SQL性能优化
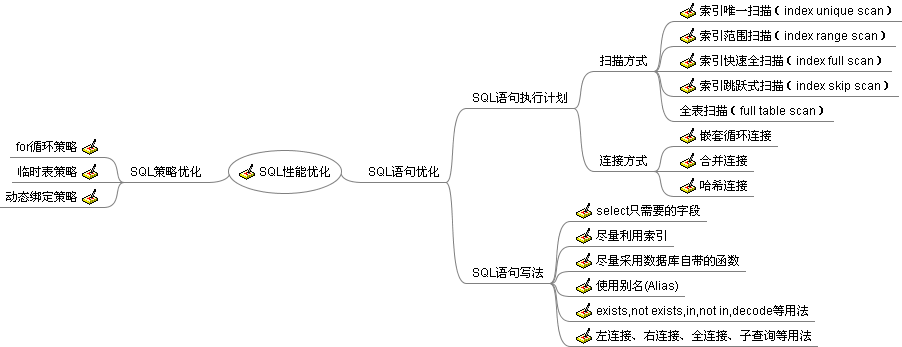
SQL性能优化,可以从两方面着手:
一、SQL语句优化;
二、SQL策略优化。
一般来说:SQL语句优化,只要清楚SQL语句常识,则可以达到;
但SQL策略优化,可能要个人积累一定的优化经验,才可以做到。
通过唯一索引查找一个数值经常返回单个ROWID。如果该唯一索引有多个列组成(即组合索引),则至少要有组合索引的引导列参与到该查询中,如创建一个索引:create index idx_test on emp(ename, deptno, loc)。则select ename from emp where ename = ‘JACK’ and deptno = ‘DEV’语句可以使用该索引。如果该语句只返回一行,则存取方法称为索引唯一扫描。而select
ename from emp where deptno = ‘DEV’语句则不会使用该索引,因为where子句种没有引导列。如果存在UNIQUE 或PRIMARY KEY 约束(它保证了语句只存取单行)的话,Oracle经常实现唯一性扫描。
使用一个索引存取多行数据,同上面一样,如果索引是组合索引,而且select ename from emp where ename = ‘JACK’ and deptno = ‘DEV’语句返回多行数据,虽然该语句还是使用该组合索引进行查询,可此时的存取方法称为索引范围扫描。在唯一索引上使用索引范围扫描的典型情况下是在谓词(where限制条件)中使用了范围操作符(如>、<、<>、>=、<=、between)
使用index rang scan的3种情况:
(a) 在唯一索引列上使用了range操作符(> < <> >= <= between)。
(b) 在组合索引上,只使用部分列进行查询,导致查询出多行。
(c) 对非唯一索引列上进行的任何查询。
与全表扫描对应,也有相应的全Oracle索引扫描。在某些情况下,可能进行全Oracle索引扫描而不是范围扫描,需要注意的是全Oracle索引扫描只在CBO模式下才有效。 CBO根据统计数值得知进行全Oracle索引扫描比进行全表扫描更有效时,才进行全Oracle索引扫描,而且此时查询出的数据都必须从索引中可以直接得到。
Index skip scan 仅是在组合索引的引导列,即第一列没有指定,并且非引导列指定的情况下。
NESTED LOOPS
MERGE JOIN
HASH JOIN
一、减少了数据量;
二、减少了检索的时间。
oralce常用索引类型:唯一索引、函数索引、组合索引、位图索引
索引之所以快,是因为索引块数据量不会太大,而且,记录了真正数据的物理位置。
数据库自带的函数,都是做过优化的,所以,比自己编写的函数,要好很多。
当在SQL语句中连接多个表时, 请使用表的别名并把别名前缀于每个Column上。这样一来,就能够减少解析的时间并减少那些由Column歧义引起的语法错误。
在许多基于基础表的查询中,为了满足一个条件,往往需要对另一个表进行联接。在这种情况下,使用EXISTS(或NOT EXISTS)通常将提高查询的效率。在子查询中,NOT IN子句将执行一个内部的排序和合并。无论在哪种情况下,NOT IN都是最低效的 (因为他对子查询中的表执行了一个全表遍历)。为了避免使用NOT IN ,我们能够把他改写成外连接(Outer Joins)或NOT EXISTS
左、右连接,有两种写法,可以用join方式,也可以用(+)的表示法。
由于什么时候使用索引,什么时候不使用索引。并不是绝对的。与查询的数据量大小有关系。如果要查询大量的数据,那么查询优化器,将可能采用全表扫描的方式进行。
当然,也有其它的方式来限制一定要用到索引,那就是hits方法。
例:/* + index(table,index)*/
但for循环策略,如果循环次数太多,反而,会对性能造成下降的问题。主要是因为IO访问过于频繁了(主要是因为循环访问,一般会导致单块数据读数,从而,增加了IO的访问)。
如果要查询的关联表很大(例:千万级的数据),不妨试试采用临时表策略,先把小的集合查询出来,然后,再与大的集合关联起来。
一般临时表,可以采用session表实现。但要注意:这里的session,指的是连接上数据库产生的session,并非sql语的session。
所以,有机会,同一个人连续操作同一个操作时,出现session表里的旧数据,还没有删除掉的情况。因此,一般,为了保证数据的完整性,
会在查询之前,先把session表里的数据,删除掉。再继续操作。
同时,session表,在oralce数据库的环境下,有时,会出现一些很奇怪的数据问题,例:多了很多的数据,或者只显示极少的数据。
如出现类似问题,一般调整SQL语句的写法,就可以解决问题。
动态绑定策略,主要为了减少sql语句解析时间。
当然,动态绑定,并不一定是件好事,因为是动态绑定,会导致执行计划,在第一次运行后,就固定下来,不会发生变化。
所以,在相同的sql语句,但查询条件所带来的数据量不同时,就会有问题。例:本应该直接采用全表扫描,会快,结果却是采用索引扫描方式。