虽然南京大学周志华老师的论文已经写得非常浅显易懂了,但是对于只有点概率统计基础的我来说还是有许多地方看不懂,而且概率统计的知识早在几年前学的,现在经常没有用到导致很多概念在见到的时候还是会感觉很模糊,对于阅读论文或者编写代码都有点影响。所以想在此处系统的边学习边分享总结下,让自己以后忘了的时候可以到这篇文章里很快的回忆起来。有错误的地方还请大家指正!
首先从概率密度函数讲起吧,之前的知识还算能记得,就不说了,呵呵。
一、概率密度函数
在维基百科上定义的概率密度函数式连续型随机变量的,概率质量函数是离散型随机变量的。
连续型随机变量的概率密度函数是一个描述这个随机变量的输出值,在某个确定的取值点附近的可能性的函数。而随机变量的取值落在某个区域之内的概率则为概率密度函数在这个区域上的积分。当概率密度函数存在的时候,累积分布函数是概率密度函数的积分。概率密度函数一般以小写“pdf”(Probability Density Function)标记。
概率质量函数(probability
mass function,简写为pmf)是离散随机变量在各特定取值上的概率。
概率质量函数和概率密度函数不同之处在于:概率质量函数是对离散随机变量定义的,本身代表该值的概率;概率密度函数是对连续随机变量定义的,本身不是概率,只有对连续随机变量的概率密度函数在某区间内进行积分后才是概率。
假设X是抛硬币的结果,反面取值为0,正面取值为1。则在状态空间{0,
1}(这是一个Bernoulli随机变量)中,X = x的概率是0.5,所以概率质量函数是

概率质量函数可以定义在任何离散随机变量上,包括常数分布, 二项分布(包括Bernoulli分布), 反二项分布, Poisson分布, 几何分布以及超几何分布随机变量上.
最简单的概率密度函数是均匀分布的密度函数。对于一个取值在区间![[a, b]](http://upload.wikimedia.org/math/2/c/3/2c3d331bc98b44e71cb2aae9edadca7e.png) 上的均匀分布函数
上的均匀分布函数![\mathbf{I}_{[a,b]}](http://upload.wikimedia.org/math/3/d/8/3d882eea26cc659d979658ee56079b07.png) ,它的概率密度函数:
,它的概率密度函数:
![f_{\mathbf{I}_{[a,b]} } (x) = \frac{1}{b-a}\mathbf{I}_{[a,b]}](http://upload.wikimedia.org/math/4/c/c/4cc6fcdeb801463d09624f4d8f528efd.png)
也就是说,当x 不在区间上的时候,函数值等于0,而在区间上的时候,函数值等于 。这个函数并不是完全的连续函数,但是是可积函数。正态分布是重要的概率分布。它的概率密度函数是:
。这个函数并不是完全的连续函数,但是是可积函数。正态分布是重要的概率分布。它的概率密度函数是:

随着参数 和
和 变化,概率分布也产生变化。(参数即是描述整体特征的一种概率性数字度量,比如说整体平均数,方差,整体比例等。)
变化,概率分布也产生变化。(参数即是描述整体特征的一种概率性数字度量,比如说整体平均数,方差,整体比例等。)

