原文: http://www.cnblogs.com/shipengzhi/articles/2540514.html
聚类是机器学习里很重要的一类方法,基本原则是将“性质相似”(这里就有相似的标准问题,比如是基于概率分布模型的相似性又或是基于距离的相似性)的对象尽可能的放在一个Cluster中而不同Cluster中对象尽可能不相似。对聚类算法而言,有三座大山需要爬过去:(1)、a large number of clusters,(2)、a
high feature dimensionality,(3)、a large number of data points。在这三种情况下,尤其是三种情况都存在时,聚类的计算代价是非常高的,有时候聚类都无法进行下去,于是出现一种简单而又有效地方法:Canopy Method,说简单是因为它不用什么高深的理论或推导就可以理解,说有效是因为它的实际表现确实可圈可点。
一、基本思想
1、基于Canopy Method的聚类算法将聚类过程分为两个阶段
Stage1、聚类最耗费计算的地方是计算对象相似性的时候,Canopy Method在第一阶段选择简单、计算代价较低的方法计算对象相似性,将相似的对象放在一个子集中,这个子集被叫做Canopy ,通过一系列计算得到若干Canopy,Canopy之间可以是重叠的,但不会存在某个对象不属于任何Canopy的情况,可以把这一阶段看做数据预处理;
Stage2、在各个Canopy 内使用传统的聚类方法(如K-means),不属于同一Canopy 的对象之间不进行相似性计算。
从这个方法起码可以看出两点好处:首先,Canopy 不要太大且Canopy 之间重叠的不要太多的话会大大减少后续需要计算相似性的对象的个数;其次,类似于K-means这样的聚类方法是需要人为指出K的值的,通过Stage1得到的Canopy 个数完全可以作为这个K值,一定程度上减少了选择K的盲目性。
2、聚类精度
对传统聚类来说,例如K-means、Expectation-Maximization、Greedy Agglomerative Clustering,某个对象与Cluster的相似性是该点到Cluster中心的距离,那么聚类精度能够被很好保证的条件是:
对于每个Cluster都存在一个Canopy,它包含所有属于这个Cluster的元素。
如果这种相似性的度量为当前点与某个Cluster中离的最近的点的距离,那么聚类精度能够被很好保证的条件是:
对于每个Cluster都存在若干个Canopy,这些Canopy之间由Cluster中的元素连接(重叠的部分包含Cluster中的元素)。
数据集的Canopy划分完成后,类似于下图:
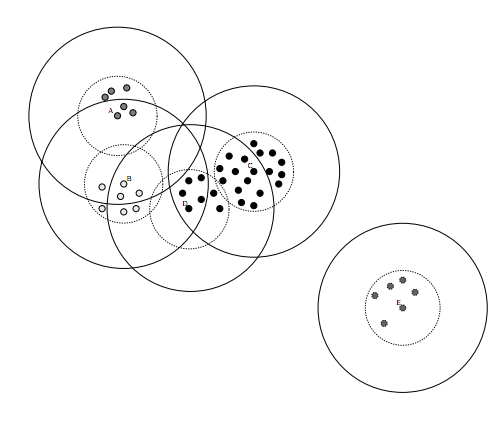
二、单机生成Canopy的算法
(1)、将数据集向量化得到一个list后放入内存,选择两个距离阈值:T1和T2,其中T1 > T2,对应上图,实线圈为T1,虚线圈为T2,T1和T2的值可以用交叉校验来确定;
(2)、从list中任取一点P,用低计算成本方法快速计算点P与所有Canopy之间的距离(如果当前不存在Canopy,则把点P作为一个Canopy),如果点P与某个Canopy距离在T1以内,则将点P加入到这个Canopy;
(3)、如果点P曾经与某个Canopy的距离在T2以内,则需要把点P从list中删除,这一步是认为点P此时与这个Canopy已经够近了,因此它不可以再做其它Canopy的中心了;
(4)、重复步骤2、3,直到list为空结束。
三、并行策略
并行点是比较明显的,就是生成Canopy的过程可以并行,第一阶段,各个slave可以依据存储在本地的数据,各自在本地用上述算法生成若干Canopy,最后在master机器将这些Canopy用相同算法汇总后得到最终的Canopy集合,第二阶段聚类操作就利用最终的Canopy集合进行。
用map-reduce描述就是:datanode在map阶段,利用上述算法在本地生成若干Canopy,之后通过reduce操作得到最终的Canopy集合。