今天看到这篇文章只能连声赞好,只能说我们广大程序员为了用户真的是无所不用其极啊!学习是用无止境的!!!
本文主要讲解如何利用 HTML5 的 localstorage 和增量更新算法实现 JavaScript 的本地化,并在版本更新的时候基本做到修改多少内容就下载多少内容,为网站和用户节省 90%以上的 JavaScript 流量,尤其适合快速迭代开发的手机网站使用。
前言
随着 web 前端技术的发展,目前的 JavaScript 的能力越来越强,它在 web 端的能力越来越强,已经可以用来做一些以前没法做的事情了。本文讲的是通过 JavaScript 自己来实现资源文件的本地存储和增量更新方案的设计和实现。
传统的 JavaScript 资源加载方式的缺点
传统的 JavaScript 资源存放方式一般就是通过 CDN 方式存放,缓存方面通过增加 maxage、Last-Modified,etag 等方式依靠 HTTP Cache 相关协议进行缓存。这种方式的问题主要是缓存命中率不是很高,另外在快速迭代的产品中,由于代码经常需要修改,虽然很多时候只是修改很小的一部分内容,但是还是需要用户全量下载整个 JavaScript 文件,造成流量上的耗费。
HTML5 appcache JavaScript 资源加载方式的优缺点
除了传统方式的存放和加载 JavaScript,HTML5 给我们提供了另一种 JavaScript 资源缓存的方式,即 HTML5 的离线存储或 application cache.通过给 manifest 头文件定义资源的本地存放方式,我们可以完全实现静态数据本地存储,减少了大量网络请求,减少网络流量。但是这种方式同时也有他致命的缺点:
1.appcache 机制定义了在更新离线存储版本的时候,用户的首次进入页面并不会启用最新的资源文件,而是由一个后台程序先把资源下载到本地,用户需要刷新或者再次进入页面时才会启用新的资源文件,当然这个问题可以通过监听离线缓存的更新完成时间,在更新完成的时候程序去刷新页面以启用新的静态资源,但是这个方式带来了一个致命的不佳的用户体验,就是用户进来后会看到浏览器自己刷新了一下页面,对一些网站来说这显然不能接受。
2.对于引入了离线存储的页面,是没有办法去掉离线存储的,这给一些首页是动态页面的网站造成了极大的困扰。一些灰度发布的策略无法很好的实施。
用 localstorage 来存储 JavaScript
针对 appcache 的一些致命问题,我们决定找到一个东西来存储 JavaScript,而不走 appcache 以避免它的一些问题。localstorage 是一个浏览器端的 key-value 型数据库,可以通过相关的 JavaScript API 来进行操作,标准的 localstorage 可以存放 5m 的数据,对于一般的网站来说用来存 JavaScript 肯定是足够了。于是我们载入 JavaScript 的流程变为比较的上次更新的版本号(可以存入本地存储)和本次更新的版本号(可以是一个 JavaScript
变量写在页面上),如果不一致用 Ajax 去服务器拉取最新的内容并通过 eval 解释执行 JavaScript,然后存入本地存储;如果一致则直接从本地存储读取 JavaScript 内容并 eval 解释执行。代码大概如清单 1 所示。
清单 1.使用本地存储 JavaScript 并用 eval 来解释 JavaScript
到这里我们基本可以实现用本地存储来代替离线存储,从而避免离线存储的一些致命问题。
JavaScript 增量更新算法设计
用 localstorage 来存储 JavaScript 文件我们已经减少了很多不必要的 304 http 请求,但是对于版本更新的时候,我们还是必须全量下载整个 js 文件。然而大多数在快速迭代开发的网站中,我们修改 JavaScript 往往只是修改很少的一部分内容,这就造成了大部分 JavaScript 数据的下载是浪费的,接下来我们将设计一个算法来解决这个问题。
首先通过 localstorage 我们能获取上一个版本的 JavaScript 内容,那么只要我们通过一种办法计算出来我们本次更新在原有的 JavaScript 内容上什么位置更新了什么内容,那么我们就可以根据这个数据和 JavaScript 上个版本的数据合并生成一个新版本的 JavaScript 文件。
先来看下整个增量更新的流程:
- 先将旧文件按一定长度分成多个块,计算 md5 值放入一个 map,如图 1 所示
图 1.旧文件按照一定长度切分并编号

