http://www.cnblogs.com/Gavin_Liu/archive/2009/03/07/1405029.html
一.JavaCC简介
JavaCC(Java Compiler Compiler)是一个用JAVA开发的最受欢迎的语法分析生成器。这个分析生成器工具可以读取上下文无关且有着特殊意义的语法并把它转换成可以识别且匹配该语法的JAVA程序。JavaCC可以在Java虚拟机(JVM)
V1.2或更高的版本上使用,它是100%的纯Java代码,可以在多种平台上运行,与Sun当时推出Java的口号"Write
Once Run Anywhere"相一致。JavaCC还提供JJTree工具来帮助我们建立语法树,JJDoc工具为我们的源文件生成BNF范式(巴科斯-诺尔范式)文档(Html)。
二.JavaCC的特点
JavaCC是一个用Java语言写的一个Java语法分析生成器,它所产生的文件都是纯Java代码文件,JavaCC和它所自动生成的语法分析器可以在多个平台上运行。
下面是JavaCC的一些具体特点:
1.
TOP-DOWN:JavaCC产生自顶向下的语法分析器,而YACC等工具则产生的是自底向上的语法分析器。采用自顶向下的分析方法允许更通用的语法(但是包含左递归的语法除外)。自顶向下的语法分析器还有其他的一些优点,比如:易于调试,可以分析语法中的任何非终结符,可以在语法分析的过程中在语法分析树中上下传值等。
2.
LARGE USER COMMUNTIY:是一个用JAVA开发的最受欢迎的语法分析生成器。拥有成百上千的下载量和不计其数是使用者。我们的邮件列表(https://JavaCC.dev.java.net/doc/mailinglist.html
)和新闻组(comp.compilers.tools.JavaCC)里的参与者有1000多人。
3.
LEXICAL AND GRAMMAR SPECIFICATIONS IN ONE FILE:词法规范(如正则表达式、字符串等)和语法规范(BNF范式)书写在同一个文件里。这使得语法易读和易维护。
4.
TREE BUILDING PREPROCESSOR: JavaCC提供的JJTree工具,是一个强有力的语法树构造的预处理程序。
5.
EXTREMELY CUSTOMIZABLE:JavaCC提供了多种不同的选项供用户自定义JavaCC的行为和它所产生的语法分析器的行为。
6.
CERTIFIED TO BE 100% PURE JAVA:JavaCC可以在任何java平台V1.1以后的版本上运行。它可以不需要特别的移植工作便可在多种机器上运行。是Java语言”Write
Once, Run Everywhere”特性的证明。
7.
DOCUMENT GENERATION:JavaCC包括一个叫JJDoc的工具,它可以把文法文件转换成文本本件(Html).
8.
MANY MANY EXAMPLES:JavaCC的发行版包括一系列的包括Java和HTML文法的例子。这些例子和相应的文档是学习JavaCC的捷径。
9.
INTERNATIONALIZED:JavaCC的词法分析器可以处理全部的Unicode输入,并且词法规范何以包括任意的Unicode字符。这使得语言元素的描述,例如Java标识符变得容易。
10.
SYNTACTIC AND SEMANTIC LOOKAHEAD SPECIFICATIONS:默认的,JavaCC产生的是LL(1)的语法分析器,然而有许多语法不是LL(1)的。JavaCC提供了根据语法和语义向前看的能力来解决在一些局部的移进-归约的二义性。例如,一个LL(k)的语法分析器只在这些有移进-归约冲突的地方保持LL(k),而在其他地方为了更好的效率而保持LL(1)。移进-归约和归约-归约冲突不是自顶向下语法分析器的问题。
11.
PERMITS EXTENDED BNF SPECIFICATIONS:JavaCC允许拓展的BNF范式——例如(A)*,(A)+等。拓展的BNF范式在某种程度上解决了左递归。事实上,拓展的BNF范式写成A
::= y(x)* 或 A ::= Ax|y更容易阅读。
12.
LEXICAL STATES AND LEXICAL ACTIONS:JavaCC提供了像lex的词法状态和词法动作的能力。
13.
CASE-INSENSITIVE LEXICAL ANALYSIS:词法描述可以在整个词法描述的全局域或者独立的词法描述中定义大小写不敏感的Tokens。
14.
EXTENSIVE DEBUGGING CAPABILITIES:使用选项DEBUG_PARSER, DEBUG_LOOKAHEAD,
和 DEBUG_TOKEN_MANAGER,使用者可以在语法分析和Token处理中使用深层次的分析。
15.
