代码太多,编辑的时候卡的很,于是再整个(二)
前面贴完了分类器的代码,下面主程序如下(示例仍然采用原文的例子):







 }
} }
}
运行后结果如下:
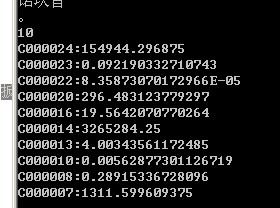
其中,样本数据同样采用搜狗实验室的mini版本,共10个分类,
冒号前是分类编码,冒号后面是概率结果。
分类编码和分类名称对应如下:
C000007 汽车
C000008 财经
C000010 IT
C000013 健康
C000014 体育
C000016 旅游
C000020 教育
C000022 招聘
C000023 文化
C000024 军事
C000008 财经
C000010 IT
C000013 健康
C000014 体育
C000016 旅游
C000020 教育
C000022 招聘
C000023 文化
C000024 军事
因此,测试数据归到 体育 分类下。
在原来的贴来的分词器中,还对停用词进行了过滤,由于ICTCLAS分词器内置了停用词过滤,因此我对原文代码中的相关代码进行了调整。
ICTCLAS分词器对停顿词的过滤代码(见本文(一)中的ICTCLAS中文分词for Lucene.Net接口代码(实现Analyzer)):
其原理也是基于词典的过滤,字典目录的指定见本文(一)中的ICTCLAS中文分词for Lucene.Net接口代码(实现Analyzer))。
打开\data\文件夹下的stopwords.txt,可见:

这里面是一些常用停顿词。
还没有对批量数据进行分类测试,稍后贴出测试结果和代码下载。