- 在新文件上进行滚动 md5 查找,如果找到匹配的则记录块号,如果没找到则块往前移动 1 个字符,并把上个字符压入新数据块,然后扫描下一块,最终得到一个新数据和数据块号的组合的增量文件(这一步可以用上线 JavaScript 时用的打包工具或者请求 JavaScript 时用服务器程序实时计算出来)如图 2 所示
图 2.新文件滚动查找后由旧数据块号和新更新数据组成

最终增量文件表示如下:
进一步合并顺序块得到:
- 客户端根据旧文件的 chunk 数据和第二部生成的增量更新数据,我们可以得出新版本数据由如下数据组成:
以 s=’12345678abcdefghijklmnopq’ 修改为 a=’123456f78abcd2efghijklmnopq’ 为例。
设块长度为 4 则,源文件可分割为如下 chunk 数据(第一行块号,第二行数据),如图 3 所示:
图 3.实例旧文件块号及块内容

通过滚动查找比对,得到新的文件构成如图 4 所示:
图 4.实例新文件块号和新数据结构

最终增量文件表示如下数组:
进一步合并顺序块,可用一个 js 数组表示为
所以新数据为:
合并代码如清单 2 所示.
清单 2.合并代码函数
通过这个算法,我们可以基本达到修改哪些内容就下载哪些内容的目的,大大减少下载流量。
JavaScript 本地存储和增量更新 seajs 插件的实现
为了推广以上的算法,笔者用上边这个算法写了一个 seajs 插件 storeinc(https://github.com/luyongfugx/storeinc),seajs 用户通过使用这个插件结合为之编写的构建工具 spm-storeinc-build()就可以很容易的集成本地存储和增量更新功能,下面我们通过一个例子来展示一下如何使用这个插件.这个例子通过修改 seajs 官方 examples 的 hello 例子来引入 storeinc.到 https://github.com/luyongfugx/storeinc/tree/master/
把里面的 demo 目录下载到自己的 web 服务器。 打开 sea-moudles/seajs/seajs/2.1.1/目录,我们发现里面有个 plugin-storeinc.js,这正是 storeinc seajs 插件本身.打开 app 目录下的 hello.html,里面已经嵌入了 storeinc 插件如清单 3 所示
清单 3. 嵌入 storeinc 代码
并且通过清单 4 的代码启用了本地存储和增量更新插件
清单 4.启用 storeinc 插件
接下来安装构建工具 spm-storeinc-build
npm install spm-storeinc-build -g
然后到 static/hello 目录下修改 package.json 构建配置文件为清单 5 所示内容
清单 5. 构建配置文件内容
然后在该目录下运行 spm-storeinc-build 构建工具下会在 dist 目录下生成混淆后的 js 文件.如图 5 所示:
图 5.使用构建工具构建代码后的文件

然后我们将 1.0.6 文件夹放到,sea-modules\examples\hello 文件夹下(js 资源从这个目录拉取)
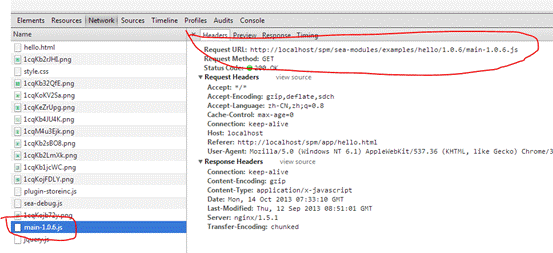
启动 web 服务器,在浏览器输入 http://localhost/spm/app/hello.html ,访问正常,看一下网络请求,由于是第一次访问所以,看到 js 访问了 main-1.0.6.js 这个文件,如图 6 所示
图 6. 1.0.6 版本 js 第一次访问时的 http 请求截图
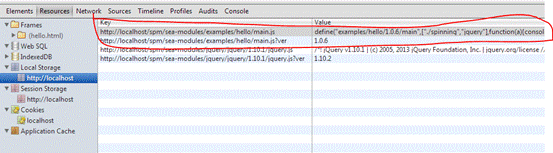
另外看一下 localstorage,已经把这个文件内容和版本号存入了本地存储,如图 7 所示
图 7 1.0.6 版本 js 第一次访问时的本地存储内容截图
再刷新一次,已经不会有 main-1.0.6.js 这个请求,但是功能 ok,说明程序是从本地存储读取 js 内容的,较少了网络请求,加快了速度并减少了流量
接下来看下增量更新,我们分别修改 static\hello\src 目录下的 main.js 和 spinning.js
在 main.js 和 spinning.js 里面修改几个 console.log 的日志输出修改原来的 1.0.6 为 1.0.7
分别如图 8,图 9 所示
图 8. 1.0.7 main.js 修改内容截图

图 9 1.0.7 spinning.js 修改内容截图

然后修改 package.json,把版本修改为 1.0.7,把上个版本修改为 1.0.6 如图 10 所示:
图 10. 1.0.7 打包 package.json 版本信息内容

然后执行 spm-storeinc-build 命令进行构建,这时候发现在 dist 目录下生成了一个 1.0.7 目录,如图 11 所示。
图 11. 1.0.7 版本 js 构建后的文件列表
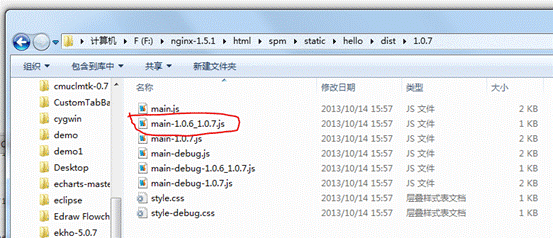
发现多了一个 main-1.0.6_1.0.7.js 的 JavaScript 文件这个文件就是传说中的增量文件了,就是说这个文件的内容是 main.js 从 1.0.6 变化到 1.0.7 所修改的内容,我们打开文件可以看到如图 12 所示内容
图 12. 增量文件 main-1.0.6_1.0.7.js 内容

发现这里只有刚才修改的 JavaScript 的更新内容,然后我们将 1.0.7 文件夹放到,sea-modules\examples\hello 文件夹下,并修改\app\hello.html 把版本改为 1.0.7,然后重新访问
http://localhost/spm/app/hello.html ,这时候发现浏览器访问的是 main-1.0.6_1.0.7.js 这个增量文件,如图 13 所示
图 13. 1.0.7 版 js http 请求截图

整个页面功能也都 ok,在看看 console 平台,发现我们刚才的修改已经生效,console 打出了 1.0.7 版本的相关信息,如图 13 所示
图 13. 1.0.7 版 js 的 console 输出截图
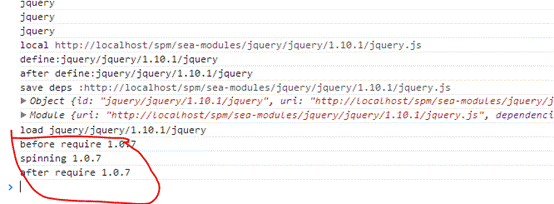
说明增量更新已经生效,浏览器以最小的流量损耗是想了一次 JavaScript 版本更新,以这个 demon 为例,如果走普通的版本更新方式,需要全两下载 main.js,需要下载一个 2k 的文件,而走增量更新则只需要下载 0.5k 左右的文件,流量大大节省!
增量文件 servlet 代理的实现
上面这个例子,增量文件的生成是通过 spm-storeinc-build 来离线生成的。我们这里在介绍一下通过 java servlet 来动态生成增量更新。原理就是通过前台过来的请求获取本次和上次版本号,然后 servlet(源代码可以看下载包里的 StoreIncServlet)通过比较两个版本 js 之间的不同生成增量更新文件,并返回给浏览器端。具体的代码可以在附件或者 https://github.com/luyongfugx/storeinc 获得,这里就不详细讲了。
容错处理
增量更新功能依赖于 localstorage,对于不支持本地存储的浏览器,storeinc 会自动切换到全量更新模式,所以不会造成使用上的问题,但是不支持本地存储的浏览器将无法增量更新。
由于增量更新跟传输协议无关,所以无论是 HTTP 还是 HTTPS 都可以使用。
总结
到此为止,通过本地存储,我们在不更新版本的时候基本上消灭了 JavaScript 相关的 HTTP 请求,在版本更新的时候也基本上做到了修改什么内容就更新什么内容。为 web 程序节省了 90%以上的 JavaScript 流量耗费!
- 客户端根据旧文件的 chunk 数据和第二部生成的增量更新数据,我们可以得出新版本数据由如下数据组成: