关于yahoo s4有官方网站:http://s4.io/, 也可以查看英文paper: S4:Distributed Stream Computing Platform, 中文翻译:http://wenku.baidu.com/view/fdfa4ef7f61fb7360b4c653a.html,
不过看完paper以后再看一下这篇文章能够让你对s4理解的更好些。
下面内容来源于:http://www.programmer.com.cn/5304/
本文是作者在充分阅读和理解Yahoo!最新发布的技术论文《S4:Distributed
Stream Computing Platform》的基础上,所做出的知识分享。
S4是Yahoo!在2010年10月开源的一套通用、分布式、可扩展、部分容错、具备可插拔功能的平台。这套平台主要是为了方便开发者开发处理流式数据(continuous unbounded streams of data)的应用。项目官方网站为:http://s4.io/。同时,S4的开发者也发表了一篇技术论文《S4:Distributed Stream Computing Platform》来介绍S4的设计。下面我们就来学习这篇论文。
开发动机
“We designed this engine to solve real-world problems in the context of search applications that use data mining and machine learning algorithms.” … “To process user feedback, we developed S4, a low latency, scalable stream processing engine.”
Yahoo!之所以开发S4系统,主要是为了解决它现实的问题:搜索广告的展现。搜索广告是当前各大搜索引擎的主要收入来源,用户发出查询请求,搜索引擎在返回正常结果的同时也会返回相关广告,而广告是按照点击付费。为了在最好的位置,放置最相关(也就是用户最有可能点击)的广告,各大搜索引擎使用了大量的数据挖掘和机器学习算法来进行相关性计算,以便提高收入,满足用户需求。其中很重要的一点就是要不断分析用户的点击反馈,以便捕获用户的行为。S4最初主要还只是用来处理用户的点击反馈。
“The streaming paradigm dictates a very different architecture than the one used in batch processing. Attempting to build a general- purpose platform for both batch and stream computing would result in a highly complex system that may end up not being optimal
for either task.”
那么Yahoo!为什么没有选择Hadoop来处理呢? MapReduce系统主要解决的是对静态数据的批量处理,即当前的MapReduce系统实现启动计算时,一般数据已经到位了(比如保存到了分布式文件系统上)。
而流式计算系统在启动时,一般数据并没有完全到位,而是源源不断地流入,并且不像批处理系统重视的是总数据处理的吞吐,而是对数据处理的latency,即希望进入的数据越快处理越好。
当然,现在也有很多基于Hadoop系统来处理流式数据。一般有以下几种方式。
- Micro-batchinMapReduce:就是把流式的数据按照时间或者大小形成小的静态数据,然后定期启动MapReduce来计算。
- Continuous MapReduce:Hadoop Online(http://www.eecs.berkeley.edu/Pubs/TechRpts/2009/EECS-2009-136.html)通过实现作业内的数据传输Pipeline和作业间的数据传输Pipeline,可以实现online aggregation和continuous queries。当前MapReduce模型中,只有Map中间结果完全产生后,Reduce才会过来拖数据,等所有Map数据都拖成功后,才能计算。Hadoop Online实现了Map到Reduce间的数据Pipeline,使得可以在Map产生部分数据后,就可以送到Reduce端,以便Reduce可以提前或者定期计算。
- Dynamic add input:百度的一种实现,用来解决计算时数据还没有到位的问题。作业可以在数据还没有完全到位的情况下启动,当新数据累积到一定量时,通过一个命令行接口,向运行中的作业动态增加新的输入。通过这种方式,大大减少了处理大数据作业时等待数据到位的时间,在依次执行多个作业时,也会有时间收益。
在论文中,对类似于第一种的方式,分析了它的缺点。如果将数据流切成较小的data segment,就会增加启动作业的overhead,同时使得维护segment之间的依赖关系变得更加复杂;但如果切得较大,那么处理的latency就会比较长。
随着大量实时应用的发展,比如实时搜索、实时交易系统、实时欺骗分析、实时监控、社交网络等,都需要一个高度可扩展的流式计算解决方案。不同于原来的流式计算系统,S4主要解决的是高数据率和大数据量的流式处理。
设计假设和目标