SPECIAL TOKENS:Tokens可以在词法说明中被定义成特殊的Tokens从而在语法分析的过程中被忽略,但这些Tokens可以通过工具进行处理。
16.
VERY GOOD ERROR REPORTING:JavaCC的错误提示在众多语法分析生成器中是最好的。JavaCC产生的语法分析器可以清楚的指出语法分析的错误并提供完整的诊断信息。
三.JavaCC的获取
JavaCC是java世界里一个类似lex和yacc的工具,JavaCC也是一个免费可以获取的通用工具,它遵循BSD
License(Berkeley Software Distribution (BSD) License),你可以自由的使用它。它可以在很多JAVA相关的工具下载网站下载,当然,要想获得最新的版本JavaCC,还是在官网上下载比较好https://JavaCC.dev.java.net/。点击官网后可进入如下的界面进行下载:

JavaCC所占的磁盘空间比起lex和yacc更大一些,里面有标准的文档和examples。相对lex和yacc来说,JavaCC做得更人性化,更容易一些。

四.JavaCC的安装和使用
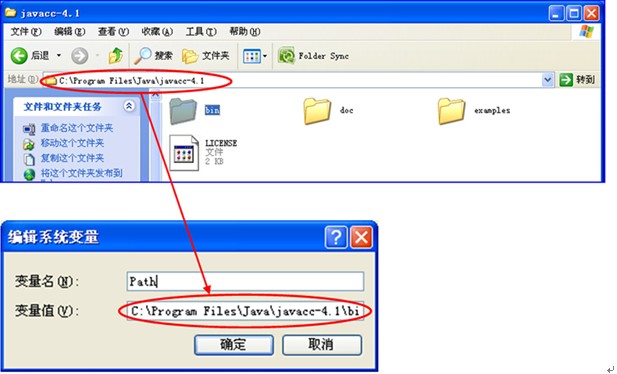
解压下载后的文件JavaCC-4.1.zip,将其中的bin文件夹的路径添加到环境变量path中,如下图所示:
启动“运行”(快捷键win+R),输入cmd
——>确定,在提示符中输入JavaCC,如看到如下画面,表明JavaCC安装成功。(前提是已经安装了JDK)

五.JavaCC plug-in的安装和使用
JavaCC plug-in是一个用于辅助JavaCC应用程序开发的Eclipse插件.JavaCC plug-in可以在如下链接中下载http://www.easyeclipse.org/site/plugins/JavaCC.html
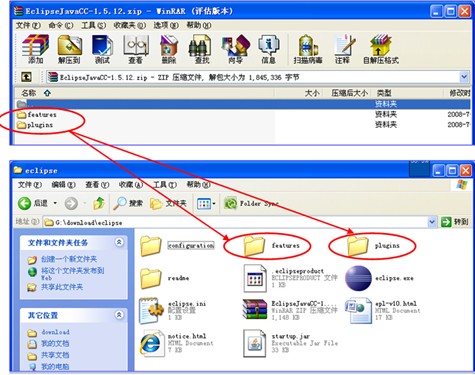
将下载文件解压得到的两个文件夹复制到Eclipse相应的文件夹中,该插件即添加完成。
六.JavaCC的原理(原理分析+个人实践心得)
总体来说,JavaCC主要有以下功能:
l JavaCC用来处理语法文件(jj)生成解析代码
l JJTree
用来处理jjt文件,生成树节点代码和jj文件
l JJDoc
根据jj文件,生成文本本件(Html)
下面将根据我个人的理解(个人观点,仅供参考),结合Sun给的Examples和自己利用Javccc编写的CMM语言的词法分析和语法分析文件,逐一阐述上面的两个个功能。(由于时间的原因,JJDoc没有深入的学习,这里暂不涉及)
JavaCC
JavaCC是一个词法分析生成器和语法分析生成器。词法分析和语法分析是处理输入字符序列的软件组件,编译器和解释器协同词法分析和语法分析来解码程序文件。词法分析器可以把一连串的字符序列划分成一个一个的叫做“Token”的子序列,同时它也可以把这些Token分类。这些Token序列将会传送给语法分析器以供其决定程序的结构。
JavaCC的输入文件是一个词法和语法的规范文件,其中也包括一些动作的描述,它的后缀应该是jj。现在看一下JavaCC-4.1"examples"SimpleExamples这个文件夹下的Simple1.jj这个文件。
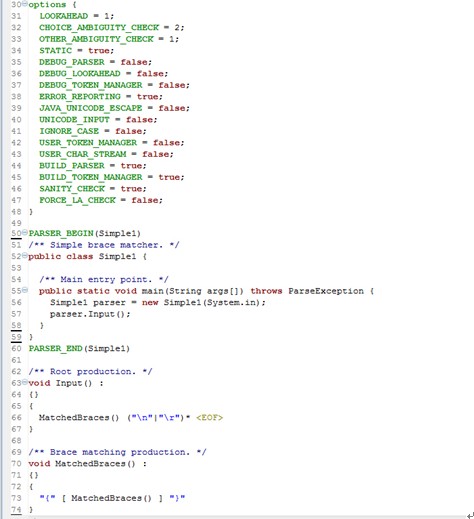
这是一个简单的JavaCC语法来识别一系列的“{”和后面的相同数量的“}”,之后跟着0个或多个行终结符,最后是文件的结尾。
下面是合法的字符串例子:
"{}" , "{{{{{}}}}}" , etc.
