注:最近在读《c#高级编程(第五版)》,以下内容是我根据读书笔记整理而成。
引言
尽管运行库负责为程序员处理大部分内存管理工作,但程序员仍必须理解内存管理的工作原理,了解如何处理未托管的资源。
一、运行库如何在堆栈和堆上分配空间
c#编程的一个优点就是程序员无需担心具体的内存管理,因为垃圾收集器会处理所有的内存清理工作。但是如果要编写高效的c#代码,就必须理解后台发生的事情。
Windows使用一个系统:虚拟寻址系统,该系统把程序可用的内存地址隐射到硬件内存中的实际地址上,这些任务完全由Windows在后台管理,其实际结果是32位的处理器的每个进程都可以使用4GB的内存。要访问存储在内存中某个空间中的某个值,就需要提供表示该存储单元的数字,在高级语言中如c#,编译器负责把人们可以理解的变量名转换为处理器可以理解的内存地址。
在进程的虚拟内存中,有一个区域称为堆栈。堆栈存储不是对象成员的值数据类型。在调用一个方法时,也使用堆栈来存储传递给方法的所有参数复本。需要注意c#中变量的作用域,如果变量a在变量b之前进入作用域,b就会先退出作用域,如下面的代码:
{
int a;
{
int b;
}
}
代码中先声明a,然后在代码内部声明b,当内部的代码块终止,b退出作用域,最后a退出作用域,所以b的生命周期完全包含在a的生存期中。在释放变量时,其顺序总是与给他们分配内存的顺序相反,这就是堆栈的工作原理。
我们不知道堆栈在地址空间的什么地方,这些信息在进行C#开发是不需要知道的。堆栈指针(操作系统维护的一个变量)表示堆栈中下一个自由空间地址。程序第一次运行时,堆栈指针指向为堆栈保留的内存块的末尾。堆栈实际上是向下填充的,即从高内存地址向低内存地址填充,当数据入栈后,堆栈指针会自动随之调整,保证始终指向下一个自由空间,如下图所示,该图中堆栈指针800000的下一个自由空间是地址799999.

我们看以下代码:
{
int a = 10;
double b = 3000.0;
}
上面的代码在运行时会告诉编译器,需要一些内存的存储单元存储一个整数和一个双精度浮点数,这些存储单元会分别分配给a和b,声明每个变量的代码表示请求访问这个变量,闭合花括号表示这两个变化量出作用域的地方
如果使用上图所示的堆栈才存储a和b,因为a是整形变量需要4个字节存储,所以a的赋值10放在799996~799999上。堆栈指针对自动下移4个字节的单元,指向位置799996,即下一个自由空间为799995.double类型的变量b要占用8个字节,所以堆栈指针再下移8个字节单元。
堆栈有非常高的性能,但对于所有的变量并不够灵活。在堆栈存储的变量中,变量的生存期必须嵌套,在许多情况下,这种要求过于苛刻。通常我们希望使用一个方法分配内存,来存储一些数据,并在方法退出后的很长一段时间内数据有效。这种情况可以使用new运算符来请求存储空间,此时就要用到托管堆。
托管堆和C++下的堆不用,因为它是在垃圾收集器的控制下工作的,其与传统的堆相比具有显著性能优势。
托管堆(简称堆)是进程的可用4GB中的另一个内存区域。下面代码说明堆的工作原理和如何为引用数据类型分配内存。
void DoWork()
{
Customer arable;
arable = new Customer();
}
上面代码中,假定存在类Customer。
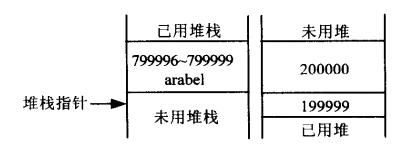
首先,声明了一个Customer类型的引用arabel,在堆栈上给这个引用分配存储空间,注意这只是引用而不是实际的Customer对象。arabel引用占用了4个字节的空间,包含了存储Customer对象的地址(需要4个字节把内存地址表示为0到4GB之间的一个整数值)。
arabel = new Customer();
这行代码首先在堆上分配内存,以存储Customer的实例(一个真正的实例,不只是一个地址),然后把变量arabel的值设置为分配给新Customer对象的内存地址。为了在堆上找到一个存储新Customer对象的存储位置,.NET运行库在堆中搜索,选取第一个未使用的、32字节(这里假定Customer对象占用32字节存储)的连续块。为了讨论方便,假定其地址是200000,arabel引用占用堆栈中的799996-7999999位置,在实例化arabel对象前,内存的内容如下图所示:
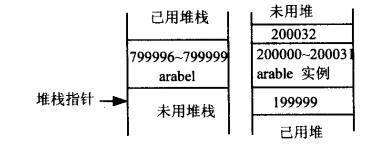
给Customer对象分配内存后,内存内容应如下图所示,注意,与堆栈不同,堆上的内存是向上分配的,所以自由空间在已用空间的上面。
二、垃圾收集的工作原理
在垃圾收集器运行时,会在堆中删除不再引用的所有对象。在完成删除后,堆会立即把对象分散开来,与已经释放的内存混合在一起,如下图所示:

如果托管的堆也是这样,在其上给新的对象分配内存就会难以处理,因为运行库必须搜索整个堆,才能找到足够大的内存块来存储每个新对象。但是,垃圾收集器不会让堆处于这种状态。只要它释放了能释放的所有对象,就会压缩其它对象,把它们都移动回堆的端部,再次形成一个连续的块。在移动对象时,这些对象的所有引用都需要用正确的新地址来更新,但垃圾收集器也会处理更新的问题。
垃圾收集器的这个压缩操作是托管的堆与旧未托管的堆的区别所在。使用托管的堆,就只需要读取堆指针的值即可,而不是搜索链接地址列表,来查找要一个地方来放置新数据。因此在.NET下实例化对象要快得多。有趣的是,访问它们的速度也比较快,因为对象会压缩到堆上相同的内存区域,这样需要交换的页面较少。微软相信,尽管垃圾收集器需要做一些工作,如压缩堆,修改它移动的所有对象的引用,导致性能降低,但这些性能会得到弥补。
垃圾收集器不知道如何释放未托管的资源(例如文件句柄、网络连接和数据库连接)。托管类在封装对未托管资源的直接或间接引用时,需要定制专门的规则,确保未托管的资源在回收类的一个实例时释放。
三、如何使用析构函数和System.IDisposable接口来确保正确释放未托管的资源
在定义一个类时,可以使用两种机制来自动释放未托管的资源。
(1) 声明一个析构函数
(2) 在类中执行System.IDisposable接口
在调用垃圾收集器删除对象之前,可以调用析构函数。
析构函数看起来类似于一个方法,与包含类同名,但前面加上(~)。它没有返回值,没有参数,没有访问修饰符,下面是一个例子:
Class MyClass
{
~MyClass()
{
}
}
C# 编译器在编译析构函数时,会隐式地把析构函数的代码编译为Finalize()方法对应的代码,确保执行父类的Finalize()方法。下面列出了编译器为~MyClass()析构函数生成的IL的对应的c#代码:
protected override void Finalize()
{
try
{}
finally
{base.Finalize();}
}
C#析构函数的问题是它们的不确定性,由于垃圾收集器的工作方式,无法确定析构函数何时得到执行,所以不能在析构函数中放置需要在某一时刻运行的代码,也不应使用能以任意顺序对不同类实例调用的析构函数。另外一个问题是c#析构函数的执行会延迟对象最终从内存删除的时间。有析构函数的对象需要垃圾收集器调用两次才真正删除对象。另外,运行库使用一个线程来执行所有对象的Finalize()方法。如果频繁使用析构函数,而且它们执行时间的清理任务,对性能的影响就会非常显著。
在c#中推荐使用System.IDisposable接口来替代析构函数。IDisposable声明了一个方法Dispose(),它不带参数,返回void,MyClass的方法Dispose()的执行代码如下:
class MyClass : IDisposabale{
public void Dispose()
{}
}
Dispose()的执行代码显示释放由对象直接使用的所有非托管资源,为对象释放未托管资源提供精确的控制。
我们使用一个对象后可以调用这个对象的Dispose()方法来释放未托管的资源。但是如果在处理过程中出现异常,就无法释放这个对象使用的资源,所以应该使用try块来编写,在finally的代码块对资源进行释放。C#提供了一种语法,可以确保在执行IDisposable接口的对象的引用超出作用域时,在该对象上自动调用Dispose(),该语法使用了using关键字来完成这一工作。这种情况下生成的IL代码和使用try块生成的是一样的。
using(MyClass mc = new MyClass())
{ }
using语句的后面是一对圆括号,其中是引用变量的声明和实例化,该语句使变量放在随附的语句块中,在变量超出作用域时,即使出现异常,也会自动调用Dispose()方法。