一、概念
索引是为了加速对表中数据行的检索而创建的一种分散存储结构。
1、索引是针对表而建立的;
2、索引由除存放表的数据页面以外的索引页面组成,也就是说索引需要单独的存储空间。
二、索引的分类
索引分为两类:聚簇索引和非聚簇索引。
聚簇索引的结构如下图所示:
索引是为了加速对表中数据行的检索而创建的一种分散存储结构。
1、索引是针对表而建立的;
2、索引由除存放表的数据页面以外的索引页面组成,也就是说索引需要单独的存储空间。
二、索引的分类
索引分为两类:聚簇索引和非聚簇索引。
聚簇索引的结构如下图所示:
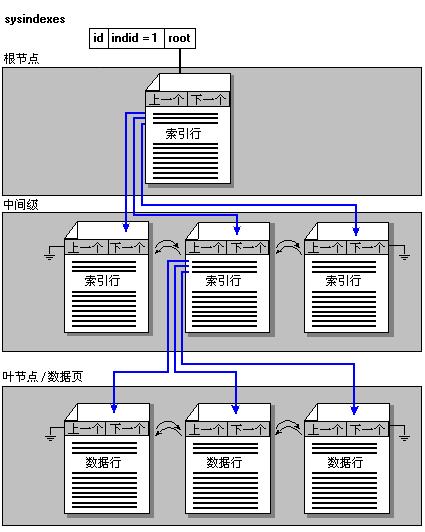
上图中,“根节点”与“中间级”统称为“索引页”,也叫做“非叶级”。根节点存放着中间级每一个页面的第一个元素。中间级存放这数据页每一个页面的第一个元素。
非聚簇索引的结构如下图所示: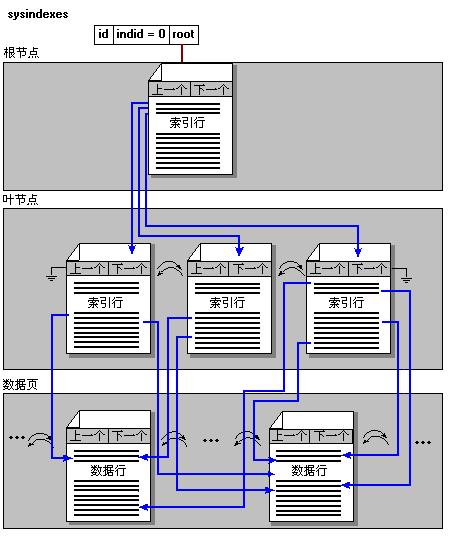
上图中,根节点存放着中间级每一个页面的第一个元素。但是,中间级存放这数据页并不是每一个页面的第一个元素,而是在中间级维护一张类似哈希表的结构。
两种索引的比较:
1、在聚簇索引中,表的数据是按照索引顺序排列的;而在非聚簇索引中,表的物理顺序与索引顺序不同,也就是说表的数据并不是按照索引列排序。
2、每张表只能有一个聚簇索引,并应该是第一个建立;而每张表的非聚簇索引可以达到294。
3、这两种索引的中间级元素都是顺序排列的。
三、索引如何加速查询
从概念中知道索引的一个特点是加速对表中数据行的检索,那么它是如何加速的呢?
索引类似于书的目录或附录,我们通过找书目录中的页号可以直接定位到书的内容,索引也就是建立了到达数据的直接路径。(注:sql server 的查询优化器依赖于索引起作用)