下面是不合法的字符串例子:
"{{{{" , "{}{}" , "{}}" , "{{}{}}" , etc.
这个语法文件以一些JavaCC所提供的Options的参数设置开始。在这个例子中,Options的参数都是它们的默认值。因此,这些参数实际上是不需要的。程序员甚至可以完全忽略Options这一部分,或者省略其中的一个或多个Options的参数,详细的关于Options的参数设置的问题请参考JavaCC的文档。
接下来的是一个处在”PARSER_BEGIN(name)”和”PARSER_END(name)”中间的编译单元。这个编译单元可以是任意的复杂。在这个编译单元中唯一的限制就是它必须定一个一个叫”name”的类——与PARSER_BEGIN和PARSER_END的参数的相同。这个”name”被用作语法分析产生器生成的java文件的前缀。
在上面的例子中,语法分析器产生的类包括一个主程序。这个主程序通过调用使用一个类型为java.io.InputStream的参数的构造函数创建了一个Simple1的对象。
这个主程序调用文法的非终结符。所有的非终结符在JavaCC的语法分析器中的地位是平等的,因此,一个非终结符可以分析有关的任何一个该文法的非终结符。
下面是一系列的产生式。在这个例子中,有两个被分别定义为非终结符Input和MatchedBraces的产生式。在JavaCC的语法中,非终结符的编写和实现与Java中的方法是一致的。当一个非终结符位于一个产生式的左边的时候,它被认为将要被声明,它的句法和Java的相一致。当它在产生式的右边的时候,它的用途与Java中的方法调用相似。
每一个产生式定义它的左边的非终结符以一个冒号(:)结尾。之后紧跟着的是一些在花括号({})里面的声明和语句,它们将作为产生方法的普通声明和语句。(在上面的例子中,因为没有声明,所以是空的{})这之后是一系列的在闭合的花括号里的拓展语句。
JavaCC中的词法的Tokens是简单的字符串如"{", "}", ""n", ""r",或者是复杂的正则表达式。在上面的例子中,有一个正则表达式<EOF>,当它被匹配的时候意味着文件的结束。所有的正则表达式都在封闭的尖括号(<>)内。
上面列子的第一个产生式的非终结符”Input”拓展到非终结符”MethodBraces”,之后跟着0个或多个行终结符(""n"
或 ""r"),然后这文件的结束符。
上面列子的第二个产生式的非终结符” MethodBraces”拓展到token”{”,之后跟着可选择嵌套的MethodBraces,之后跟着一个token”}”。在JavaCC输入文件中,方括号[…]表示…是可选的。
[…]同样可以写成(…)?。这两种形式是相等的。其他可能会在拓展式中出现的结构是:
e1 | e2 | e3 | ... : 选择 e1, e2, e3, etc.其中之一
( e )+ : e出现一次或多次
( e )* : e出现零次或多次
上面的结构可以相互嵌套,如:(( e1 | e2 )* [ e3 ] ) | e4
以上是对Simple1.jj的简单介绍,在介绍我自己写的CMM语言的词法分析和语法分析程序之前,先简单介绍一下CMM语言的基本知识。
CMM语言为C语言的一个子集:
n 语言结构:顺序结构(赋值语句、输入、输出)、选择语句(if-else)、循环结构(while)。这些语句结构和C语言的结构一样,允许嵌套。
