以下内容转载自:http://www.open-open.com/lib/view/open1328070090108.html
分布式 Git
为了便于项目中的所有开发者分享代码,我们准备好了一台服务器存放远程 Git 仓库。经过前面几章的学习,我们已经学会了一些基本的本地工作流程中所需用到的命令。接下来,我们要学习下如何利用 Git 来组织和完成分布式工作流程。
特别是,当作为项目贡献者时,我们该怎么做才能方便维护者采纳更新;或者作为项目维护者时,又该怎样有效管理大量贡献者的提交。
5.1 分布式工作流程
同传统的集中式版本控制系统(CVCS)不同,开发者之间的协作方式因着 Git 的分布式特性而变得更为灵活多样。在集中式系统上,每个开发者就像是连接在集线器上的节点,彼此的工作方式大体相像。而在 Git 网络中,每个开发者同时扮演着节点和集线器的角色,这就是说,每一个开发者都可以将自己的代码贡献到另外一个开发者的仓库中,或者建立自己的公共仓库,让 其他开发者基于自己的工作开始,为自己的仓库贡献代码。于是,Git 的分布式协作便可以衍生出种种不同的工作流程,我会在接下来的章节介绍几种常见的应用方式,并分别讨论各自的优缺点。你可以选择其中的一种,或者结合起
来,应用到你自己的项目中。
集中式工作流
通常,集中式工作流程使用的都是单点协作模型。一个存放代码仓库的中心服务器,可以接受所有开发者提交的代码。所有的开发者都是普通的节点,作为中心集线器的消费者,平时的工作就是和中心仓库同步数据(见图 5-1)。

图 5-1. 集中式工作流
如果两个开发者从中心仓库克隆代码下来,同时作了一些修订,那么只有第一个开发者可以顺利地把数据推送到共享服务器。第二个开发者在提交他的修订之 前,必须先下载合并服务器上的数据,解决冲突之后才能推送数据到共享服务器上。在 Git 中这么用也决无问题,这就好比是在用 Subversion(或其他 CVCS)一样,可以很好地工作。
如果你的团队不是很大,或者大家都已经习惯了使用集中式工作流程,完全可以采用这种简单的模式。只需要配置好一台中心服务器,并给每个人推送数据的 权限,就可以开展工作了。但如果提交代码时有冲突, Git 根本就不会让用户覆盖他人代码,它直接驳回第二个人的提交操作。这就等于告诉提交者,你所作的修订无法通过快近(fast-forward)来合并,你必 须先拉取最新数据下来,手工解决冲突合并后,才能继续推送新的提交。绝大多数人都熟悉和了解这种模式的工作方式,所以使用也非常广泛。
集成管理员工作流
由于 Git 允许使用多个远程仓库,开发者便可以建立自己的公共仓库,往里面写数据并共享给他人,而同时又可以从别人的仓库中提取他们的更新过来。这种情形通常都会有 个代表着官方发布的项目仓库(blessed repository),开发者们由此仓库克隆出一个自己的公共仓库(developer public),然后将自己的提交推送上去,请求官方仓库的维护者拉取更新合并到主项目。维护者在自己的本地也有个克隆仓库(integration manager),他可以将你的公共仓库作为远程仓库添加进来,经过测试无误后合并到主干分支,然后再推送到官方仓库。工作流程看起来就像图
5-2 所示:
- 项目维护者可以推送数据到公共仓库 blessed repository。 2. 贡献者克隆此仓库,修订或编写新代码。
- 贡献者推送数据到自己的公共仓库 developer public。 4. 贡献者给维护者发送邮件,请求拉取自己的最新修订。
- 维护者在自己本地的 integration manger 仓库中,将贡献者的仓库加为远程仓库,合并更新并做测试。
- 维护者将合并后的更新推送到主仓库 blessed repository。