为了简化设计,S4给出了下面的假设。
Lossy failover is acceptable,即一旦一个节点失败,会failover到另一个standby节点,但是会丢失原节点的内存状态。这也是为什么说S4是一个部分容错的系统。
节点不能动态增加和减少。
设计目标包括以下几个方面。
- 简单的编程接口。
- 高可用+高可扩展。
- 尽力避免Disk IO,而要尽量使用Local Memory,以便减少处理latency。
- 使用去中心化和对称架构,所有的节点的责任相同,方便部署和维护。
- 功能可插拔,使得平台通用化的同时,做到可以定制化。
- 设计要科学、易用和灵活。
S4的设计大量借鉴了I BM的Stream Processing Core(SPC)中间件的设计。只是 SPC采用的是Subscription Model,而S4结合了 MapReduce和Actors Model。
Event Stream
一个Stream是Events的序列流。每个Event是一个(K,A)数据,通过EventType来标示其类型。K、A分别表示这种类型的Event的keys和attributes。key和attribute都是tuple-valued,即key=value这种元组值。下面给出一个event的例子:
EV:ClickLog → event type
KEY:product=“search”, type=”online” → keys
VAL: userid=”123”, ip=”10.0.0.0”, cookieid=”3” → attributes
Processing
Elements
Processing Element(PE)是S4中的基本运算单元。一个PE通过下面四个组件来表示。
- functionality:实现PE的Java类和相关配置来定义。
- types of events:处理的event type。
- key:关心哪种key。
- Key的值:关心的key值是多少。

每个PE只负责处理自己所关心的eventtype,并且只处理自己所对应的key值的event。PE处理后可能输出一个或多个event。当平台处理一个key值时,会先检查相应的PE是否已经存在,如果不存在,会先初始化相应的PE,然后交由这个PE进行处理。举例如图1所示。
在图1中,PE2负责处理相应的单词事件(WordEvent),主要逻辑是统计所关心单词的个数,然后输出给下游的PE。PE2所关心的eventtype为WorkEvent,所关心的key为word,所关心的key值为“said”。假如又来了一个WordEvent,key为word=“listen”,那么这个事件就不是PE2所关心的,所以平台可能会为“listen”值启动一个新的PE来处理。
有一类特殊的PE,即keylessPE(没有key和key值),这些PE会接收相应eventtype的所有event进行处理。这类PE主要用来作为S4cluster的输入层(InputLayer),即外围应用会产生相应的event(keylessevent),将这些event发到任何一个节点。而S4cluster中的每个节点都会启动一个keylessPE,这些PE做简单的输入处理后,转化为keyedevent,交给集群中的其他PE类型进行处理。
PE的逻辑主要由应用程序员来开发。
Processing
Node
Processing Node是一个逻辑节点,负责监听消息的到来,对消息进行处理,然后通过Communication Layer将event在集群中分发。S4主要依据上面提到的eventtype和key/key值,对key值求hash,在集群中进行分发。关注的key集合通过配置文件来得到。对于需要处理的event,会交给PN中的Processing Element Container(PEC),然后PEC调用相应的PE进行处理。PN功能框如图2所示。
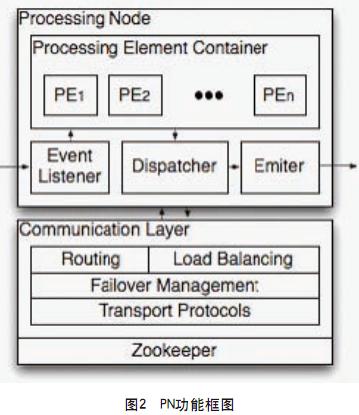
通过图2的设计,可以保证,对应于相同event type,key和key值的event一定会被路由到对应的PN。
底下的Communication Layer和Zookeeper共同完成了集群管理和自动failover功能。
编程模型
应用的主要任务就是实现一些相应的PE。PE一般提供如下接口供应用实现。
- processEvent():用来处理每一个event,然后修改相应的内部状态。
- output():框架会按照应用的配置定期的调用,以便向下游输出其他event。应用可以使用两种输出配置,一个是隔多长时间输出一次;另一个是隔多少event个数输出一次。
其他
论文中给出了一个Word Count的例子,大家可以仔细研究一下。在性能测试部分,论文总结了将S4应用到实际的CTR(Click-Through Rate)预估中的效果。在应用举例中,给出了S4在在线参数优化的应用。
随着大量实时计算需求的增加,分布式流式计算将会成为分布式计算的下一个主要研究重点,将会成为类似Hadoop这类MapReduce框架的有力补充。这一方向的工作还处在初级发展阶段,大家需要多加关注。
作者简介
马如悦,百度基础架构部高级工程师,自2007年加入百度,一直从事分布式存储系统和分布式计算系统的设计和开发工作。对Hadoop有较深入的研究,一直积极活动在Hadoop开源社区。