n 表达式局限于关系表达式和算术表达式,运算的优先级为:算术运算、关系运算,并服从左结合规则。
n 算术表达式包括整数和实数上的运算、变量以及“()”、“*”、“+”、“-”、“/”,运算符的优先级顺序为:“()”大于“*”和“/”大于“+”和“-”。
n 关系运算符包括:“<”、“==”、“<>”。
n 一条语句以“;”结束;程序由一条语句或者由“{”和“}”嵌套表达的复合语句。
n 注释放在“/*”“ */ ”之间,支持多行注释。
n 支持数组运算,数组的下标必须是正整数,使用“[”和“]”表示数组下标。
n 变量的使用之前需要先声明,声明的方式和C语言一样。
|
保留字 |
特殊符号 |
其他 |
|
If |
+ |
十进制的整数与实数 |
|
else |
- |
|
|
while |
* |
|
|
read |
/ |
标识符(由数字、字母和下划线组成的串,但必须以字母开头、且不能以下划线结尾的串) |
|
write |
= |
|
|
int |
< |
|
|
real |
== |
|
|
|
<> |
|
|
|
( |
|
|
|
) |
|
|
|
; |
|
|
|
{ |
|
|
|
} |
|
|
|
/* |
|
|
|
*/ |
|
|
|
[ |
|
|
|
] |
|
下面来看一下我们利用Eclipse的JavaCC插件来写我们自己的JJ文件(关于CMM的)。
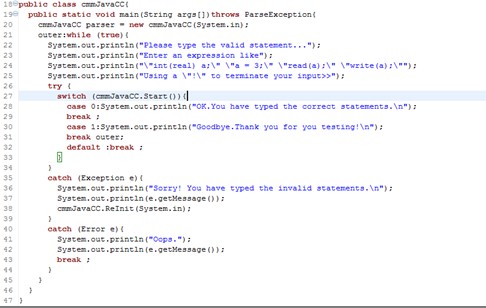
当我们导入或新建一个JJ文件时,Eclipse会自动根据”name”(上面提到过的)生成7个java文件。如下图:

打开cmmJavaCC文件可以发现,Eclipse已经为我们创建好了相应的类和主函数,我们只需要在这里修改一下个别的提示语句(System.out.prinln(…))就Ok了。顺便说一句,如果大家觉得自己写的语句的缩进没有调整好,在Eclipse里直接按Ctrl+Shift+F,可以自动调整缩进,很方便的哦。我编写的是下面的提示语句:
下面将详细描述我的词法分析器。我的词法分析器分为两个主要部分,即SKIP
和 TOKEN,关于这两个的详细介绍可以查阅Sun提供的帮助文档,这里就不再详细介绍了。
下面看一下我的关于SKIP的编写,如下图:

SKIP里的内容也就是我们所生成的词法分析器里自动跳过的内容,请注意红色框里面的内容,该内容是指跳过我们通常文件中的//和/**/的注释。(还好这两个正则表达式是系统自动生成的,不然不知道自己要分析到什么时候才能把这个搞定)
接下来就要定义我的关于CMM的TOKEN,在我们的这个任务中,一共有这么几类TOKEN:
CMM语言的关键字
CMM语言中出现的各种符号
表示标识符、整数、实数的Token
具体代码如下:
TOKEN:/*定义关键字*/
{
<IF:"if">
|
<ELSE:"else">
|
<READ:"read">
|
<WRITE:"write">
|
<WHILE:"while">
|
<INT:"int">
|
<REAL:"real">
}
TOKEN:/*
定义整数 */
{
<INTEGER_LITERAL:["1"-"9"](<DIGIT>)*>
}
TOKEN:/*
定义实数 */
{
<REAL_LITERAL:(<DIGIT>)+
| (<DIGIT>)+"."