图 5-2. 集成管理员工作流
在 GitHub 网站上使用得最多的就是这种工作流。人们可以复制(fork 亦即克隆)某个项目到自己的列表中,成为自己的公共仓库。随后将自己的更新提交到这个仓库,所有人都可以看到你的每次更新。这么做最主要的优点在于,你可 以按照自己的节奏继续工作,而不必等待维护者处理你提交的更新;而维护者也可以按照自己的节奏,任何时候都可以过来处理接纳你的贡献。
司令官与副官工作流
这其实是上一种工作流的变体。一般超大型的项目才会用到这样的工作方式,像是拥有数百协作开发者的 Linux 内核项目就是如此。各个集成管理员分别负责集成项目中的特定部分,所以称为副官(lieutenant)。而所有这些集成管理员头上还有一位负责统筹的总 集成管理员,称为司令官(dictator)。司令官维护的仓库用于提供所有协作者拉取最新集成的项目代码。整个流程看起来如图 5-3 所示:
- 一般的开发者在自己的特性分支上工作,并不定期地根据主干分支(dictator 上的 master)衍合。
- 副官(lieutenant)将普通开发者的特性分支合并到自己的 master 分支中。
- 司令官(dictator)将所有副官的 master 分支并入自己的 master 分支。
- 司令官(dictator)将集成后的 master 分支推送到共享仓库 blessed repository 中,以便所有其他开发者以此为基础进行衍合。

图 5-3. 司令官与副官工作流
这种工作流程并不常用,只有当项目极为庞杂,或者需要多级别管理时,才会体现出优势。利用这种方式,项目总负责人(即司令官)可以把大量分散的集成工作委托给不同的小组负责人分别处理,最后再统筹起来,如此各人的职责清晰明确,也不易出错(译注:此乃分而治之)。
以上介绍的是常见的分布式系统可以应用的工作流程,当然不止于 Git。在实际的开发工作中,你可能会遇到各种为了满足特定需求而有所变化的工作方式。我想现在你应该已经清楚,接下来自己需要用哪种方式开展工作了。下 节我还会再举些例子,看看各式工作流中的每个角色具体应该如何操作。
5.2 为项目作贡献
接下来,我们来学习一下作为项目贡献者,会有哪些常见的工作模式。
不过要说清楚整个协作过程真的很难,Git 如此灵活,人们的协作方式便可以各式各样,没有固定不变的范式可循,而每个项目的具体情况又多少会有些不同,比如说参与者的规模,所选择的工作流程,每个人的提交权限,以及 Git 以外贡献等等,都会影响到具体操作的细节。
首当其冲的是参与者规模。项目中有多少开发者是经常提交代码的?经常又是多久呢?大多数两至三人的小团队,一天大约只有几次提交,如果不是什么热门 项目的话就更少了。可要是在大公司里,或者大项目中,参与者可以多到上千,每天都会有十几个上百个补丁提交上来。这种差异带来的影响是显著的,越是多的人 参与进来,就越难保证每次合并正确无误。你正在工作的代码,可能会因为合并进来其他人的更新而变得过时,甚至受创无法运行。而已经提交上去的更新,也可能 在等着审核合并的过程中变得过时。那么,我们该怎样做才能确保代码是最新的,提交的补丁也是可用的呢?
接下来便是项目所采用的工作流。是集中式的,每个开发者都具有等同的写权限?项目是否有专人负责检查所有补丁?是不是所有补丁都做过同行复阅(peer-review)再通过审核的?你是否参与审核过程?如果使用副官系统,那你是不是限定于只能向此副官提交?
还有你的提交权限。有或没有向主项目提交更新的权限,结果完全不同,直接决定最终采用怎样的工作流。如果不能直接提交更新,那该如何贡献自己的代码呢?是不是该有个什么策略?你每次贡献代码会有多少量?提交频率呢?
所有以上这些问题都会或多或少影响到最终采用的工作流。接下来,我会在一系列由简入繁的具体用例中,逐一阐述。此后在实践时,应该可以借鉴这里的例子,略作调整,以满足实际需要构建自己的工作流。
提交指南
开始分析特定用例之前,先来了解下如何撰写提交说明。一份好的提交指南可以帮助协作者更轻松更有效地配合。Git 项目本身就提供了一份文档(Git 项目源代码目录中Documentation/SubmittingPatches),列数了大量提示,从如何编撰提交说明到提交补丁,不一而足。
首先,请不要在更新中提交多余的白字符(whitespace)。Git 有种检查此类问题的方法,在提交之前,先运行 git diff --check,会把可能的多余白字符修正列出来。下面的示例,我已经把终端中显示为红色的白字符用X 替换掉:
$ git diff --check
lib/simplegit.rb:5: trailing whitespace.
+ @git_dir = File.expand_path(git_dir)XX
lib/simplegit.rb:7: trailing whitespace.
+ XXXXXXXXXXX
lib/simplegit.rb:26: trailing whitespace.
+ def command(git_cmd)XXXX这样在提交之前你就可以看到这类问题,及时解决以免困扰其他开发者。
接下来,请将每次提交限定于完成一次逻辑功能。并且可能的话,适当地分解为多次小更新,以便每次小型提交都更易于理解。请不要在周末穷追猛打一次性 解决五个问题,而最后拖到周一再提交。就算是这样也请尽可能利用暂存区域,将之前的改动分解为每次修复一个问题,再分别提交和加注说明。如果针对两个问题 改动的是同一个文件,可以试试看git 的方式将部分内容置入暂存区域(我们会在第六章再详细介绍)。无论是五次小提交还是混杂在一起的大提交,最终分支末端的项目快照应该还是一样的,但分解开 来之后,更便于其他开发者复阅。这么做也方便自己将来取消某个特定问题的修复。我们将在第六章介绍一些重写提交历史,同暂存区域交互的技巧和工具,以便最 终得到一个干净有意义,且易于理解的提交历史。
add --patch
最后需要谨记的是提交说明的撰写。写得好可以让大家协作起来更轻松。一般来说,提交说明最好限制在一行以内,50 个字符以下,简明扼要地描述更新内容,空开一行后,再展开详细注解。Git 项目本身需要开发者撰写详尽注解,包括本次修订的因由,以及前后不同实现之间的比较,我们也该借鉴这种做法。另外,提交说明应该用祈使现在式语态,比如, 不要说成 “I added tests for” 或 “Adding tests for” 而应该用 “Add tests for”。下面是来自 tpope.net 的 Tim Pope
原创的提交说明格式模版,供参考:
本次更新的简要描述(50 个字符以内)
如果必要,此处展开详尽阐述。段落宽度限定在 72 个字符以内。
某些情况下,第一行的简要描述将用作邮件标题,其余部分作为邮件正文。
其间的空行是必要的,以区分两者(当然没有正文另当别论)。
如果并在一起,rebase 这样的工具就可能会迷惑。
另起空行后,再进一步补充其他说明。
- 可以使用这样的条目列举式。
- 一般以单个空格紧跟短划线或者星号作为每项条目的起始符。每个条目间用一空行隔开。
不过这里按自己项目的约定,可以略作变化。
如果你的提交说明都用这样的格式来书写,好多事情就可以变得十分简单。Git 项目本身就是这样要求的,我强烈建议你到 Git 项目仓库下运行 git log --no-merges 看看,所有提交历史的说明是怎样撰写的。(译注:如果现在还没有克隆
git 项目源代码,是时候git clone git://git.kernel.org/pub/scm/git/git.git 了。)
为简单起见,在接下来的例子(及本书随后的所有演示)中,我都不会用这种格式,而使用 -m 选项提交 git。不过请还是按照我之前讲的做,别学我这里偷懒的方式。
commit
私有的小型团队
我们从最简单的情况开始,一个私有项目,与你一起协作的还有另外一到两位开发者。这里说私有,是指源代码不公开,其他人无法访问项目仓库。而你和其他开发者则都具有推送数据到仓库的权限。
这种情况下,你们可以用 Subversion 或其他集中式版本控制系统类似的工作流来协作。你仍然可以得到 Git 带来的其他好处:离线提交,快速分支与合并等等,但工作流程还是差不多的。主要区别在于,合并操作发生在客户端而非服务器上。让我们来看看,两个开发者一 起使用同一个共享仓库,会发生些什么。第一个人,John,克隆了仓库,作了些更新,在本地提交。(下面的例子中省略了常规提示,用... 代替以节约版面。)
# John's Machine
$ git clone john@githost:simplegit.git
Initialized empty Git repository in /home/john/simplegit/.git/
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'removed invalid default value'
[master 738ee87] removed invalid default value
1 files changed, 1 insertions(+), 1 deletions(-)第二个开发者,Jessica,一样这么做:克隆仓库,提交更新:
# Jessica's Machine
$ git clone jessica@githost:simplegit.git
Initialized empty Git repository in /home/jessica/simplegit/.git/
...
$ cd simplegit/
$ vim TODO
$ git commit -am 'add reset task'
[master fbff5bc] add reset task
1 files changed, 1 insertions(+), 0 deletions(-)现在,Jessica 将她的工作推送到服务器上:
# Jessica's Machine
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> masterJohn 也尝试推送自己的工作上去:
# John's Machine
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.git'John 的推送操作被驳回,因为 Jessica 已经推送了新的数据上去。请注意,特别是你用惯了 Subversion 的话,这里其实修改的是两个文件,而不是同一个文件的同一个地方。Subversion 会在服务器端自动合并提交上来的更新,而 Git 则必须先在本地合并后才能推送。于是,John 不得不先把 Jessica 的更新拉下来:
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/master此刻,John 的本地仓库如图 5-4 所示:

图 5-4. John 的仓库历史
虽然 John 下载了 Jessica 推送到服务器的最近更新(fbff5),但目前只是 origin/master 指针指向它,而当前的本地分支master 仍然指向自己的更新(738ee),所以需要先把她的提交合并过来,才能继续推送数据:
$ git merge origin/master
Merge made by recursive.
TODO | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)还好,合并过程非常顺利,没有冲突,现在 John 的提交历史如图 5-5 所示:
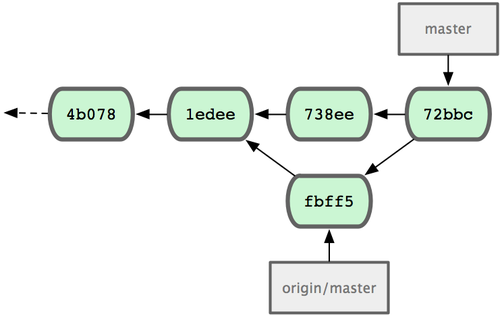
图 5-5. 合并 origin/master 后 John 的仓库历史
现在,John 应该再测试一下代码是否仍然正常工作,然后将合并结果(72bbc)推送到服务器上:
$ git push origin master
...
To john@githost:simplegit.git
fbff5bc..72bbc59 master -> master最终,John 的提交历史变为图 5-6 所示:

图 5-6. 推送后 John 的仓库历史
而在这段时间,Jessica 已经开始在另一个特性分支工作了。她创建了 issue54 并提交了三次更新。她还没有下载 John 提交的合并结果,所以提交历史如图 5-7 所示:
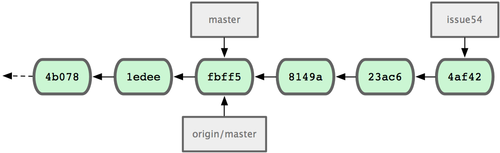
图 5-7. Jessica 的提交历史
Jessica 想要先和服务器上的数据同步,所以先下载数据:
# Jessica's Machine
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/master于是 Jessica 的本地仓库历史多出了 John 的两次提交(738ee 和 72bbc),如图 5-8 所示:

图 5-8. 获取 John 的更新之后 Jessica 的提交历史
此时,Jessica 在特性分支上的工作已经完成,但她想在推送数据之前,先确认下要并进来的数据究竟是什么,于是运行git log 查看:
$ git log --no-merges origin/master ^issue54
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith
Date: Fri May 29 16:01:27 2009 -0700
removed invalid default value
现在,Jessica 可以将特性分支上的工作并到 master 分支,然后再并入 John 的工作(origin/master)到自己的master分支,最后再推送回服务器。当然,得先切回主分支才能集成所有数据:
$ git checkout master
Switched to branch "master"
Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded.
要合并 origin/master 或 issue54 分支,谁先谁后都没有关系,因为它们都在上游(upstream)(译注:想像分叉的更新像是汇流成河的源头,所以上游
upstream 是指最新的提交),所以无所谓先后顺序,最终合并后的内容快照都是一样的,而仅是提交历史看起来会有些先后差别。Jessica 选择先合并issue54:
$ git merge issue54
Updating fbff5bc..4af4298
Fast forward
README | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1 deletions(-)
正如所见,没有冲突发生,仅是一次简单快进。现在 Jessica 开始合并 John 的工作(origin/master):
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)所有的合并都非常干净。现在 Jessica 的提交历史如图 5-9 所示:

图 5-9. 合并 John 的更新后 Jessica 的提交历史
现在 Jessica 已经可以在自己的 master 分支中访问 origin/master 的最新改动了,所以她应该可以成功推送最后的合并结果到服务器上(假设
John 此时没再推送新数据上来):
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> master至此,每个开发者都提交了若干次,且成功合并了对方的工作成果,最新的提交历史如图 5-10 所示:
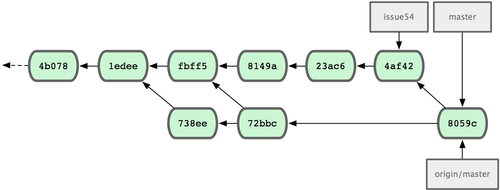
图 5-10. Jessica 推送数据后的提交历史
以上就是最简单的协作方式之一:先在自己的特性分支中工作一段时间,完成后合并到自己的 master 分支;然后下载合并 origin/master 上的更新(如果有的话),再推回远程服务器。一般的协作流程如图
5-11 所示:
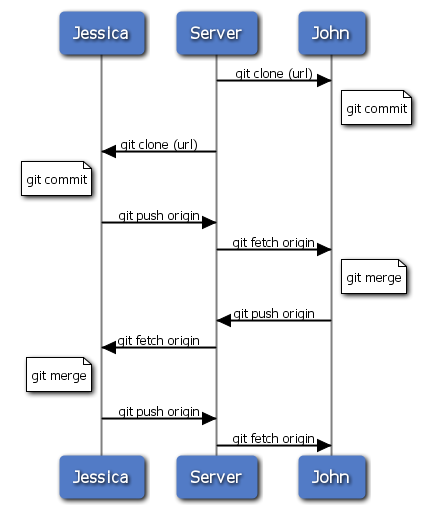
图 5-11. 多用户共享仓库协作方式的一般工作流程时序
私有团队间协作
现在我们来看更大一点规模的私有团队协作。如果有几个小组分头负责若干特性的开发和集成,那他们之间的协作过程是怎样的。
假设 John 和 Jessica 一起负责开发某项特性 A,而同时 Jessica 和 Josie 一起负责开发另一项功能 B。公司使用典型的集成管理员式工作流,每个组都有一名管理员负责集成本组代码,及更新项目主仓库的master 分支。所有开发都在代表小组的分支上进行。
让我们跟随 Jessica 的视角看看她的工作流程。她参与开发两项特性,同时和不同小组的开发者一起协作。克隆生成本地仓库后,她打算先着手开发特性 A。于是创建了新的featureA 分支,继而编写代码:
# Jessica's Machine
$ git checkout -b featureA
Switched to a new branch "featureA"
$ vim lib/simplegit.rb
$ git commit -am 'add limit to log function'
[featureA 3300904] add limit to log function
1 files changed, 1 insertions(+), 1 deletions(-)
此刻,她需要分享目前的进展给 John,于是她将自己的 featureA 分支提交到服务器。由于 Jessica 没有权限推送数据到主仓库的master 分支(只有集成管理员有此权限),所以只能将此分支推上去同
John 共享协作: