首先来看一些基础知道再看看CLR是怎么工作的,看下图:
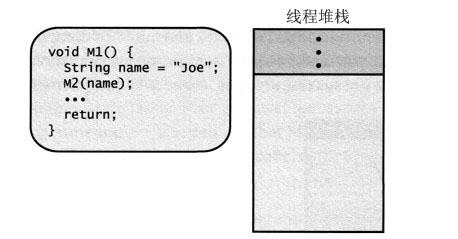
当CLR开始加载一个Microsoft Windows进程,在这个进程中可能存在多个线程,当一个线程创建时,它会分配到一个1M大小的堆栈,这个堆栈空间用于向方法传递实参,并用于存储方法内部定义的局部变量,上图展示了一个线程的堆栈内存(右侧)。堆栈是从高位内存地址向低位内存地址构建的,在图中,该纯种执行了一 些代码,它的堆栈上已经有一些数据(显示成堆栈顶部的阴影区域),现在假定线程执行的代码要调用M1方法。
在一个最基本的方法中,应该包含一结“开场白(prologue)”代码,它们负责在方法开始做它的工作前对其进行初始化,还应该包含一结“收场白(epilogue)”代码,它们负责在方法完成工作后对其进行清理,以便返回给调用者。当M1开始执行时,它的“开场白”代码从线程的堆栈中为局部变量name分配内存,如下图:
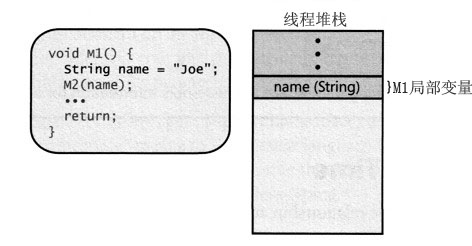
然后,M1调用M2,将局部变量name作为一个实例来传递,这造成name局部变量中的地址被压入堆栈,如下图:

M2开始执行时,它的“开场白”代码从线程堆栈中为局部变量length和tally分配内存,如下图所示:
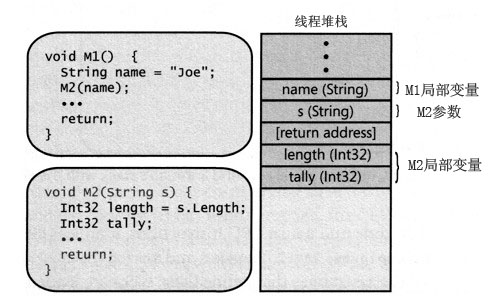
然后开始执行M2方法内部的代码。最终,M2会抵达它的return语句,这会造成CPU的指令指针被设置成堆栈中的返回地址,而且M2的堆栈帧会进行辗转开解(unwind),使之看起来类似于上面第二个图,之后,M1将继续执行在M2调用之后的代码,M1的堆栈帧将准确的反映M1需要的状态。
最终M1会返回到它的调用者,这同样是通过将CUP指令指针设计成返回地址来实现的,而且M1的堆栈帧会进行辗转开解,使之看起来类似于上面第一个图,之后,调用了M1的方法会继续执行在M1调用之后的代码,那个方法的堆栈帧将准确的反映它需要的状态。