schedule的作用:
上面知道,schedule只能用于循环并行构造中,其作用是用于控制循环并行结构的任务调度。一个简单的理解,一个for循环假设有10此迭代,使用4个线程去执行,那么哪些线程去执行哪些迭代呢?可以通过schedule去控制迭代的调度和分配,从而适应不同的使用情况,提高性能。
(1)schedule语法:
schedule(kind [, chunk_size]),其中kind可以取值为static,dynamic,guided,auto,runtime。其中,测试发现,auto貌似是不行的(可能是Fortran才支持?不清楚)。参数chunk_size是一个size的参数,所以是整数了。这里的runtime在后面分析,其实本质上是前面三种类型之一。
所以,schedule的类型一共是三种:static、dynamic、guided。下面先逐一分析这三种,最后再来了解runtime的含义。
(2)静态调度static:
大部分的编译器实现,在没有使用schedule子句的时候,系统就是采用static方式调度的。
对于schedule(static,size)的含义,OpenMP会给每个线程分配size次迭代计算。这个分配是静态的,“静态”体现在这个分配过程跟实际的运行是无关的,可以从逻辑上推断出哪几次迭代会在哪几个线程上运行。具体而言,对于一个N次迭代,使用M个线程,那么,[0,size-1]的size次的迭代是在第一个线程上运行,[size, size + size -1]是在第二个线程上运行,依次类推。那么,如果M太大,size也很大,就可能出现很多个迭代在一个线程上运行,而某些线程不执行任何迭代。需要说明的是,这个分配过程就是这样确定的,不会因为运行的情况改变,比如,我们知道,进入OpenMP后,假设有M个线程,这M个线程开始执行的时间不一定是一样的,这是由OpenMP去调度的,并不会因为某一个线程先被启动,而去改变for的迭代的分配,这就是静态的含义。分析下面的例子:
#include <omp.h>
#define COUNT 4*3
int main(int argc, _TCHAR* argv[])
{
#pragma omp parallel for schedule(static,4)
for(int i = 0;i < COUNT; i++)
{
printf("Thread: %d, Iteration: %d\n", omp_get_thread_num(), i);
}
return 0;
}
下面是其中多次运行的几次结果(四核系统,所以线程数量为4):
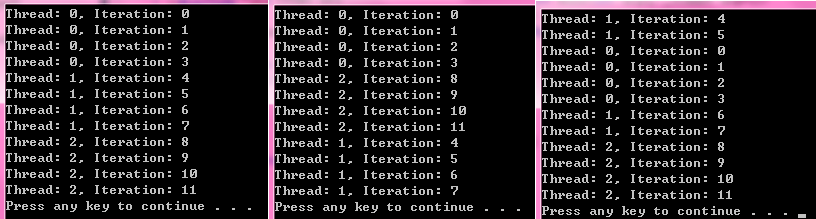
从左到由假设为结果1/2/3,从结果可以看到,无论是哪一个线程先启动,team内的ID为0的线程,总是会执行0,1,2,3对应的迭代,team内ID为1的线程,总是会执行4,5,6,7对应的迭代,team内ID为2的线程,总是会执行8,9,10,11的线程,而team内线程ID为4的线程,并没有去执行任何迭代。如果把上面的size的大小改为12,那么无论如何,所有的迭代都只会在线程0上执行,其实就跟串行的效果一样了。对于这里的情况,4个线程,却只使用了3个线程去计算,所以这样分配当然是不平衡的。
上面是针对给定size的情况,如果不指定size,只是指定static类型,那么OpenMP为使用迭代数/线程数作为size的值,采取同样的策略来进行分配,这样每个线程执行的迭代数目就是一样的(注意,如果迭代数/线程数不是整除的,那就不完全一样了,但是整体是比较平衡的),一般而言,这就是不加任何schedule修饰下的调度情况了。
(3)动态调度dynamic
动态调度迭代的分配是依赖于运行状态进行动态确定的,所以哪个线程上将会运行哪些迭代是无法像静态一样事先预料的。对于dynamic,没有size参数的情况下,每个线程按先执行完先分配的方式执行1次循环,比如,刚开始,线程1先启动,那么会为线程1分配一次循环开始去执行(i=0的迭代),然后,可能线程2启动了,那么为线程2分配一次循环去执行(i=1的迭代),假设这时候线程0和线程3没有启动,而线程1的迭代已经执行完,可能会继续为线程1分配一次迭代,如果线程0或3先启动了,可能会为之分配一次迭代,直到把所有的迭代分配完。所以,动态分配的结果是无法事先知道的,因为我们无法知道哪一个线程会先启动,哪一个线程执行某一个迭代需要多久等等,这些都是取决于系统的资源、线程的调度等等。看下面的例子:
#include <omp.h>
#include <Windows.h>
#define COUNT 4*3
int main(int argc, _TCHAR* argv[])
{
#pragma omp parallel for schedule(dynamic)
for(int i = 0;i < COUNT; i++)
{
printf("Thread: %d, Iteration: %d\n", omp_get_thread_num(), i);
}
return 0;
}
下面也是多次运行的结果:
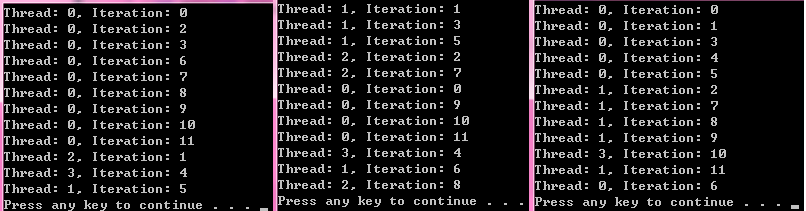
事实上,这个结果容易给人误解,以结果2来分析,为什么线程1先执行完,其对应的迭代却是1而不是0呢?而且接下来也是3而不是2呢?不是先执行完的先分配么?我的理解是,这里,刚开始的时候,我们不知道线程的状态,实际的一种可能是,线程0先启动了,所以会去执行迭代0里面的内容,但是,只是开始去执行,而这里用printf测试,是输出的结果,输出的顺序不代表开始执行此迭代的顺序,所以可能的情况是,线程0执行迭代0还没有完成的时候,线程1空闲,为线程1分配了迭代1,然后线程1一直运行迭代1的时候,线程0仍然在运行迭代0,这中间,线程2可能会分配了迭代2开始执行,线程1又获得了分配机会,被分配了迭代3等等。。。总之,这里的输出顺序是不代表每一个迭代开始被分配执行的时间顺序的。总之,理解这个动态的过程,简单理解,就是“谁有空,给谁分配一次迭代让它去跑!" ![]()
那么同样,dynamic也可以有一个size参数,size表示,每次线程执行完(空闲)的时候给其一次分配的迭代的数量,如果没有知道size(上面的分析),那么每次就分配一个迭代。有了前面的理解,这个size的含义是很容易理解的了。
(4)guided调度
类似于动态调度,但每次分配的循环次数不同,开始比较大,以后逐渐减小。size表示每次分配的迭代次数的最小值,由于每次分配的迭代次数会逐渐减少,较少到size时,将不再减少。如果不知道size的大小,那么默认size为1,即一直减少到1。具体是如何减少的,以及开始比较大(具体是多少?),参考相关手册的信息。
(5)runtime
runtime表示根据环境变量确定上述调度策略中的某一种,默认也是静态的(static)。
控制schedule环境变量的是OMP_SCHEDULE环境变量,其值和上面的三中类型一样了,比如:
setenv OMP_SCHEDULE “dynamic, 5”
就是schedule(dynamic,5)的含义了。