这篇文章昨天就写好了。但感觉就是没把问题说明白,大家看了反而会糊涂。可能是题目范围太广,要准确的清楚,显得有些困然。如果要我写个5、6篇文章说明这个问题,我觉得累啥!最后就决定采用QA的方式,来避免题目太广的麻烦。说是QA,其实这个Q也是我,A也是我,自问自答啦!(YY:本来想找MM顶替Q的角色,我担心她会问出这样的问题“你什么时候做中饭啊!”,想想算了,我就不麻烦她啦。(*^__^*))
平时大家都知道参数化查询好,存储过程好,这里具体分析一下到底为什么好。而且这个好处不但是编译,还可以节约MSSQL占用的内存。作为开发人员和系统设计人员,应该了解到这层就够了,更深入的就交给DBA去完成啦!
QA集锦:
Q:什么是执行缓存。
A:具体大家google。我简单说一下:就是MSSQL对一些可以重复使用的过程、语句进行存储,减少相同过程、语句的重新编译(PS:语法、语义、执行计划等的分析)。举个不太恰当的比喻:
A到了一家新公司E。
第一天上班。因为只知道大概方向,所以A早起开始探路。A->B公交站->C地铁站->D公交站->E公司.A现在知道到公司的路线了(记忆在人脑中)
第二天上班。A不需要早起,按昨天的路线(记忆在大脑中)就可以到公司了。
那么执行缓存其实就是(记忆在大脑中)的这个东西,一旦MSSQL,发现有相同的存储过程、或是SQL语句,它就可以直接运行,而不需要在进行语义、语法分析等。
Q:上文有提到“相同”,那么MSSQL是如何判断存储过程(SP)、语句是相同的呢?
A:通过HashCode 哈希值来判断是否相等。有的地方也称为SQL句柄。如果他们的哈希值相同,那么就是同一个存储过程、语句。(PS:存储过程好像是根据名字来的,比如 dbo.Test1,其实他们的哈希值也是一样的啦)。MS提供一个方法 sys.dm_exec_sql_text 将哈希值转换为SQL语句噢,下面的方法就会用到这个函数!不过我没找到如何将一个SQL语句转换为SQL句柄的方法,有知道的告诉我一下。(PS:C# 有一个GetHashCode方法,道理是一样的)。
Q:知道如何判断相同,那么这些相同的存储过程(SP)、语句存储在哪里呢。
A:你就是想知道这些缓存的内容放在什么地方是吧!MS说这是一张虚拟表。这个我就不深究了,我提供两个语句(PS:语句并非原创),你可以看到具体的缓存内容。
1:sys.dm_exec_cached_plans
Select TOP 100 usecounts,objtype,p.size_in_bytes,[sql].[text] FROM sys.dm_exec_cached_plans p OUTER APPLY sys.dm_exec_sql_text (p.plan_handle) sql
2:sys.dm_exec_query_stats
SELECT TOP 100
qs.execution_count,
DatabaseName = DB_NAME(qp.dbid),
--ObjectName = OBJECT_NAME(qp.objectid,qp.dbid),
StatementDefinition =
SUBSTRING (
st.text,
(
qs.statement_start_offset / 2
) + 1,
(
(
CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset
) / 2
) + 1
),
query_plan,
st.text, total_elapsed_time
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
CROSS APPLY sys.dm_exec_query_plan (qs.plan_handle) qp
WHERE
st.encrypted = 0
ORDER BY qs.execution_count DESC
第一个方法看的内容不多,第二个方法看的内容更加详细。为什么留两个,实践一下。哈哈,看到当前的执行缓存了吧,兴奋啊!原来MSSQL大脑里就记忆了这些。有了这些大家其实也可以明白,这对于SQL语句效率的优化可是个好东西。execution_count数,当然是重复利用率越高越好了。在看看StatementDefinition,如果有很多相同或类似的证明的执行缓存重覆率太高,而且这样也消耗了大量的MSSQL内存。
方法一截图: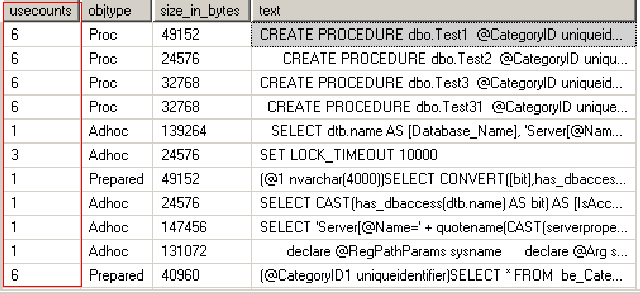
方法二截图: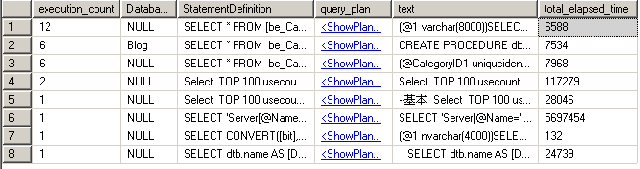
Q:那能不能清空当前的执行缓存呢?因为这样方便调试,要不一堆数据无法查看新增的执行缓存啊。
A:恩,不错,想法很好。但这个操作不能随便在生产环境运行,这样很可能造成系统效率问题。警告完了,告诉语句:dbcc freeproccache
Q:等等!再问个问题,如何查看当前使用的执行缓存呢?这样也方便调试啊,可以看到缓存的变化情况啊!
A: dbcc memorystatus,具体如图: 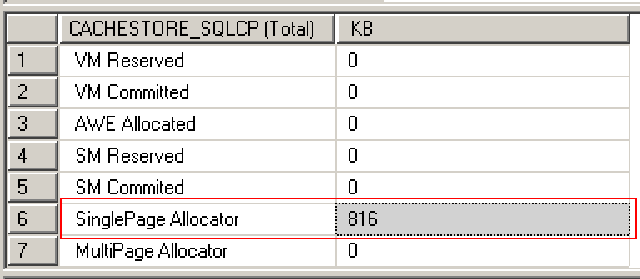
Q: 还有.....
A:打住!不耐烦了,我说最后一句。大家也可以通过SQL Profiler查看到缓存的相关动作。图上列举的Event不全,大家可以通过设置得到更多的事件。有些事件我也没太明白,用空在具体分析吧!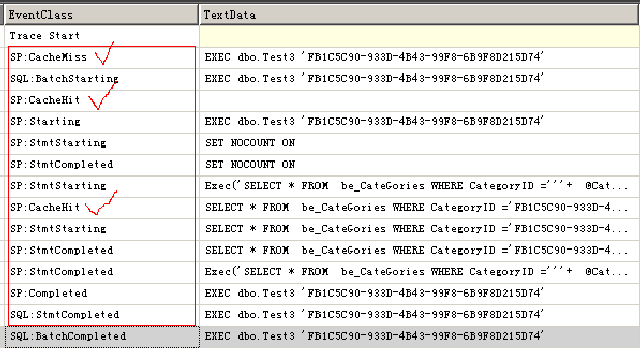
总结:
说白了就是MSSQL将很多相同的语句进行保留,一旦发现相同的语句,就直接运行,而不需要去分析和处理。这样也就很自然的提高了效率。减少重复自然就减少SQL内存的占用。 对于一个高用户访问的网站,这个开销还是可观的。
实践:
给大家留下一个问题:下面三个存储过程,在执行缓存中有什么不同(PS:效率上的,文字上我也知道不同)。如果你实践了,应该就明白了。
CREATE PROCEDURE dbo.Test1
@CategoryID uniqueidentifier
AS
BEGIN
SET NOCOUNT ON
SELECT * FROM be_CateGories WHERE CategoryID = @CategoryID
END
CREATE PROCEDURE dbo.Test2
@CategoryID uniqueidentifier
AS
BEGIN
SET NOCOUNT ON;
exec sp_executesql N'SELECT * FROM be_CateGories WHERE CategoryID = @CategoryID1',N'@CategoryID1 uniqueidentifier',@CategoryID1 = @CategoryID
END
CREATE PROCEDURE dbo.Test3
@CategoryID uniqueidentifier
AS
BEGIN
SET NOCOUNT ON
Exec('SELECT * FROM be_CateGories WHERE CategoryID ='''+ @CategoryID + '''')
END
GO
参考:
http://database.ctocio.com.cn/tips/445/7779945.shtml
http://blog.csdn.net/xychen2008/archive/2007/08/28/1761544.aspx
http://soft.zdnet.com.cn/software_zone/2007/0821/462753.shtml