这个采集器原型来自于 《Discuz!NT论坛超级采集器普及版》http://nt.discuz.net/showtopic-46542.html,感谢原作者!
使用说明:
1. 将运行程序中的文件拷贝到对应目录中
2. 在web.config中<configuration>下添加
<connectionStrings>
<add name="DuoeAccessCon" connectionString="Provider=Microsoft.Jet.OLEDB.4.0;Data Source={0}\plugin\RemoteContentRubber\getfile.config;User Id=admin;Password=;"/>
<add name="DuoeRubberTime" connectionString="00:00:01" />
</connectionStrings>
<add name="DuoeAccessCon" connectionString="Provider=Microsoft.Jet.OLEDB.4.0;Data Source={0}\plugin\RemoteContentRubber\getfile.config;User Id=admin;Password=;"/>
<add name="DuoeRubberTime" connectionString="00:00:01" />
</connectionStrings>
其中DuoeAccessCon是连接字符串,采用相对于虚拟目录路径;DuoeRubberTime为采集间隔时间,时间应该保证类似00:00:00(小时:分钟:秒钟)的格式.
3. 在系统后台管理增加管理链接
../plugin/RemoteContentRubber/GetFile.aspx
4.请求http://网址/plugin/ RemoteContentRubber/GetFile.aspx可以打开采集界面
5.自动采集的日志在虚拟目录根目录servicelog.txt
下面是一些截图:
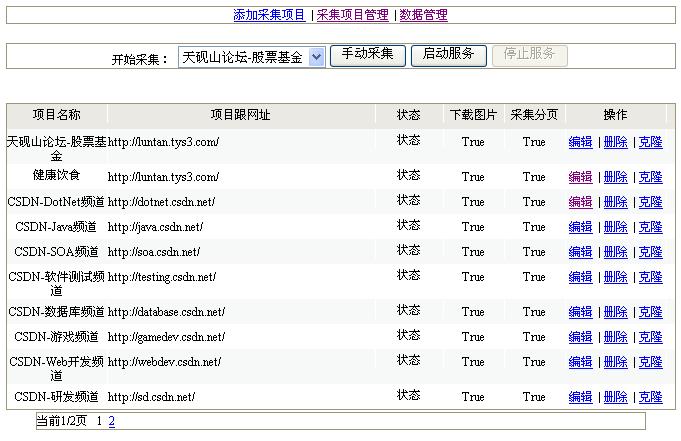


下载地址:http://files.cnblogs.com/zjoch/RemoteContentRubber_dnt2.5.rar
csdn下载:http://download.csdn.net/source/1304679
来源地址:http://www.cnblogs.com/zjoch/archive/2008/08/13/1266461.html