最近在学习Hadoop和HBase,现在总结一下HBase的一些基本概念,理解好后使用和开发更容易。HBase是一个分布式的、面向列的数据存储系统。它在HDFS基础上提供随机读写的功能。HBase有如下特性,没有真正的索引,自动分区,线性扩展和对于新结点的自动处理,普通商用硬件支持,容错,批处理。
1、HBase逻辑结构
行,列,列族和单元格(cell)。行是由许多列组成,那些列按列族分组。列由family:qualifier标识,qualifier可以是任意字节数组。每个列值或者cell是timestamped。这个用来存储一个值的多个版本因为它随着时间改变。
2、HBase物理结构
HBase的可伸缩性和负载均衡的基本单位是区域(region)。区域是连续范围的行存储在一起。每个区域由一个区域服务器(region server)服务,每个区域服务器在任何时间可以服务多个区域。
数据存放在存储文件叫做HFile,它是持久的、有序的和不可变的从keys到values的maps。HFile文件经常存放在HDFS,HDFS为HBase提供了可伸缩的,持久的和复制的存储层。
当数据更新的时候首先写到一个提交日志(commit log),它称为write-ahead log(WAL),然后加入内存中的memstore。如果在memstore的数据超过一个给定的最大值,它会被刷入(flush)到文件系统作为HFIle文件。
一个删除标记(delete marker)被写表示那些键已经被删除的事实。在检索过程中,这些删除标记会掩盖真正的值并隐藏它们出现在读客户端。
HBase内部保留名为-ROOT-和.META.的特殊目录表(catalog table)。它们维护着当前集群上所有区域的列表、状态和位置。-ROOT-表包含.META.表的区域列表。.META.表包含所有用户空间区域的列表。表中的项使用区域名作为键。区域名由所属的表名、区域的起始行、区域的创建时间以及对其整体进行的MD5哈希值组成。
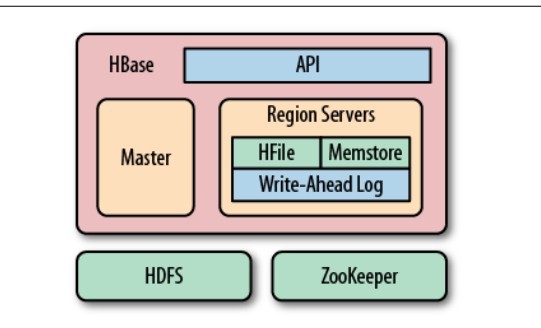
图1 Hbase结构
3、我在安装和运行HBase遇到的问题和解决方法
(1)在Ubuntu11.04下,当尝试使用hbase shell时,输入命令create 't1','f1',出现
ERROR:org.apache.hadoop.hbase.NotAllMetaRegionOnlineException:Time out错误。
解决:在/etc/hosts文件里把127.0.1.1改为127.0.0.1.在Ubuntu11.04有一个重复循环地址,移除一个解决它。
(2)运行HBase的MapReduce程序前将以下几个hbase的jar包复制到hadoop lib目录下,并且重新启动hbase与hadoop。
#cd /opt/hbase
#cp hbase-*.jar lib/zookeeper-*.jar /opt/hadoop/lib/
重启hbase与hadoop。