特征函数与概率密度函数有一对一的关系。因此知道一个分布的特征函数就等同于知道一个分布的概率密度函数。
二、最大似然估计
给定一个概率分布 ,假定其概率密度函数(连续分布)或概率质量函数(离散分布)为
,假定其概率密度函数(连续分布)或概率质量函数(离散分布)为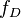 ,以及一个分布参数
,以及一个分布参数 ,我们可以从这个分布中抽出一个具有
,我们可以从这个分布中抽出一个具有 个值的采样
个值的采样 ,通过利用,我们就能计算出其概率:
,通过利用,我们就能计算出其概率:
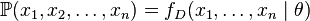
但是,我们可能不知道的值,尽管我们知道这些采样数据来自于分布。那么我们如何才能估计出呢?一个自然的想法是从这个分布中抽出一个具有个值的采样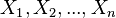 ,然后用这些采样数据来估计.一旦我们获得,我们就能从中找到一个关于的估计。最大似然估计会寻找关于的最可能的值(即,在所有可能的取值中,寻找一个值使这个采样的“可能性”最大化)。
,然后用这些采样数据来估计.一旦我们获得,我们就能从中找到一个关于的估计。最大似然估计会寻找关于的最可能的值(即,在所有可能的取值中,寻找一个值使这个采样的“可能性”最大化)。
要在数学上实现最大似然估计法,我们首先要定义似然函数:
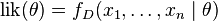
并且在的所有取值上,使这个函数最大化(一阶导数)。这个使可能性最大的 值即被称为的最大似然估计。
值即被称为的最大似然估计。
一个离散分布、离散有限参数空间分布的例子:
考虑一个抛硬币的例子。假设这个硬币正面跟反面轻重不同。我们把这个硬币抛80次(即,我们获取一个采样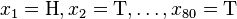 并把正面的次数记下来,正面记为H,反面记为T)。并把抛出一个正面的概率记为
并把正面的次数记下来,正面记为H,反面记为T)。并把抛出一个正面的概率记为 ,抛出一个反面的概率记为
,抛出一个反面的概率记为 (因此,这里的即相当于上边的)。假设我们抛出了49个正面,31个反面,即49次H,31次T。假设这个硬币是我们从一个装了三个硬币的盒子里头取出的。这三个硬币抛出正面的概率分别为
(因此,这里的即相当于上边的)。假设我们抛出了49个正面,31个反面,即49次H,31次T。假设这个硬币是我们从一个装了三个硬币的盒子里头取出的。这三个硬币抛出正面的概率分别为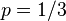 ,
, 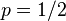 ,
,  .这些硬币没有标记,所以我们无法知道哪个是哪个。使用最大似然估计,通过这些试验数据(即采样数据),我们可以计算出哪个硬币的可能性最大。这个似然函数取以下三个值中的一个:
.这些硬币没有标记,所以我们无法知道哪个是哪个。使用最大似然估计,通过这些试验数据(即采样数据),我们可以计算出哪个硬币的可能性最大。这个似然函数取以下三个值中的一个:
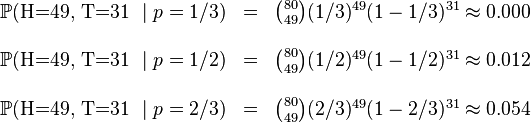
我们可以看到当 时,似然函数取得最大值。这就是的最大似然估计。
时,似然函数取得最大值。这就是的最大似然估计。
现在假设例子1中的盒子中有无数个硬币,对于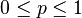 中的任何一个,
中的任何一个,
都有一个抛出正面概率为的硬币对应,我们来求其似然函数的最大值:
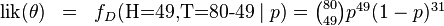
其中. 我们可以使用微分法来求最值。方程两边同时对取微分,并使其为零。
![\begin{matrix}0 & = & \frac{d}{dp} \left( \binom{80}{49} p^{49}(1-p)^{31} \right) \\ & & \\ & \propto & 49p^{48}(1-p)^{31} - 31p^{49}(1-p)^{30} \\ & & \\ & = & p^{48}(1-p)^{30}\left[ 49(1-p) - 31p \right] \\\end{matrix}](http://upload.wikimedia.org/math/f/4/3/f43c984e21445732edf403445fe32ea9.png)
其解为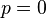 ,
, 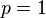 ,以及
,以及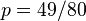 .使可能性最大的解显然是(因为和这两个解会使可能性为零)。因此我们说最大似然估计值为
.使可能性最大的解显然是(因为和这两个解会使可能性为零)。因此我们说最大似然估计值为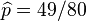 .
.
三、贝叶斯定理
贝叶斯定理是关于随机事件A和B的条件概率的一则定理。
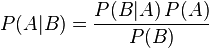
其中P(A|B)是在B发生的情况下A发生的可能性。
在贝叶斯定理中,每个名词都有约定俗成的名称:
- P(A)是A的先验概率,之所以称为"先验"是因为它不考虑任何B方面的因素。
- P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。
- P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
- P(B)是B的先验概率,也作标准化常量(normalized
constant). -
一个例子
贝叶斯定理在检测吸毒者时很有用。假设一个常规的检测结果的敏感度与可靠度均为99%,也就是说,当被检者吸毒时,每次检测呈阳性(+)的概率为99%。而被检者不吸毒时,每次检测呈阴性(-)的概率为99%。从检测结果的概率来看,检测结果是比较准确的,但是贝叶斯定理却可以揭示一个潜在的问题。假设某公司将对其全体雇员进行一次鸦片吸食情况的检测,已知0.5%的雇员吸毒。我们想知道,每位医学检测呈阳性的雇员吸毒的概率有多高?令“D”为雇员吸毒事件,“N”为雇员不吸毒事件,“+”为检测呈阳性事件。可得
- P(D)代表雇员吸毒的概率,不考虑其他情况,该值为0.005。因为公司的预先统计表明该公司的雇员中有0.5%的人吸食毒品,所以这个值就是D的先验概率。
- P(N)代表雇员不吸毒的概率,显然,该值为0.995,也就是1-P(D)。
- P(+|D)代表吸毒者阳性检出率,这是一个条件概率,由于阳性检测准确性是99%,因此该值为0.99。
- P(+|N)代表不吸毒者阳性检出率,也就是出错检测的概率,该值为0.01,因为对于不吸毒者,其检测为阴性的概率为99%,因此,其被误检测成阳性的概率为1-99%。
- P(+)代表不考虑其他因素的影响的阳性检出率。该值为0.0149或者1.49%。我们可以通过全概率公式计算得到:此概率 = 吸毒者阳性检出率(0.5% x 99% = 0.495%)+ 不吸毒者阳性检出率(99.5% x 1% = 0.995%)。P(+)=0.0149是检测呈阳性的先验概率。用数学公式描述为:
根据上述描述,我们可以计算某人检测呈阳性时确实吸毒的条件概率P(D|+):
尽管我们的检测结果可靠性很高,但是只能得出如下结论:如果某人检测呈阳性,那么此人是吸毒的概率只有大约33%,也就是说此人不吸毒的可能性比较大。我们测试的条件(本例中指D,雇员吸毒)越难发生,发生误判的可能性越大。

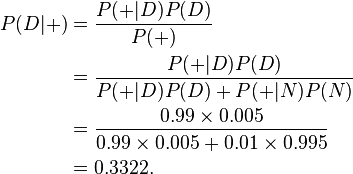
四、最大后验概率
最大后验估计可以看作是规则化(regularization)的最大似然估计。由于篇幅有限,见下一篇文章。