Vim7中的万能补全(Omni completion)
Table of Contents:
Vim7中的万能补全(Omni completion)
自动补全是Vim的一项重要功能。但由于中文的特性,这项功能对很多中文用户来讲显得不那么实用。在中国这项功能几乎只局限于写程序时使用了。
Vim支持多种形式的补全。补全的使用方法是按C-X,再根据所使用的补全输入相应的键。
- 整句补全对中文用户还是比较有用的C-l(这条命令在所有的buffer中查找匹配的行)。
- 单词补全基本没用因为中文的书写并不以词为单位(没有分隔)C-n(倒是也可当成整句补用)。
- 字典补全c-k和thesaurus补全。同样的对于中文只能当成整句补用。
- 单词补全还有一种C-k,除了在当前文件中找匹配外也在包含文件中查找匹配──对编程来讲比较有用。
- tags补全C-j。
- 文件名补全C-f。
- 定义和宏补全C-d。
- Vim命令补全C-v。
- 用户定义补全C-U。万能补全C-O。
1 万能补全基础
本文关于万能补全(omni completion)的所有内容同样适用于,用户定义补全(user completion)。
什么是万能补全?万能补全有什么作用呢?
万能补全是一种按自定义规则进行补全的补全功能。它的好处在于他给了用户满足特殊需要的灵活性。
万 能补全的使用方式是在插入模式下输入<C-x><C-o>(或者<C-x><C-u>)。不过在你使用 这项功能前你得先在自定义函数中定义补全所使用的规则。并相应地设置'omnifunc'(或'completefunc')。比如你自定义的规则在自定 义的UCompl()函数中则设置:
se ofu=UCompl
那这个自定义的函数或者说自定义的补全规则要怎么写呢?这就是我接下去要讲的最主要的内容。
这里先看一下自定义补全函数的基本框架:
func! Mycomp(start,base)
if a:start
" 返回欲匹配字的起始位置。对于英文就是往前找到第一个非字母字符的位置。
else
" 返回匹配列表。
endif
endfunc
之所以有这种奇怪的结构是因为这个函数实际要干两件事,就是上面注释中写的那两件事。这个程序会被调两次。
a:start可以认为是一个flag,第一次调用时这个值为1第二次调用时值为0。关于这个参数我们稍候再介绍.
如果第一次调用时未返回值则base为整行。返回负数base为空。
第二次所返回的将是匹配列表。空列表(list)或负值视为无匹配。
这里有两个参数是Vim传给omnifunc的他们是start,base,(当然在自定义函数内部,你可以任意取名)这两个参数是只读的。start刚已经讲过了,而base表示的是要进行补全的内容。如
how ar_
^^^ ^^
这里用'_'来表示在插入模式下的光标(下面如无说明最后的'_'都是表示插入模式下的光标位置),在使用C-X,C-P后会出现 补全列表──如果有的话。其对应的base就是'ar',然后C-P在当前文档中寻找匹配base的单词。而omni与C-P的不同之处在于base的产 生方法是由omnifunc决定的──即由用户决定的。前面我们说了omnifunc被调用了两次第一次返回的值,Vim会将之视为欲匹配字的起始位置, 这个位置到光标所在栏之间的字串就是base。
使用万能补全用户需要在函数中定义起始位置的计算方式,而base会由编辑器自动计算,并在第二次调用函数时给出。还有一点要注意的就是当我们使用了补全功能后base部分的字串将会被补全所使用的项所替代。
我再给一个例子,输入:
abcd_
在上面的文本中,光标的位置是5(即该行第5个字符的位置)而'a'的位置是1。如果第一次调用函数返回的值是2,即字符'b'的位置,则column 2跟5之间的内容即"cd"就是第二次调用时base的值。现在做一个试验:
func! Mycomp(st,base)
if a:st
return 2
else
echo "base=" . a:base
endif
endfunc
se omnifunc=Mycomp
运行上面的脚本并输入:
abcd_
因为是在插入模式,_表示光标所在的位置。这时如果我们输入C-X,C-O使用万能补全,可以从命令窗口看到base就是‘cd’。
现在你文该明白第一次调用是怎么一回事了。这个函数的前半部分定义了base的计算方式。那后半部分也很容易理解了,这一部分用来返回补全的列表。
现在我们可以写出一个有完整功能的补全函数了:
func! Mycomp(st,base)
if a:st
return 2
else
echo "base=" . a:base
return ["XXX YYY"]
endif
endfunc
se omnifunc=Mycomp
abcd_
补全的结果如下:
abXXX_
这个函数看上去不怎么实用,但功能完整。它“计算”base起始位置(其实它只是简单地返回2即返回'b'的位置,根本没进行什么计算),然后给出两个用来代替base的固定选项——只是它根本不考虑你前两个字符输入的是什么;-)
2 在返回的列表中使用字典
自动补全返回的是列表,但列表项可以使用字典的形式。如:
return [{"word":"abc","kind":"v","info":"变量"}, {"word":"eee","info":"也是变量"}]
其中word就是补全的值,而info是一些附加信息将会在preview窗口中显示。其他可以在返回列表项中使用的键(key)可以见*complete-items*
3 更多
为了做出更智能的补全函数,我们要先赋于函数判断base的 能力。对于编程或是英文书写的需要来说判断base很简单只要往前找到第一个空格的位置。为此我们需要取前一个位置的字符并判断是否是空格。不是则重复。 文档中已经有了一段示例代码:*complete-functions*
" locate the start of the word
let line = getline('.')
let start = col('.') - 1
" 直到找到非字母字符或行首
while start > 0 && line[start - 1] =~ '/a'
let start -= 1
endwhile
return start
计算起始位置的代码依不同的目的而有所不同但大体都是以这种形式出现。对大部分的应用来说也许更为重要的是如何返回有效的列表。
" find months matching with "a:base"
let res = []
for m in split("Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec")
if m =~ '^' . a:base
call add(res, m)
endif
endfor
return res
其实Vim并不在乎你返回的结果是怎么计算出来的,它只在乎有没有返回列表。要计算返回的列 表,有许多方式。在一般的情况下我们会先找(至少)一个大的匹配源,然后在这个源中找出匹配base的项并返回。而不同补全方式的主要差别也在于此。可以 认为,C-P就是以当前buffer为匹配源。C-L以所有buffer为匹配源(同时,它的start总是0)。字典、tags以外部文件为匹配源。上 面这个例子中匹配源在脚本中直接以列表的形式给出。
在omni中我们可以选择其中一种匹配源,也可以混合多种——这完全取决于我们的需要。比如我们写一个补全当前目录名的函数,当前目录就是匹配源。
下面的脚本根据已输入的字串补全目录名。
func! Dircompl(st,base)
if a:st
" 未进行起始位置的判断所以只限于在行首使用。
return 0
else
let res=[]
" 列出所有目录,并测试是否匹配
" (也可以直接用find)
for f_name in split(system("ls -m"),",")
" for f_name in split(system("dir /b"),"/n")
" 目录必须是以base开头的
if f_name=~ '^' . a:base
" 目录只须含base
" if f_name=~ a:base
call add(res, f_name)
endif
endfor
return res
endif
endfunc
se ofu=Dircompl
"se cfu=Dircompl
4 使用外部文件
前面的两个例子中我们用了外部程序来产生匹配源,但更多情况下我们会将匹配源置于外部文件之中。补全函数再对外部文件进行过滤产生补全列表。那我们要如何在Vim脚本中读入或者说是使用外部文件呢?
- 简单的方式是使用外部程序读入数据。不足是可移植性稍差。下面是三种不同格式的数据及其对应的读入命令:
每行为一条数据,"hack"
"hand"
"heep"
"hit"
"hold"
"hope"
"how"数据直接定义为列表格式,
["hack","hand","heep","hit","hold","hope","how"]
数据定义为以字典为列表项的列表格式:
[{"word":"hack","info":"这是hack的info"},{"word":"hand","info":"这是hand的info"}]上面的三种格式可以分别用下面的三条命令读入,
exe 'let wordlist=['. system('cat words|tr "/n" ,') . ']'
exe 'let wordlist='. system('cat words')
exe 'let wordlist='. system('cat words')读入数据后还需要对wordlist进行过滤并返回合适的匹配项作为补全列表。
提示:外部数据的格式很大程序上决定了函数的复杂程度,为了简化解析数据所需的代码应该尽可能地使用易于使用Vim进行处理的数据格式。
- 以Vim脚本的格式保存数据
上面的第二个外部文件的格式使用的就是列表的格式。如果我们直接将外部文件以Vim脚本的格式保存又会如何呢?下面是新的数据文件,同时也是脚本文件。let g:wordlist=["hack","hand","heep","hit","hold","hope","how"]
使用so或ru我们就有了匹配源,接下来就是过滤了。
so words
if exists("g:wordlist")
call filter(g:wordlist,'v:val =~ '.a:base)
return g:wordlist
endif - 使用函数readfile()
readfile()是个很好的解决方案:读入的每一行自动成为一个list项。使用了这个函数的脚本是平台独立的。for line in readfile(fname)
if line=~a:base
let res=add(res,line)
endif
endfor
return res - 以tags格式保存数据
tags格式保存的数据可以直接抓出为dictionary类型的数据。方法是使用*taglist()*let tl=taglist("thetag")但是光抓出来还不行,tags使用的键与自动补全接受的键有些不同。比如:taglist使用name作为第一栏数据的键名,而在补全函数支持的是word键。所以我们需要重新分配一下结果,使用能为我们所用:
let trs["word"]=tl["name"]
taglist()完整的用法可以参考下面的例子。
5 实例
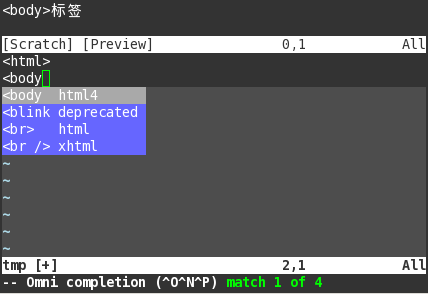
最后我们用一个简单的例子来结束关于万能补全的讨论。这个脚本根据外部文件对html标签进行自动补全。这个外部文件共有三栏,栏与栏之间用<tab>隔开——与tags文件的格式一样,这样我们就可以使用taglist()读入数据。
<body html4 <body>标签
<blink deprecated 闪烁标签,w3c不推荐使用此标签
<br> html 换行标签
<br /> xhtml 换行标签
<table html table 表格标签,用来新建一个表格
<th html table header
<td html table cell
<tr html table row
下面是代码:
func! Mycomp(st,base)
if a:st
let start=col('.')
let line=getline('.')
" 往前找到第一个'<'字符的位置
while start>0
if line[start-1]=='<'
" 返回该字符的前移一位的位置
return start-1
endif
let start-=1
endw
" 没找到。返回0这样在新起一行时可以显示全部列表
return 0
else
let res=[]
" 如果html标签文件的名称不是'tags',可用用下面注
" 释掉的代码更改供taglist()抓tag的文件名
" let oritags=&tags
" se tags=./htmltags
" 抓出匹配base的tag
let tl=taglist("^" . a:base)
" let &tags=oritags
" 将抓的结果改为补全功能能接受的形式
" 为了避免逐一地修改,需要使用map()
call map(tl,'s:T2l(v:val)')
return tl
endif
endfunc
func! s:T2l(val)
let res={}
let res['word']= a:val['name']
let res['menu']= a:val['filename']
let res['info']= a:val['cmd']
let res['kind']= a:val['kind']
return res
endfunc
" se cfu=Mycomp
se ofu=Mycomp
这个脚本的作用就是根据tags文件的内容补全html标签。功能很简单但已经用到了许多构造强大补全函数所需的元素。更复杂的例子可以在vim7的autoload文件夹中找到。有兴趣的用户不防了解一下Vim自带的补全函数是如何工作的。截图见这里。
Appendix A 中文议题
中文使用补全时的难点主要有三点,一个是起始位置的计算;二是字节与编码;三是数据文件的编码。
中文的字词之间没有空格要判断起始位置不好判断。(而单词补全的功能还不如输入法带的字词联想有用)。二是依编码的不同字有可能是两个字节三个字节。而起 始函数返回的不是该行的第几个字而是第几个字节的位置。一个方法是定义快捷键,使不同的热键表示不同的起始位置(往前两位,往前三位,往前六位)但这样却 失去了灵活性。三Vim不自动判别数据文件使用的编码,这样补全函数使用外部的数据文件时提示列表中可能会出现乱码。
以utf-8编码为例,如果要以当前光标的前一个字为base:
这是示例文_
utf-8的中文有三个字节为了使上面例子中的base为“文”,必需返回col(".")-4,而对于euc-cn/cp936编码则是col('.')-3,因些在处理汉字时需要对编码进行判断。这显然又增加了复杂度。
最后是如果正在编辑的文件与匹配源使用的编码不同,同一个汉字也会出现不匹配或者列表为乱码的情况。为些在进行匹配操作时要先对匹配源的编码进行转换。
最后我们写一个使用字典文件的补全函数。这个字典文件是以utf-8编码保存的(即&enc=="utf-8")。对于英文单词仍按一般方法返回base的起始位置——即往前找到第一个非字母字符的前一位置。而中文我们一律返回当前光标的前一个字。
先看一下字典,这是个中英文混合的字典(注意:是utf-8编码的):
hack
head
hello
jack
joke
joseph
情形
情况
文化
文本
文明
文人
这是最后的函数:
func! Mycomp(start,base)
if a:start
let start=col('.')
let line=getline('.')
" 如果是半角字符则照一般的英文规则,
" 往前找到第一个非字母字符
if line[start-2]=~'/a'
let start-=1
while start>0 && line[start-1]=~'/a'
let start -= 1
endwhile
return start
elseif line[start-2]=~'[[:punct:]/s/d ]'
" echo "space"|sleep 1
return -1
endif
" 如果不是字母也不是数字或空格标点则假设为汉字
" 固定返回前一个字符
if &encoding=="cp936" || &encoding=="euc-cn"
return start-3
elseif &encoding=="utf-8"
return start-4
endif
else
" echo a:base|sleep 1
let res = []
for line in readfile("words")
" 字典文件以utf8格式保存,需要进行编码转换
call add(res,iconv(line, "utf-8",&enc))
endfor
return filter(res,'v:val =~"^'.a:base.'"')
endif
endfunc
se ofu=Mycomp
提示:上面的自定义补全函数的行为与字典补全(<C-x><C-k>)的行为相似,除了两点:一处理汉字 时我们的自定义补全函数并不是以前的第一个非空字符的位置作为base的起始位置(因为汉字并不以空格作为字词之间的分隔符),而是简单的往前移一个汉 字。二字典补全在比较前并不进行编码的转换,因此在字典文件与当前编辑文件的编码不同时Vim不能正确给出匹配的汉字列表。当然这个函数的目的不在于取代 字典补全而是演示在万能补全中处理汉字的一些注意事项。
Appendix B 用自动补全来计算结果
自动补全并不一定要用来“补”。下面的函数通过外部程序进行计算并以补全的方式给出结果:
func! Mycomp(st,base)
if a:st
" 未进行起始位置的判断所以只限于在行首使用。
return 0
else
let res=[]
call add(res,system("echo " . a:base .'|bc|tr -d /r/n'))
return res
endif
endfunc
运行结果(下划线表示插入模式下光标所在位置):
2+2*3+(2+2)*2_
按<C-x><C-o>返回16。
6 Comments »
The URI to TrackBack this entry is: http://blah.blogsome.com/2006/06/27/vim7_tut_oc/trackback/
请问阁下是如何写这些blog文章的,我的意思是阁下很喜欢vim,那么一定是用vim写文章的了,那么在wp里面如何把写好的文章贴进来呢,图片如何解决,应该有不错的方法,取经一二,多谢
Comment by chinhantang — 2006, June 28 @ 12:38
用texinfo格式写的,工具是Vim和makeinfo。写完后用makeinfo编译成html文档。最后把生成的html文档贴到blog上。
* texinfo文档的写法见info texinfo
* texinfo支持插入图片(不过本篇最后的附图是手工添加的)。
* 贴文章前要对编译的html文档进行一些修改(去文件头,修复中文链接……等),可以用脚本来完成这些琐碎的任务(当然手工修改也无不可)。
* 至于显示是由CSS控制的。修改wp中的CSS模板使之符合你的要求。
* 其他可用于生成格式化html文档的还有Viki,Vim reStructured Text和laTex。
Comment by hq00e — 2006, June 28 @ 20:58
多谢解释
还有更多的问题
进来正在看格式化文档,发现很多种:Markdown ReStructuredText textile wiki vst latex docbook,也看了这些的具体介绍,但就是不知道选择哪一种好,阁下又一个选择texinfo,眼看花了,仍然不知道该选择哪一种,请解惑
Comment by chinhantang — 2006, June 28 @ 22:02
其实无所谓那种工具更好,看自已的需要再选择吧。就生成html文档而言这几种文档格式(除latex和docbook外)都挺不错的。也都大同小异不用过多比较,挑一种学吧:-)如果你用Vim的话用VST,VST的好处是不依赖于外部工具。
LaTex 是排版软件,如果你要的不只是一分整齐的文档,可以使用LaTex。Docbook更像是一种中介格式,很容易转换为其他格式,但不适合手写。从语法上来 讲texinfo很像latex,只是在texinfo中生成文档的效果是相对固定的——好处是用户不用分心控制文档的外观。texinfo的文档可以转 换为多种其他格式的文档包括了docbook。
总而言之,不用过多比较,挑一种然后认真地学认真的用。它们都比手工编辑网页方便多了。HTH。
Comment by hq00e — 2006, June 28 @ 23:36
明白了许多,之前我在google中几乎搜索了所有的中文页面,也几乎没有找到比较这些格式化文档的说明。
能不能这样说,Markdown ReStructuredText textile wiki vst属于简单轻巧型,但又轻巧的近乎随意,那么在这里面我选择wiki,因为以后wiki应该更为常见,并且以后很可能要编辑wiki。
重量型的有latex,docbook,texinfo等,这里面我选择docbook,因为它的格式可能会成为未来文档的首选。
操作系统选择ubuntu、gentoo,编辑器选择vim。
站长的文章非常有深度,值得仔细品读,希望能继续写下去,强烈支持
呵呵,好像缺少一个留言板,这些问题不是针对该篇文章的。
Comment by chinhantang — 2006, June 29 @ 14:12
docbook(在未来可能)是一种很好的中介格式(易于在不同环境中交换信息也易于机器解析处理),但我已经说过docbook本身并不适合手写,你完全可以通过工具将你的latex,texinfo文档或者是经过简单标注的文本文件转为docbook格式。
texinfo称不上重量型,可以认为texinfo是使用了固定package的latex。dockbook跟xml的关系与texinfo跟latex的关系相似。
至于是使用viki(我假设你说的wiki其实是viki)还是其他格式都差不多,认准了就学吧……
留言不一定要针对文章的,“离题”也无妨。当然也可以发邮件给我。
PS: 谢谢你的鼓励:-)
Comment by hq00e — 2006, July 8 @