| (<DIGIT>)+"."(<DIGIT>)+
|
"."(<DIGIT>)+>
}
TOKEN:/*定义数字*/
{
<#DIGIT:["0"-"9"]>
}
TOKEN:/*定义符号*/
{
<UNDERSCORE:"_">
|
<COMMA:",">
|
<SEMICOLON:";">
|
<COLON:":">
|
<LEFTPARENTHESES:"(">
|
<RIGHTPARENTHESES:")">
|
<EQUAL:"=">
|
<PLUS:"+">
|
<MINUS:"-">
|
<TIMES:"*">
|
<DIVIDE:"/">
}
TOKEN:/*
定义标识符 */
{
<IDENTIFIER:<LETTER>
|
<LETTER>(<LETTER>
|
<DIGIT>
|
<UNDERSCORE>)*(<LETTER>
|
<DIGIT>)+>
|
<#LETTER:["a"-"z",
"A"-"Z"]>
}
下面在进行正式的关于CMM语言的语法规则的描述之前,先看一下我画的几个关于CMM语言的语法描述图:
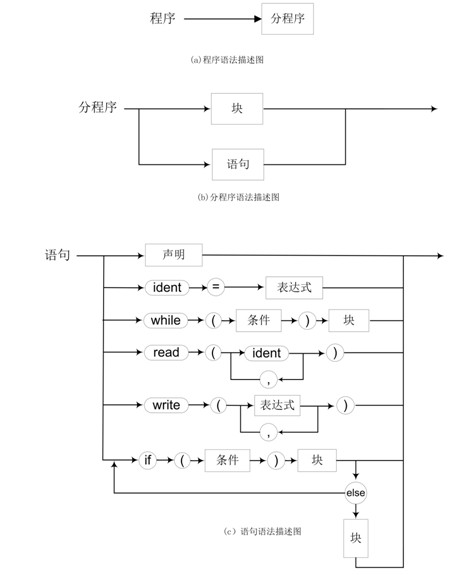
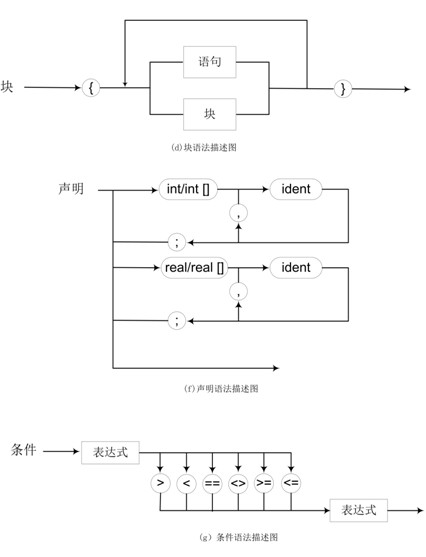
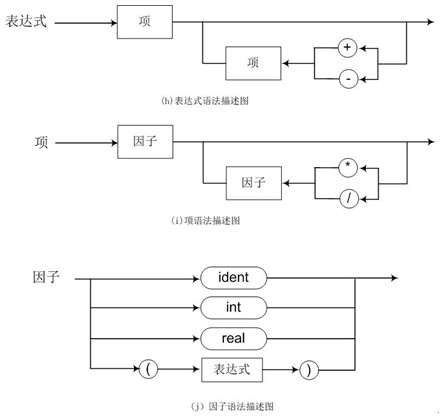
上面的语法图描述语法规则比较直观、易读,语法图中用椭圆和圆圈中的英文字或字符表示终结符,用长方形内的中文字表示非终结符。
下面的关于正式的语法解析,就是完全依赖于上面的语法描述图来进行展开的。
要记住这样一句话:“JavaCC把文法识别完全地做到了函数过程中”,这个思想将贯穿在下面的代码之中。
首先第一个函数是start()函数,
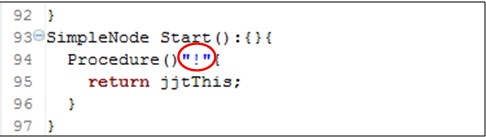
这是我们整个程序的“切入点”,在上面的main()函数中,由
SimpleNode n = cmmJJTree.Start();
调用。
下面进入Procedure()这个函数,由它来进行语法的分析。注意上图的红色线圈,“!”表示当用户最后的输入是!时,程序运行进行语法分析,这里可以改成大家喜欢的字符或字符串,有大家的个人喜好而定。
根据上面(b)分程序的语法描述图,在进入Procedure()之后,程序有两种选择,要么进入Block(),要么进入Statement()函数,又因为用户可以输入多条语句,所以需要一个闭包将里面的内容包起来,所以Procedure()内主体应该是下面的代码:
下面再根据上面(c)语句的语法描述图,来分析一下Statement()中的具体内容。
在我们的CMM语言中,一共有6中语句,它们分别是:
变量的声明语句
变量的赋值语句
read语句